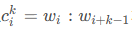ACL会议(Annual Meeting of the Association for Computational Linguistics)是由计算语言协会主办的自然语言处理与计算语言学领域最高级别学术会议。
自然语言处理是人工智能领域中的重要方向之一,被誉为人工智能皇冠上的“明珠”。当前深度学习、图计算等方法被广泛应用于各种自然语言处理任务,并取得不错的研究成果,但在工业级应用中也面临着全新的挑战。
本文整理自2022 ACL会议论文MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction,介绍了一种新的关键词提取方法及其更适配的预训练模型。
/本文作者/
张琳涵,陈谦,王雯,邓憧,张仕良,李冰,王炜,曹欣
关键词提取 (Keyphrase Extraction,KPE) 任务可以自动提取文档中能够概括核心内容的短语,有利于下游信息检索和 NLP 任务。
当前,由于对文档进行标注需要耗费大量资源且缺乏大规模的关键词提取数据集,无监督的关键词提取在实际应用中更为广泛。
无监督关键词抽取的state of the art(SOTA)方法是对候选词和文档标识之间的相似度进行排序来选择关键词。但由于候选词和文档序列长度之间的差异导致了关键短语候选和文档的表征不匹配,导致以往的方法在长文档上的性能不佳,无法充分利用预训练模型的上下文信息对短语构建表征。
在这项工作中,我们提出了一种新的基于无监督嵌入的关键词提取方法,即 MDERank。MDERank 通过利用掩码生成覆盖了候选词的文章,利用预训练模型得到掩码文档及其原始文档的表征,对其进行相似度计算,利用相似度分数对候选词进行排名来同时解决这两个问题。
此外,我们还利用自监督对比学习方法提出一种新颖的面向 KPE 的 BERT (KPEBERT) 模型进一步提升了关键词提取的性能,该方法比普通 BERT 更兼容 MDERank。我们在六个 KPE 基准上进行实验,综合评估结果表明提出的 MDERank 显著优于最先进的无监督 KPE 方法,F1@15平均提高了1.80。与此同时,MDERank 进一步受益于 KPEBERT,总体上比 SOTA SIFRank 平均提高了3.53 F1@15。
|| 方法
(一) 基于掩码的无监督关键词提取(MDERank)1.问题定义:给定一个文档 d = {W1, W2, ..., Wn},d ∈ D,D是数据集。根据对文章进行 POS 标注然后依据给定的规则( < NN.* |JJ > * < NN.* >,大部分为名词和形容词的组合)生成候选词集合 C = {c1, ..., ci, ..., cm}, m ≤ n, 每个候选词ci 包含一到多个词语, 即 ci = {ci1, ..., cil}。关键词抽取的目的是从候选集合 C 中选取 K 个词作为关键词, 且 K ≤ m.
2.现有方法存在的问题:
1)先前的基于表征进行关键词提取的方法(Phrase-Document-based Method,PD-Method) [1,2], 大都采用计算文本表征与候选词表征之间的相似度,然后依据相似度分数对候选词进行排序,相似度高的候选会被选取为关键词。然而这类方法忽视了文档长度与候选短语长度不匹配的问题,导致在进行关键词选取的时候存在偏向选取长关键词的问题。如Table 1所示,这个例子表明PD-Method偏向于较长的候选词,而我们提出的新方法MDERank没有这个问题。


2)PD-Method 使用的候选词表征,由于缺乏上下文信息,导致表征的质量不高,从而影响了后续的相似度计算,降低了关键词抽取的准确度。
3.我们提出的方法:
关键词是指能代表文本主旨的词或短语,因此在对整个文本的语义而言至关重要。如果一个文本的关键词被覆盖,则被覆盖的文本与原始的文本的语义差距会变大。基于这个想法,我们提出了基于掩码的无监督关键词提取技术 MDERank,通过比较覆盖住候选词的文本与原始文本的相似度,从而对候选词集合进行打分,实现文本的关键词提取,由原先的短语-文本层面的相似度计算通过掩码转换为文本-文本层面,从而解决了长度不匹配的问题。与此同时,我们避免了使用短语的表征,而是使用掩码后的文本替代候选词,由此可以获得充分利用了上下文信息的文本表征。具体实现方法如 Figure 1所示:


Figure 1:MDERank的算法流程图
- 我们利用之前提到的提取候选词的方法,对数据集中的每一篇文档都提取其对应的候选词集合。
- 我们遍历每个文档对应的候选词集合,把每个候选词 ci 在文中出现的所有位置 [p1, p2, ..., pt] 全部使用 [MASK] 替换。值得注意的是,经过分词后,一个候选词会有多个分词,我们替换的候选词的所有分词(Span Mask)。经过掩码后,我们可以获得每个候选词对应的掩码后的文本dMci。
- 我们定义用于排序的 cosine similarity 为相似度分数 f(ci),我们使用 BERT 对文本进行编码,使用 MaxPooling 获得文本表征 E(d) 和掩码后的文本表征 E(dMci) 从而计算 f(ci)。依据 MDERank 的定义,f(ci) 越高,ci 的排名越低,即被掩码后的文本损失的信息越多,掩码的候选词的重要性越高,这一点与 PD-method 相反,后者候选词的排名与 f(ci) 成正相关。
(二) 面向关键词提取的预训练模型(KPEBERT)
BERT[3] 及其诸多变种预训练模型 [4,5] 可以高效的对文本语义和结构进行编码,获得高质量的文本表征。但是现有的自监督模型没有显式的对关键词的重要性进行建模并且也没有对关键词之间的排序进行建模。因此在这篇论文中,我们提出了一种自监督学习方法来获得高质量的表征以提升 MDERank 对候选词的排序能力。
我们定义掩码伪关键词的文本为正例(伪关键词由现有的无监督关键词提取方法产生),掩码伪非关键词的文本为负例,将原始文本作为锚点,利用 triplet loss 拉近正例与原始文本之间的距离,拉远负例与原始文本之间的距离,如公式和Figure 2所示:

其中 λ 是一个用于平衡两个任务的超参数。
在进行正例和负例采样时,我们设计了两种采样方法:
1.绝对采样:利用现有的无监督关键词提取方法,对每篇文章抽取得到关键词集合,将这些“关键词”作为正例对原始文章进行掩码。然后在剩下候选词(“非关键词”)中随机抽取作为负例。
2.相对采样:利用现有的无监督关键词提取方法,对每篇文章抽取得到 d 关键词集合,在关键词集合中,随机抽取两个“关键词”,其中排名靠前的一个作为正例,另一个则为负例,从而构建训练数据。

|| 实验结果
#01 关键词提取任务
我们比较了 MDERank 在6个基准数据集上的表现,其中Inspec,SemEval2010,Semeval2017 为短文本数据集,DUC2001 为中长文本数据集,NUS 和 Krapivin 为长文本数据集。同先前工作,我们采用了 F1@K(K ∈ {5, 10, 15})作为评测指标。为了保证公平,我们对最后的结果进行了去重和 Stemming 操作。
为了公平比较 EmbedRank 模型与 MDERank 模型,我们使用 BERT 模型来替换 EmbedRank 的 Sent2Vec,从而定义了 EmbedRank(BERT)。根据 Table 3 我们可以看到,MDERank(BERT) 超过了 EmbedRank(BERT)[1] 平均 F1@152.95。同时,它还超过了先前的最优模型 SIFRank[12] 平均 F1@15 1.80。MDERank 还受益于 KPEBERT 获得的高质量, MDERank(KPEBERT) 相较于 SIFRank 实现了平均 F1@15 3.53 的提升。

值得注意的是,在长文本数据集上,MDERank显著优越于先前的方法。
#02 对文本长度的分析实验
我们使用 EmbedRank(BERT) 作为 PD-method 的代表,设计了两个实验来研究文本长度对 PD-method 和 MEDRank 的影响。
实验一,我们使用NUS数据集,通过对文本进行截断,获得128,256,512个词的文本作为输入,我们从 Table 5 中可以看到,随着文本长度的增加,PD-method 的性能逐渐下降,然而,MDERank 的性能受文本长度影响较小。
实验二,我们使用长文本建模模型 BigBird[4] 来替换BERT模型,以探究更长文本输入对不同方法的影响。通过 Table 7 可以看到,PD-method 在更长文本的数据上表现不佳,远差于MDERank的性能。
以上两个实验验证了MDERank在长文本关键词提取任务上的有效性。

#03 不同层和Pooling方法的分析实验
我们探究了使用了不同层和Pooling方法来获得文本表征对 PD-method 和 MDERank 的影响。根据表6所示,在不同的Pooling方法下,MDERank都随着层数的增长获得了一定性能的提升。然而在AvgPooling下,EmbedRank(BERT) 随着层数的增长性能急速下降。相较于AvgPooling,MaxPooling弱化了不同层之间的差异,因而 EmbedRank(BERT) 在MaxPooling下受层数变化影响较小。因此相较于 PD-Method,MDERank 更受益于强上下文语义表征。我们还比较了最优 EmbedRank(BERT)与MDERank 在6个数据集上的表现,平均 MDERank 比 EmbedRank(BERT)在F1@5,F1@10,F1@15上高3.7,1.8,1.6。

#04 不同无监督方法对KPEBERT的影响
我们探究了选取不同的无监督方法生成伪标签对 KPEBERT的 影响,如 Table 3 和 Table 8 所示,YAKE[6] 在6个基准数据集上平均表现不如 TextRank,但是在长文本数据集上性能优于 TextRank。使用了YAKE生成伪标签的 KPEBERT 效果优于 TextRank(Inspec较差,SemEval2017结果近似)。MDERank(KPEBERT)使用了YAKE在长短文本上的优越性能可以说明 KPEBERT 不仅保持了YAKE的稳定性能同时还对YAKE在短文本数据集低性能展现出了一定鲁棒性。

|| Future Work
我们提出了一种新的基于嵌入的无监督 KPE 方法 MDERank,与以前的基于嵌入的方法相比,它可以提高相似度匹配的可靠性。我们还提出了一种新颖的自监督学习方法,并开发了一种面向 KPE 的预训练语言模型,KPEBERT。
实验证明 MDERank 在不同数据集上的表现优于 SOTA,并进一步受益于 KPEBERT。分析进一步验证了 MDERank 对不同长度的关键短语和文档的鲁棒性,并且 MDERank 受益于更长的上下文和更强的嵌入模型。未来的工作包括通过优化采样策略和预训练方法来改进 MDERank 的 KPEBERT。
文章链接:
https://arxiv.org/pdf/2110.06651.pdf
https://openreview.net/forum?id=GzK8XG-3MvE
代码已在GitHub上开源:
https://github.com/LinhanZ/mderank
参考资料:
[1] Kamil Bennani-Smires, Claudiu Musat, Andreea Hoss- mann, Michael Baeriswyl, and Martin Jaggi. 2018. Simple unsupervised keyphrase extraction using sen- tence embeddings. In Proceedings of the 22nd Con- ference on Computational Natural Language Learn- ing, CoNLL 2018, Brussels, Belgium, October 31 - November 1, 2018, pages 221–229. Association for Computational Linguistics.
[2] Yi Sun, Hangping Qiu, Yu Zheng, Zhongwei Wang, and Chaoran Zhang. 2020. Sifrank: A new base- line for unsupervised keyphrase extraction based on pre-trained language model. IEEE Access, 8:10896– 10906.
[3] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: pre-training of deep bidirectional transformers for language under- standing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 4171–4186. Association for Computational Linguistics.
[4] Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago On- tañón, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: Trans- formers for longer sequences. In Advances in Neural Information Processing Systems 33: Annual Confer- ence on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
[5] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Pe- ter J. Liu. 2020. PEGASUS: pre-training with ex- tracted gap-sentences for abstractive summarization. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 of Proceedings of Machine Learning Research, pages 11328–11339. PMLR.
[6] Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Mário Jorge, Célia Nunes, and Adam Jatowt. 2018. Yake! collection-independent automatic key- word extractor. In Advances in Information Retrieval - 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26-29, 2018, Pro- ceedings, volume 10772 of Lecture Notes in Com- puter Science, pages 806–810. Springer.