一、文本分析
analysis(只是一个概念),文本分析是将全文本转换为一系列单词的过程,也叫分词。analysis是通过analyzer分词器来实现的,可以使用Elasticsearch内置的分词器,也可以自己去制定一些分词器。除了在数据写入的时候将词条进行转换,在查询的时候也可以指定分词器对语句进行分析。
analyzer由三部分组成。例如有
Hello a world ,the world is beautiful
:
- Character Filter :将文本中的html标签剔除掉。
- Tokenizer:按照规则进行分词,在英文中按照空格分词
- Token Filter: 去掉stop world(停顿词,a,an,the,is,are等),然后转换为小写
内置分词器

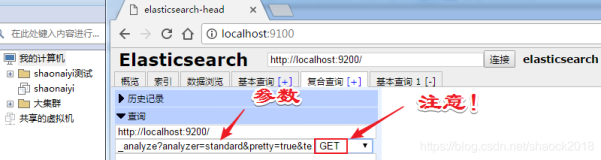
GET _analyze
{
"analyzer": "standard",
"text": "hello a world"
}
(一)分词器的安装
1.1 IK分词器
1.1.1下载
下载地址 https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.11.2
1.1.2安装
下载后是个zip包,上传到/usr/local/elasticsearch-7.11.2/plugins目录
#解压文件到ik文件夹
unzip elasticsearch-analysis-ik-7.11.2.zip -d ik
#重新修改文件的拥有者
chown -R es elasticsearch-7.11.2
#重新启动es
./bin/elasticsearch -d -p pid
1.1.3分词方式
ik分词器提供了两种分词方式
分词器名称 |
说明 |
ik_smart |
会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国”,“国歌”,适合phrase查询 |
ik_max_word |
会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、人、共和国、共和、国歌”,会穷尽各种可能组合,适合Term Query |
GET _analyze
{
"analyzer": "ik_max_word",
"text": "河南省郑州市"
}

1.1.4自定义词库
在很多时候,业务上的一些词库极有可能不再IK分词器的词库中,需要去定制属于我们自己的词库。特别是在一些行业领域,比如银行、金融、电力行业都有自己的特殊词库。比如下面的例子中,电能表、计量点点被切分为一个个的字,我们希望这两个词语不是被拆分;另外的作为中文的停顿词,也不希望出现在分词中,所以我们需要自定义词库和停顿词词库。
进入到$ES_HOME/plugins/ik/config目录下,创建custom目录,在目录下创建mydic.dic、ext_stopword.dic文件。
在文件中增加词条,如下图所示


修改IKAnalyzer.cfg.xml文件,把我们新增加的文件路径配置如下

查看配置过词条的结果,电能表和计量点不会再次被拆分

(二)分词器应用
2.1 新建索引
指定字段的被索引的分词器、查询时解析字段的分词器,并把自定义分词
PUT news
{"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"content":{
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
}
}
}
}
2.2动态修改索引数据
数据如果被索引以后,再动态增加自定义词条,检索临时增加的动态词条不生效,需要删除数据重新索引数据或动态修改索引数据。当需要索引的数据量较小时可以采用第一种方式,当数据量很大时,采用动态索引方式较好。
POST news/_update_by_query
{
"query":{
}
}
2.3动态增加自定义词条
动态增加自定义词条的原理是配置远程的扩展字典文件,修改远程的扩展字典文件达到动态增加自定义词条的目的。

我们借助nginx服务器,在nginx服务器上部署一个txt文档,文档部署成功后,在上述文件设置远程扩展地址URL

然后重启es服务,后续如果新增加自定义词条,可以修改此文件可以实现动态增加。