MAB问题
MAB是多臂老虎机(Multi-Armed Bandit)的缩写,MAB问题就是假设有个赌徒到赌场里面摇老虎机,赌场里面有10个老虎机,每个老虎机的赢钱概率是不一样的,此时他不知道每个老虎机的赢钱概率,而且他只有100个币,也就是说只能摇100次,如果他想最大化收益应该怎么摇?
MAB问题本质上是关于如何选择才能得到最大收益的问题,在推荐系统中有很多问题都可以当做MAB问题。例如广告推荐,假设网站上有一个广告位(赌场),此时广告系统有10个广告(老虎机),每天有100个人访问网站,也就是说就有100次展示广告的机会,用户点击了广告就认为是有收益,那么如何展示广告能够保证点击率最大?是每个广告轮流出?还是每次都随机出?
Bandit 算法
解决MAB问题有一系列算法,称为Bandit 算法。首先先来定义一下最大化的收益,我们每次摇老虎机都能得到收益,假设现在只有两个老虎机,摇了有收益记为1,没有收益记为0,老虎机A的收益概率是100%,老虎机B的收益概率是0%,那么摇100次的理论最大收益就是100块,但实际上我们并不知道那个老虎机的收益最大,所以实际上我们可能会摇60次A,40次B,那么收益就是60块,这称为累计收益。相比理论最大收益100,我们损失了40块,这40块就称为累计遗憾。单次遗憾就是理论最好收益减去当前选择的收益,例如第一次我们选择了老虎机A,得到收益是1,遗憾是1-1=0;第二次我们选择了老虎机B,得到的收益是0,遗憾就是1-0=1。
所以,Bandit算法的目标就是让遗憾最小化,遗憾越小收益越高,当遗憾为0时,我们就能拿到理论最大收益。 如果写成公式就是:累计遗憾=理论收益-累计收益。 理论收益就是每次都选择最好收益的情况下累计起来的收益,即上面说的100块。累计收益就是每次选择一个老虎机得到的收益累加起来的值,即上面说的60块。
Bandit算法的整体思路就是:通过探索不同的选择,在确定了某个选择好时就多选择它,确定某个选择差时就少选择它。
假设你是上面例子中说的赌徒,你会怎么赌?
- 第一种方式:每个老虎机都摇一次看看,如果有一个老虎机赚钱了,那就继续摇它,如果不赚钱了就换一个继续尝试。
- 第二种方式:每个老虎机摇五次,看哪个赚的钱最多,然后就一直摇那个赚钱最多的。
以上两种方式都有一个共同点,都是先试一下,然后做出选择决定下一次摇哪个。因为我们不知道老虎机的赢钱概率,所以要先试试看,也就是探索(explore)。等探索完了解老虎机的赢钱概率之后就开始做出选择,这一步称为利用(exploit)。
下面我们基于Bandit算法的基本思路具体讲解四种MAB算法以及它们之间的联系。
朴素贪心算法
先从最简单的开始讲起,朴素贪心算法的思路很简单,就是前面我们的例子中的第二种方式。具体来说就是:
- 对每个老虎机摇N次。(探索)
- 计算每个老虎机的赢钱概率,记赢钱次数为 $M_i$,那么每个老虎机的赢钱概率就为 $M_i/N$,然后一直摇概率最高的那个。(利用)
这个算法的思想很简单,通过探索得到每个老虎机的赢钱概率,然后选择一个概率最高的老虎机一直摇。
代码实现参考:pure_greedy.py ,运行测试代码可以看到类似的结果。
0号老虎机的概率为:0.1355416916306045,摇100次收益为:13
1号老虎机的概率为:0.5939514278183152,摇100次收益为:58
2号老虎机的概率为:0.6589668115166952,摇100次收益为:67
3号老虎机的概率为:0.6755337560094611,摇100次收益为:67
4号老虎机的概率为:0.2913420268334277,摇100次收益为:31
5号老虎机的概率为:0.32445103069055126,摇100次收益为:34
6号老虎机的概率为:0.5447695432679104,摇100次收益为:46
7号老虎机的概率为:0.5142948397820707,摇100次收益为:53
8号老虎机的概率为:0.6631081989312548,摇100次收益为:74
9号老虎机的概率为:0.1570983569528034,摇100次收益为:15
收益最高的估算是:8号老虎机的概率为:0.6631081989312548
最终收益:6127代码里面我们定义了10个老虎机,每个老虎机的赢钱概率都是随机生成的,然后每个老虎机摇100次,基本上最后通过探索估算的收益最大的老虎机也就是实际上赢钱概率最高的,不信的话可以多试几次。这个现象背后有概率论中大数定律的支持,感兴趣可以了解一下。
在测试代码里面我们是上帝视角,在真实世界中老虎机的概率或者说一个广告的真实点击率我们是不清楚的,所以朴素贪心算法就是通过探索的结果来估算真实的概率,然后就押注在探索出来的最高收益率的老虎机身上。
从实验结果看,朴素贪心算法已经挺准的了,但我们仔细看会发现,实际上有些收益很低的老虎机其实我们试个10次就知道概率很低,不需要都试够100次,这样就不会浪费机会。另外探索和利用是完全分开的,所以如果有老虎机的概率发生变化,或者新加入了老虎机,那么就需要重新做一遍探索。为了解决探索过程中的浪费情况和应对概率变化,Epsilon 贪心算法(ε-Greedy)应运而生。
Epsilon 贪心算法
MAB算法的思路是每次选择要么探索要么利用,Epsilon 贪心算法把每一步要做探索还是利用通过概率ε来决定。算法步骤如下:
- 初始化一个概率ε(ε∈[0,1])。
- 每次选择前都随机一个数A(A∈[0,1]):
1. 如果A小于ε,就进行探索,也就是随机选择一个老虎机摇。
2. 如果A大于等于ε,就进行利用,也就是选择一个赢钱概率最高的老虎机摇。
一般来说,ε都会设定的比较小,例如0.01之类的,目的是小概率探索新的,大概率选择赢钱概率高的。对比朴素贪心算法,Epsilon 贪心算法把探索和利用放在选择的过程中交替执行,这样做的好处是可以边探索边利用,即使加入了新的老虎机,或者某台老虎机的概率突然提升了,也有机会通过探索发现。
代码实现参考:epsilon_greedy.py ,运行测试代码可以得到如下的结果:
0号老虎机的概率为:0.1355416916306045,收益为:15
1号老虎机的概率为:0.5939514278183152,收益为:4
2号老虎机的概率为:0.6589668115166952,收益为:4
3号老虎机的概率为:0.6755337560094611,收益为:5232
4号老虎机的概率为:0.2913420268334277,收益为:3
5号老虎机的概率为:0.32445103069055126,收益为:2
6号老虎机的概率为:0.5447695432679104,收益为:1071
7号老虎机的概率为:0.5142948397820707,收益为:3
8号老虎机的概率为:0.6631081989312548,收益为:17
9号老虎机的概率为:0.1570983569528034,收益为:1
最终收益:6352上面的概率跟朴素贪心算法的初始概率相同,由于Epsilon 贪心算法探索的概率为0.01,所以浪费在探索上面的遗憾比较少,整体收益高于朴素贪心算法。
Epsilon 贪心算法也有缺点,因为探索是完全随机的,没有利用到历史的数据,跟朴素贪心算法一样,对于明显不好的老虎机也会进行探索。改进的思路有两种:第一种是随着尝试的次数增长减少ε的值,这样整体浪费在探索上面的机会就变少了;第二种是利用历史信息,选择还不是很确定的老虎机进行探索,放弃那些探索多次而且收益概率低的老虎机。第二种思路有两个比较经典的算法,分别是UCB算法和汤普森采样算法。
UCB算法
UCB 算法全称是 Upper Confidence Bound,即置信区间上界。UCB算法用下面的公式给每个老虎机打分。
$$ \underbrace{E\left( \bar{X_{a}} \right) }_{\text{老虎机a的收益概率,即收益除以选择次数} } +\underbrace{\sqrt{\frac{2\log T}{n_{a}} } }_{\text{这个式子是老虎机a的置信区间上边界} } $$
$E\left( \bar{X_{a}} \right)$表示老虎机a的收益概率,反应了a的效果; $\sqrt{\frac{2\log T}{n_{a} } }$是置信区间的上边界,反应了老虎机的效果不确定性,公式中的T表示总的选择次数,$n_{a}$表示老虎机a的被选择次数,从公式可以观察到,当$n_{a}$很小的时,即被选择次数很少时,$\sqrt{\frac{2\log T}{n_{a} } }$的值会较大,这样在打分时就会排序靠前,这意味着我们对老虎机a的收益概率非常不确定,所以要给它机会探索一下。
下面我们举个例子来说明。
- 当总的选择次数$T=1000$,老虎机a的被选择次数$n_{a}=10$时,$\sqrt{\frac{2\log T}{n_{a} } } =\sqrt{\frac{2\log 1000}{10} } =1.17$
- 当总的选择次数$T=1000$,老虎机a的被选择次数$n_{t}\left( a\right)=100$时,$\sqrt{\frac{2\log T}{n_{a} } } =\sqrt{\frac{2\log 1000}{100} } =0.37$
可以发现,随着老虎机的被选择次数逐渐增加,它的不确定性会越来越小,对UCB的结果影响越来越小,逐渐由$E\left( \bar{X_{a}} \right)$来主导。赢钱概率高的老虎机随着被选择次数越来越多,$E\left( \bar{X_{a}} \right)$会稳定在一个比较高的水平,即使它的$\sqrt{\frac{2\log T}{n_{a} } }$ 变小,也有机会胜出。而赢钱概率低的老虎机随着被选择次数越来越多,$E\left( \bar{X_{a}} \right)$会稳定在一个比较低的水平,加上它的$\sqrt{\frac{2\log T}{n_{a} } }$变小,很快没有机会被选。
UCB算法的这种机制不仅可以通过之前的探索经验来快速放弃概率低的老虎机,而且还能够照顾被选择机会少的老虎机,让它们有机会出人头地。
代码实现参考:ucb.py, 运行测试代码可以得到如下的结果:
0号老虎机的概率为:0.1355416916306045,收益为:8,被选择次数为:52
1号老虎机的概率为:0.5939514278183152,收益为:406,被选择次数为:693
2号老虎机的概率为:0.6589668115166952,收益为:1556,被选择次数为:2354
3号老虎机的概率为:0.6755337560094611,收益为:2108,被选择次数为:3126
4号老虎机的概率为:0.2913420268334277,收益为:20,被选择次数为:77
5号老虎机的概率为:0.32445103069055126,收益为:24,被选择次数为:85
6号老虎机的概率为:0.5447695432679104,收益为:371,被选择次数为:640
7号老虎机的概率为:0.5142948397820707,收益为:168,被选择次数为:328
8号老虎机的概率为:0.6631081989312548,收益为:1728,被选择次数为:2598
9号老虎机的概率为:0.1570983569528034,收益为:10,被选择次数为:57
最终收益:6399从测试结果看,低概率的老虎机被选择的次数很少,概率高的老虎机被选择次数多,符合我们的预期。
除了UCB算法,还有另一个算法也是类似的思想,那就是汤普森采样算法。
汤普森采样算法
UCB算法是用置信区间上界来给老虎机打分,汤普森采样算法则是用Beta分布采样来给老虎机打分。这里面有两个名词需要解释一下:什么是Beta分布?什么是采样?
首先解释一下采样,采样也叫取样,从字面上理解就是抽取样本的意思。那么从Beta分布采样是什么意思?平时我们接触比较多的场景是给定一堆样本数据,求样本的概率分布,而采样正好是反过来:给定一个概率分布,生成满足这个概率分布的样本。我们平时在代码里面用到的随机数生成 random方法实际上就是从均匀分布中采样。具体的采样算法可以自行搜索逆转换抽样算法,这里不做展开。
Beta分布是一种概率分布,它的概率分布由α和β决定:
- 当$α+β$值的越大,分布曲线就越窄,也就是说分布越集中,当我们从Beta分布中采样时,采样得到的随机数就会分布在中心的位置。
- 当 $α/(α+β)$的值越大,分布的中心位置离1越近,相反则离0越近,这意味着采样时产生的随机数也会要么更靠近1,要么更靠近0。
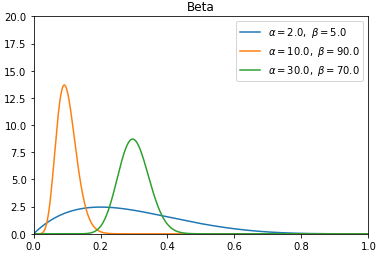
如上面的图所示,我们可以把Beta分布分为两种情况:
- 当$α+β$值很小时,例如 $α=2, β=5$,分布曲线很宽,此时产生的随机数会分散在一个比较大的范围内。
- 当$α+β$值比较大时,例如 $α+β=100$,此时分布会比较集中,产生的随机数会更集中在中心点的位置。
1. 当 $α/(α+β)$的值比较小,例如$α/(α+β)=10/(10+90)=0.1$,分布曲线的中心点会更靠近0,意味着产生的随机数大概率会更靠近0。
2. 当 $α/(α+β)$的值比较大,例如$α/(α+β)=30/(30+70)=0.3$时,分布曲线的中心点会更靠近1,意味着产生的随机数大概率会更靠近1。
讲了这么多东西,跟MAB问题有什么关系呢?我们可以把α当做摇老虎机A之后得到收益的次数,把β当做摇老虎机A没有得到收益的次数,那么 $α+β$就是老虎机A总的选择次数。代入上面的性质可以发现:
- 老虎机A总共摇了7次,其中3次有收益即 $α=2$,5次没有收益即$β=5$
- 老虎机B总共摇了100次,其中10次有收益即 $α=10$,90次没有收益即$β=90$
- 老虎机C总共摇了100次,其中30次有收益即 $α=30$,70次没有收益即$β=70$
那么后面选择老虎机时,根据Beta分布来计算分数的话,汤普森采样算法会倾向于选择老虎机A和C。为什么会这样?根据Beta分布的性质,从老虎机A、B、C的分布采样时,因为老虎机A被选择的次数比较少,所以它的分布比较宽,大部分落在了0到0.6之间,随机采样的数字也比较大的概率比较大,也就是说能够有大概率被选择;而老虎机B被选择次数多,分布就比较集中,而且它的峰值靠近0,所以采样的数字就会集中在峰值附近,意味着随机数会比较小,很难有机会被选择;老虎机C也是被选择了很多次,但是它的收益高,所以峰值更靠近1,被选择的机会也很多。
从上面的分析我们可以发现:汤普森采样算法跟UCB算法的思想是类似的:更多的利用收益概率高的老虎机,更多的探索被选择次数少,不确定收益概率的老虎机。它们区别主要在于使用的思路不一样,UCB算法是使用霍夫丁不等式推导出的置信区间上界来给每个老虎机打分,汤普森采样算法则是基于贝叶斯公式计算每个老虎机的Beta分布,然后从分布中采样进行打分。
代码实现参考:thompson_sampling.py,运行测试代码可以得到如下结果:
0号老虎机的概率为:0.1355416916306045,收益为:1,被选择次数为:3
1号老虎机的概率为:0.5939514278183152,收益为:11,被选择次数为:24
2号老虎机的概率为:0.6589668115166952,收益为:3061,被选择次数为:4599
3号老虎机的概率为:0.6755337560094611,收益为:2,被选择次数为:6
4号老虎机的概率为:0.2913420268334277,收益为:2,被选择次数为:7
5号老虎机的概率为:0.32445103069055126,收益为:1,被选择次数为:4
6号老虎机的概率为:0.5447695432679104,收益为:56,被选择次数为:104
7号老虎机的概率为:0.5142948397820707,收益为:4,被选择次数为:12
8号老虎机的概率为:0.6631081989312548,收益为:3509,被选择次数为:5235
9号老虎机的概率为:0.1570983569528034,收益为:4,被选择次数为:26
最终收益:6651从运行结果中可以看到,在同样的概率下,汤普森采样算法的效果最好,因为它能很快收敛到概率比较高的老虎机,在探索上面浪费的机会比较少。
MAB(Bandit)算法应用
前面我们一直在拿老虎机做例子,那么除了老虎机MAB算法还能用在哪些地方?在推荐系统中,有很多问题都可以套用MAB问题的解决思路。
在广告投放系统中,MAB算法可以用来给用户推荐广告。把每个广告当做一个老虎机,点击当做收益,曝光当做选择的次数,MAB算法的隐含假设是每个广告都有先验的点击率,只是我们不知道而已,所以我们可以用算法来探索出不同广告的点击率。
你可能会发现MAB算法只考虑了广告本身的点击率,没有考虑到不同用户对不同广告的兴趣不同,点击率也是不一样的,所以MAB算法用来做推荐不是一个最优的、也不是真正个性化的。没错,这是因为我们是拿所有用户的点击和曝光数据来训练MAB算法,所以计算出的点击率也是所有用户的兴趣决定的。如果我们换个思路,把每个用户对每个广告的点击和曝光数据用来训练,就能探索出单个用户对单个广告的点击率,也就是说假设有M个广告、N个用户,原来的做法只需要训练M个模型,新的做法要训练M*N个模型,这样就能探索到每个用户对每个广告的点击率。第二种思路理论上可行,但实际上是不可行的,因为当用户数很大时,平均每个广告对单用户的曝光次数是非常少的,这样MAB算法无法积累足够的数据收敛。因此,一般来说,MAB算法可以用来作为个性化算法的兜底,毕竟MAB算法简单,依赖的数据少,执行速度也很快,效果也不错。个性化算法一般性能消耗比较大,如果从性价比看,其实MAB算法是有竞争力的。
除了推荐,广告的智能UI也常用MAB算法来给创意进行文案优选。广告主会给一个创意配置多组文案,文案对点击率的影响很大,把文案当做老虎机,点击当做收益,曝光当做选择的次数,用MAB算法同样能探索到不同文案的点击率,然后推荐最优的文案。
不仅是广告和文案,甚至算法模型也可以用MAB算法来优选。在推荐系统中,算法工程师会设计多个模型,那么怎么知道哪种模型的效果最好?一种常见思路是通过AB实验,这种方式需要工程师人肉控制流量。另一种思路是用MAB算法来探索,把算法模型当做是老虎机,点击当做收益,曝光当做选择的次数,这样就能探索到不同模型的点击率,相比AB实验固定流量的策略,MAB算法能够减少探索的流量浪费,在多个模型中得到最大收益。
从实际的使用效果来看,MAB算法在候选集比较小的情况下效果很好,这种情况下MAB算法对每个候选能够有足够的数据让算法收敛,并且候选集小的情况下,符合大众兴趣的候选点击率会最高,MAB算法也会倾向于推荐点击率最高的,这样整体收益是最大化的。
那么MAB算法不适合用在哪些场景呢?因为MAB算法只考虑了收益一个维度的信息,没有考虑其他的附加信息,例如淘宝的商品推荐就不适合使用MAB算法,用户的特征例如年龄和性别,以及商品的本身的属性都是对推荐结果有很大影响的,女生用的商品尽管点击率高,如果推荐给男生点击率肯定不高。而且淘宝商品数量太多,每个商品曝光的机会很少,用MAB算法很难收敛。
算法推导
文章的最后附上UCB算法和汤普森采样算法的推导过程,这部分内容需要概率论和数理统计的知识作为前置准备,感兴趣的读者可以自行阅读。
UCB算法
假设X是摇老虎机收益的独立同分布随机变量,取值为0或者1。 $X_{1} ... X_{n}$是样本,用 $E(X)$表示随机变量的期望(均值),$E\left( \bar{X} \right)$表示样本的均值。根据霍夫丁不等式,有
$$ P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \delta \right\} \geqslant 1-2e^{-2n\delta^{2} } $$
$E(X)$是收益的平均值,计算公式是$\frac{X_{1}...X_{n}}{n}$,n趋于无穷,也就是老虎机真实的收益率,$E\left( \bar{X} \right)$是样本的收益平均值,计算公式也是$\frac{X_{1}...X_{n}}{n}$,不同的是n是有限的,在统计推断中,频率学派尝试用频率来逼近概率,即只要我们做的实验次数足够多,那么就能用频率来近似概率。这里说的频率就是$E\left( \bar{X} \right)$,概率是 $E(X)$,因此$|E(X)-E\left( \bar{X} \right) |\leqslant \delta$表示概率与频率之间的误差小于δ的事件,那么这个事件的概率就表示为$P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \delta \right\}$,所以霍夫丁不等式的意思就是说概率与频率之间的误差小于δ这个事件发生的概率大于 $1-2e^{-2n\delta^{2} }$。
可以发现,当δ固定时,n越大,$P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \delta \right\}$发生的概率越大,也就是说只要我们实验次数越多,频率$E\left( \bar{X} \right)$ 就越逼近概率$E(X)$。δ就是频率与概率之间的误差,误差越小,说明频率跟概率越接近。
假设T为摇老虎机的总次数,n为老虎机a被摇过的次数,令$\delta =\sqrt{\frac{2lnT}{n} }$,代入不等式可以得到
$$ \begin{aligned} P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \sqrt{\frac{2lnT}{n} } \right\} &\geqslant 1-2e^{-2n\left( \sqrt{\frac{2lnT}{n} } \right)^{2} } \\ &\geqslant 1-2e^{-2n\frac{2lnT}{n} } \\ &\geqslant 1-2e^{-4lnT} \\ &\geqslant 1-\frac{2}{T^{4}} \end{aligned} $$
也就是说当$\delta =\sqrt{\frac{2lnT}{n} }$时,$P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \delta \right\}$成立的概率是$1-\frac{2}{T^{4}}$。
- 当T=2时,成立的概率为0.875。
- 当T=3时,成立的概率为0.975。
- 当T=4时,成立的概率为0.992。
可以发现$\delta =\sqrt{\frac{2lnT}{n} }$随着T变大,成立的概率会越来越高,意味着这是一个很好的估计误差。
$P\left\{ |E(X)-E\left( \bar{X} \right) |\leqslant \sqrt{\frac{2lnT}{n} } \right\} \text{等价于} E\left( \bar{X} \right) -\sqrt{\frac{2lnT}{n} } \leqslant E(X)\leqslant E\left( \bar{X} \right) +\sqrt{\frac{2lnT}{n} }$,也
就是说$E\left( \bar{X} \right) +\sqrt{\frac{2lnT}{n} }$是$E(X)$的置信区间上界,UCB算法就是拿这个来给每个老虎机打分。
举个例子,假设有一台老虎机a:
- 当总的选择次数$T=1000$,老虎机a的被选择次数$n_{a}=10$时,$\sqrt{\frac{2\log T}{n_{a} } } =\sqrt{\frac{2\log 1000}{10} } =1.17$
- 当总的选择次数$T=1000$,老虎机a的被选择次数$n_{t}\left( a\right)=100$时,$\sqrt{\frac{2\log T}{n_{a} } } =\sqrt{\frac{2\log 1000}{100} } =0.37$
可以发现,随着老虎机的被选择次数逐渐增加,它的$\delta =\sqrt{\frac{2\log T}{n_{a} } }$ 会越来越小,对UCB的结果影响越来越小,逐渐由$E\left( \bar{X_{a}} \right) $来主导。赢钱概率高的老虎机随着被选择次数越来越多,$E\left( \bar{X_{a}} \right)$会稳定在一个比较高的水平,即使它的$δ$ 变小,也有机会胜出。而赢钱概率低的老虎机随着被选择次数越来越多,$E\left( \bar{X_{a}} \right)$会稳定在一个比较低的水平,加上它的$δ$变小,很快没有机会被选。
汤普森采样算法
摇老虎机有收益的概率$p=θ$,没有收益的概率$p=1-θ$,这是一个典型的伯努利分布(二项分布),简单回顾一下伯努利分布的公式,假设X是满足伯努利分布的随机变量,则
$$ P\left\{ X=k\right\} =C^{k}_{n}\theta^{k} (1-\theta )^{n-k}\ \ \ k=0,1,...,n $$
举一个具体的例子,假设老虎机a的赢钱概率是$θ=0.5$,总共摇了$n=10$次,那么老虎机10次只摇中$k=1$次有收益的概率为:$P\left\{ X=1\right\} =C^{1}_{10}0.5^{1}(1-0.5)^{10-1}=0.009765625$。
汤普森采样算法是基于贝叶斯统计推断的思路,按照贝叶斯的套路,首先要给概率p找一个先验分布,因为Beta分布是伯努利分布的共轭分布,所以一般就拿Beta分布来作为先验分布,下面是Beta分布的公式:
$$ \begin{aligned} Beta(\theta |\alpha ,\beta )&=\frac{1}{\int^{1}_{0} \theta^{\alpha -1} (1-\theta )^{\beta -1}d\theta } \theta^{\alpha -1} (1-\theta )^{\beta -1}\\ &=\frac{\Gamma (\alpha )\Gamma (\beta )}{\Gamma (\alpha +\beta )} \theta^{\alpha -1} (1-\theta )^{\beta -1}\\ &=\frac{1}{B(\alpha ,\beta )} \theta^{\alpha -1} (1-\theta )^{\beta -1} & (B(\alpha ,\beta )=\frac{\Gamma (\alpha )\Gamma (\beta )}{\Gamma (\alpha +\beta )} ) \end{aligned} $$
假设先验概率$p(\theta )=Beta(\theta |\alpha ,\beta )$,则在先验分布为Beta分布的情况下,我们做实验得出的条件概率$p(x|\theta )=C^{k}_{n}\theta^{k} (1-\theta )^{n-k}$,根据全概率公式,样本概率$p(x)=\int^{1}_{0} p(\theta^{\prime } )p(x|\theta^{\prime } )d\theta^{\prime }$,根据条件概率公式,$p(x\theta )=p(\theta )p(x|\theta )$,我们的目的是求后验概率$p(θ|x)$,所以根据贝叶斯公式可以得到:
$$ \begin{aligned} p(x|\theta )&=\frac{p(x\theta )}{p(x)} \\ &=\frac{p(\theta )p(x|\theta )}{\int^{1}_{0} p(\theta )p(x|\theta )d\theta } \\ &=\frac{\frac{1}{B(\alpha ,\beta )} \theta^{\alpha -1} (1-\theta )^{\beta -1}C^{k}_{n}\theta^{k} (1-\theta )^{n-k}}{\int^{1}_{0} \frac{1}{B(\alpha ,\beta )} \theta^{\alpha -1} (1-\theta )^{\beta -1}C^{k}_{n}\theta^{k} (1-\theta )^{n-k}d\theta^{} } \\ &=\frac{\theta^{\alpha +k-1} (1-\theta )^{\beta +n-k-1}}{\int^{1}_{0} \theta^{\alpha +k-1} (1-\theta )^{\beta +n-k-1}d\theta^{} } \ (\text{上下约掉同类项,合并指数项} )\\ &=\frac{1}{\int^{1}_{0} \theta^{(\alpha +k)-1} (1-\theta )^{(\beta +n-k)-1}d\theta } \theta^{(\alpha +k)-1} (1-\theta )^{(\beta +n-k)-1} \ (\text{根据Beta分布定义} )\\ &=\frac{1}{B(\alpha +k,\beta +n-k)} \theta^{(\alpha +k)-1} (1-\theta )^{(\beta +n-k)-1}\ \\ &=Beta(\theta |\alpha +k,\beta +n-k) \end{aligned} $$
根据上面的推导,可以发现后验概率$p(θ|x)$也是一个Beta分布,而且跟老虎机的被选择次数n和收益次数k相关。我们假设了一个先验分布$p(\theta )$和条件分布$p(x|\theta )$,然后用贝叶斯公式推导出了一个后验分布$p(θ|x)$,由于α和β都是常数,将n和k代入之后就能得到一个确定的Beta分布。、
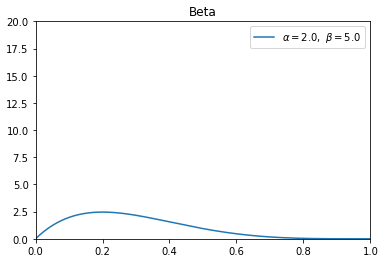
举个例子,假设老虎机a的$α=0$和$β=0$,则$Beta(\theta |\alpha +k,\beta +n-k)=Beta(\theta |k,n-k)$,也就是老虎机a的概率分布完全取决了n和k,老虎机A总共摇了7次,其中3次有收益即 $k=2$,5次没有收益即$n-k=5$,此时老虎机a的概率分布为$Beta(\theta |2,5)$,对应的Beta分布图像如下所示,x是θ的取值:
问题来了,我们得到了一个Beta分布的公式,但θ是个未知变量,那么老虎机a的概率到底是多少?这里就要从贝叶斯统计的思想开始说起了,贝叶斯统计和频率统计的不同就在于:
- 频率统计是通过多次实验来推测概率θ的值,但是现实中采样的样本不可能无限多,所以还要计算出似然概率的置信区间来描述θ的不确定性,根据霍夫丁不等式,样本数量越多,误差越小,也就有了前面的UCB算法:用频率加上误差上界作为老虎机的预测概率;
- 而贝叶斯统计则先假设了一个先验分布,然后根据贝叶斯公司用观测的数据样本来计算后验分布,通过后验概率分布来描述θ的不确定性,随着样本的增加,这个概率分布在真实θ附近的概率密度会越来越大。
根据Beta分布概率密度函数的性质,当$\theta =\frac{\alpha -1}{\alpha +\beta -2}$时,Beta分布取得最大值,即$\theta =\frac{\alpha -1}{\alpha +\beta -2}$是最大后验概率,其出现的概率最大,那么我们用最大后验概率作为老虎机的概率可以吗?答案是不行,因为最大后验概率完全依赖于α和β,在MAB问题中我们对所有老虎机一般都是设置相同的α和β,这样不同老虎机的区分度就不够,算法运行起来容易出现探索不够的情况,出现赢家通吃的情况,前面尝试的老虎机如果收益还行,后面的老虎机没有被选择的机会。例如下面的例子,每个老虎机的初始值都是$α=2$,$β=2$,然后用最大后验概率给老虎机打分,可以发现在探索到1号老虎机之后就把所有机会都给它了。
0号老虎机的概率为:0.1355416916306045,收益为:1,被选择次数为:3
1号老虎机的概率为:0.5939514278183152,收益为:5966,被选择次数为:10000
2号老虎机的概率为:0.6589668115166952,收益为:0,被选择次数为:0
3号老虎机的概率为:0.6755337560094611,收益为:0,被选择次数为:0
4号老虎机的概率为:0.2913420268334277,收益为:0,被选择次数为:0
5号老虎机的概率为:0.32445103069055126,收益为:0,被选择次数为:0
6号老虎机的概率为:0.5447695432679104,收益为:0,被选择次数为:0
7号老虎机的概率为:0.5142948397820707,收益为:0,被选择次数为:0
8号老虎机的概率为:0.6631081989312548,收益为:0,被选择次数为:0
9号老虎机的概率为:0.1570983569528034,收益为:0,被选择次数为:0
最终收益:5985为了避免赢家通吃,让所有老虎机都有被探索的机会,我们得到后验分布之后,给老虎机打分不是用最大后验概率,而是用从Beta分布中采样的方式,按照Beta分布的概率密度函数随机生成[0,1]的随机数,这些随机数满足Beta分布,即生成的随机数在Beta分布图像中密度(Y轴)越大,出现的概率越高,例如上面$α=2$,$β=5$的图像中,最大后验概率$\theta =\frac{\alpha -1}{\alpha +\beta -2} =\frac{2-1}{2+5-2} =0.2$,所以假设生成了100个随机数,在0.2附近的随机数是最多的,偶尔也会出现0.6以上的随机数。通过采样的方式,就能保证所有的老虎机都有机会被探索,同时大概率会利用到最好的老虎机。
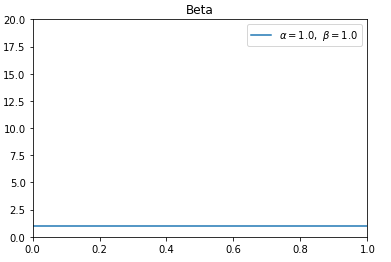
在实际应用中,由于我们不清楚老虎机的赢钱概率,所以先验参数一般设置为$α=1$,$β=1$,此时Beta分布等价于均匀分布,采样时所有随机数产生的概率一样。如下图所示:
参考资料
https://book.douban.com/subject/4175522/
https://zhuanlan.zhihu.com/p/164577056
https://zhuanlan.zhihu.com/p/53595666
https://www.cnblogs.com/heben/p/10908010.html
https://en.wikipedia.org/wiki/Inverse_transform_sampling
https://blog.csdn.net/liubai01/article/details/79947975
https://zhuanlan.zhihu.com/p/125658638
https://zhuanlan.zhihu.com/p/32356077
https://www.cnblogs.com/sylvanas2012/p/5058065.html
https://www.zhihu.com/question/33959624/answer/92311220
https://zhuanlan.zhihu.com/p/32502139