使用情景
手机实现语音识别
效果展示

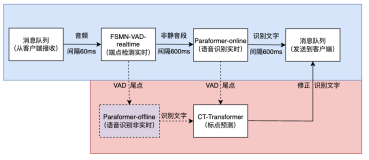
原理
使用讯飞webpai调用讯飞的语音转写服务
难点
上传语音文件
你将学到以下知识
- 给讯飞发送语音文件
- 分片序号的生成
- 计算签名
- HmacSHA1加密
- 10位时间戳, 不要科学记数法
- 另类的文件上传方式
代码讲解
- 导入java类
importClass(java.io.UnsupportedEncodingException); importClass(java.security.InvalidKeyException); importClass(java.security.MessageDigest); importClass(java.security.NoSuchAlgorithmException); importClass(java.security.SignatureException); importClass(javax.crypto.Mac); importClass(javax.crypto.spec.SecretKeySpec);
- 初始化所有的参数,
APPID和SECRET_KEY请改为自己的.
const APPID = "XXX"; const SECRET_KEY = "XXX"; let filepath = "/sdcard/1.mp3"; let lfasr_host = "http://raasr.xfyun.cn/api"; // # 请求的接口名 let api_prepare = "/prepare"; let api_upload = "/upload"; let api_merge = "/merge"; let api_get_progress = "/getProgress"; let api_get_result = "/getResult";
- 预处理
const taskId = prepare();
- 文件分片上传
upload();
- 合并文件
merge();
- 查询处理进度
for (var i = 0; i < 10; i++) { let r = getProgress(); if (r) { break; } else { log("服务器正常按照排队识别语音, 请稍后"); } sleep(5000); }
- 获取结果
let result = getResult(); log(result);
签名计算过程
function HmacSHA1Encrypt(encryptText, encryptKey) { let rawHmac; encryptText = java.lang.String(encryptText); encryptKey = java.lang.String(encryptKey); let data = encryptKey.getBytes("UTF-8"); let secretKey = new SecretKeySpec(data, "HmacSHA1"); let mac = Mac.getInstance("HmacSHA1"); mac.init(secretKey); let text = encryptText.getBytes("UTF-8"); rawHmac = mac.doFinal(text); let oauth = android.util.Base64.encodeToString(rawHmac, 2); return oauth; }
名人名言
思路是最重要的, 其他的百度, bing, stackoverflow, github, 安卓文档, autojs文档, 最后才是群里问问
--- 牙叔教程
声明
部分内容来自网络
本教程仅用于学习, 禁止用于其他用途