十一、合理利用分区:Partition
Partition 就是分区。分区通过在创建表时启用 partitioned by 实现,用来 partition 的维度并不 是实际数据的某一列,具体分区的标志是由插入内容时给定的。当要查询某一分区的内容时可以采用 where 语句,形似 where tablename.partition_column = a 来实现。
创建含分区的表:
CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User') PARTITIONED BY(date STRING, country STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '1' STORED AS TEXTFILE;
载入内容,并指定分区标志
load data local inpath '/home/hadoop/pv_2008-06-08_us.txt' into table page_view partition(date='2008-06-08', country='US');
查询指定标志的分区内容
SELECT page_views.* FROM page_views WHERE page_views.date >= '2008-03-01' AND page_views.date <= '2008-03-31' AND page_views.referrer_url like '%xyz.com';
十二、Join 优化
总体原则:
「1、 优先过滤后再进行 Join 操作,最大限度的减少参与 join 的数据量 2、 小表 join 大表,最好启动 mapjoin 3、 Join on 的条件相同的话,最好放入同一个 job,并且 join 表的排列顺序从小到大」
「在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边」。
原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x ON (u.userid = x.userid);
如果 Join 的 key 相同,不管有多少个表,都会合并为一个 Map-Reduce 任务,而不是”n”个,在做 OUTER JOIN 的时候也是一样。
如果 join 的条件不相同,比如:
INSERT OVERWRITE TABLE pv_users SELECT pv.pageid, u.age FROM page_view p JOIN user u ON (pv.userid = u.userid) JOIN newuser x on (u.age = x.age);
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的
--先 page_view 表和 user 表做链接 INSERT OVERWRITE TABLE tmptable SELECT * FROM page_view p JOIN user u ON (pv.userid = u.userid); -- 然后结果表 temptable 和 newuser 表做链接 INSERT OVERWRITE TABLE pv_users SELECT x.pageid, x.age FROM tmptable x JOIN newuser y ON (x.age = y.age);
在编写 Join 查询语句时,如果确定是由于 join 出现的数据倾斜,那么请做如下设置:
set hive.skewjoin.key=100000; // 这个是 join 的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.optimize.skewjoin=true; // 如果是 join 过程出现倾斜应该设置为 true
十三、Group By 优化
1、Map 端部分聚合
并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以先在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
MapReduce 的 combiner 组件参数包括:
set hive.map.aggr = true 是否在 Map 端进行聚合,默认为 True
set hive.groupby.mapaggr.checkinterval = 100000 在 Map 端进行聚合操作的条目数目
2、使用 Group By 有数据倾斜的时候进行负载均衡
「set hive.groupby.skewindata = true」
当 sql 语句使用 groupby 时数据出现倾斜时,如果该变量设置为 true,那么 Hive 会自动进行 负载均衡。「策略就是把 MR 任务拆分成两个:第一个先做预汇总,第二个再做最终汇总」。
在 MR 的第一个阶段中,Map 的输出结果集合会缓存到 maptaks 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同 Group By Key 有可能被分发到不同的 Reduce 中, 从而达到负载均衡的目的;第二个阶段 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成 最终的聚合操作。
十四、合理利用文件存储格式
创建表时,尽量使用 orc、parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive 查询时会只遍历需要列数据,大大减少处理的数据量。
十五、本地模式执行 MapReduce
Hive 在集群上查询时,默认是在集群上 N 台机器上运行, 需要多个机器进行协调运行,这个方式很好地解决了大数据量的查询问题。但是当 Hive 查询处理的数据量比较小时,其实没有必要启动分布式模式去执行,因为以分布式方式执行就涉及到跨网络传输、多节点协调 等,并且消耗资源。这个时间可以只使用本地模式来执行 mapreduce job,只在一台机器上 执行,速度会很快。启动本地模式涉及到三个参数:

set hive.exec.mode.local.auto=true 是打开 Hive 自动判断是否启动本地模式的开关,但是只 是打开这个参数并不能保证启动本地模式,要当 map 任务数不超过
hive.exec.mode.local.auto.input.files.max 的个数并且 map 输入文件大小不超过
hive.exec.mode.local.auto.inputbytes.max 所指定的大小时,才能启动本地模式。
十六、并行化处理
一个 Hive SQL 语句可能会转为多个 mapreduce Job,每一个 job 就是一个 stage,这些 job 顺序 执行,这个在 cli 的运行日志中也可以看到。但是有时候这些任务之间并不是是相互依赖的, 如果集群资源允许的话,可以让多个并不相互依赖 stage 并发执行,这样就节约了时间,提 高了执行速度,但是如果集群资源匮乏时,启用并行化反倒是会导致各个 job 相互抢占资源 而导致整体执行性能的下降。启用并行化:
「set hive.exec.parallel=true; set hive.exec.parallel.thread.number=8; // 同一个 sql 允许并行任务的最大线程数」
十七、设置压缩存储
1、压缩的原因
Hive 最终是转为 MapReduce 程序来执行的,而 MapReduce 的性能瓶颈在于网络 IO 和 磁盘 IO,要解决性能瓶颈,最主要的是减少数据量,对数据进行压缩是个好的方式。
压缩虽然是减少了数据量,但是压缩过程要消耗 CPU 的,但是在 Hadoop 中, 往往性能瓶颈不在于 CPU,CPU 压力并不大,所以压缩充分利用了比较空闲的 CPU。
2、常用压缩方法对比
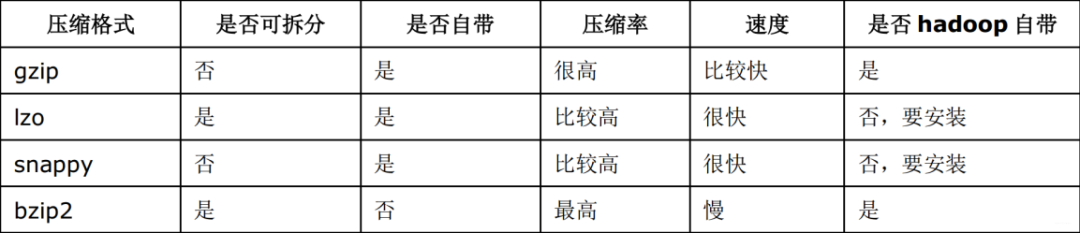
各个压缩方式所对应的 Class 类:

3、压缩方式的选择
压缩比率
压缩解压缩速度
是否支持 Split
4、压缩使用
「Job 输出文件按照 block 以 GZip 的方式进行压缩:」
set mapreduce.output.fileoutputformat.compress=true // 默认值是 false set mapreduce.output.fileoutputformat.compress.type=BLOCK // 默认值是 Record set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
「Map 输出结果也以 Gzip 进行压缩:」
set mapred.map.output.compress=true set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec // 默认值是 org.apache.hadoop.io.compress.DefaultCodec
「对 Hive 输出结果和中间都进行压缩:」
set hive.exec.compress.output=true // 默认值是 false,不压缩 set hive.exec.compress.intermediate=true // 默认值是 false,为 true 时 MR 设置的压缩才启用

