OSS加速器介绍
对象存储OSS(Object Storage Service)具有海量、可靠、安全、高性能、低成本的特点。OSS提供标准、低频、归档、冷归档类型,覆盖多种数据从热到冷的存储需求,单个文件的大小从1字节到48.8TB,可以存储的文件个数无限制。OSS已成为互联网、企业级数据应用的基础设施。
然而,随着互联网业务的发展,越来越多的业务对数据的吞吐提出了更高的要求。为此,阿里云对象存储OSS重磅推出OSS加速器功能,它可以缓存OSS中的热点对象,提供高性能、高吞吐量的数据访问服务。
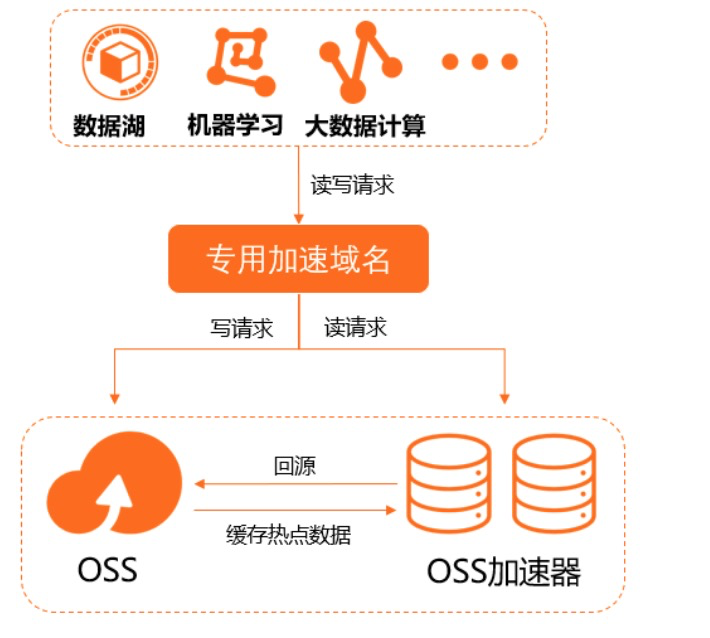
OSS加速器适用于基因训练、机器学习、数据湖大数据计算等需要大带宽,且数据重复读较多的场景。OSS加速器是一个标准的服务端缓存服务,和计算完全解耦,不同于传统的OSS功能,其为AZ级的服务模式,用户可以在相关AZ创建加速器,计算引擎通过缓存加速域名进行数据读写。在典型的一些数据湖场景中,例如大数据计算(EMR/DLA等) + OSS场景中,数据读取要求的带宽可能高达数百Gbps~Tbps,普通存储空间的吞吐能力往往无法轻松应对这种大带宽的读取需求。这时您可以开启OSS加速器,将需要重复读取的数据缓存在加速中。当上层应用向OSS加速器请求数据时,加速器根据您购买的加速器的容量大小提供1.6Gbps/TB的带宽(或200MBps/TB的吞吐)和一定的回源带宽(回源带宽是指首次访问不存在于加速器中的数据时,从OSS读取原始数据的带宽,然后OSS会将该数据缓存到加速器中)。
下图是数据访问流程:
OSS加速器技术特点
1) 极致吞吐能力
OSS加速器有效解决多种应用场景(比如数据湖等)的读吞吐的挑战,特别是重复读的场景,其能够每TB提供200MBps(Byte)的吞吐能力,线性扩展,最高可以交付Tbps的带宽交付能力。
2)弹性伸缩
通常计算任务有周期性需求,如何有效避免资源浪费,提效降本?通过OSS加速器的弹性伸缩能力,能够在线进行扩容缩容,可以按需释放或提升资源,有效降低TCO。
3)存算分离
OSS加速器满足计算资源和存储资源解耦,面对计算任务的多样化,不再需要多个自建缓存搭建匹配,存算分离,灵活选择引擎和版本,满足多业务场景的吞吐加速。
4)数据一致
同时,基于OSS智能元数据架构,OSS加速器提供了传统缓存方案不具备的一致性,当OSS上文件被更新时,加速器能自动识别,确保引擎读取到的都是最新数据。
使用示例
下面将演示如何创建OSS加速器以及使用OSS加速器的实际效果。
创建OSS加速器
用户可以在OSS控制台主页面左侧的导航栏下方看到"OSS加速器"标签页,申请试用通过后,可以看到OSS加速器功能界面
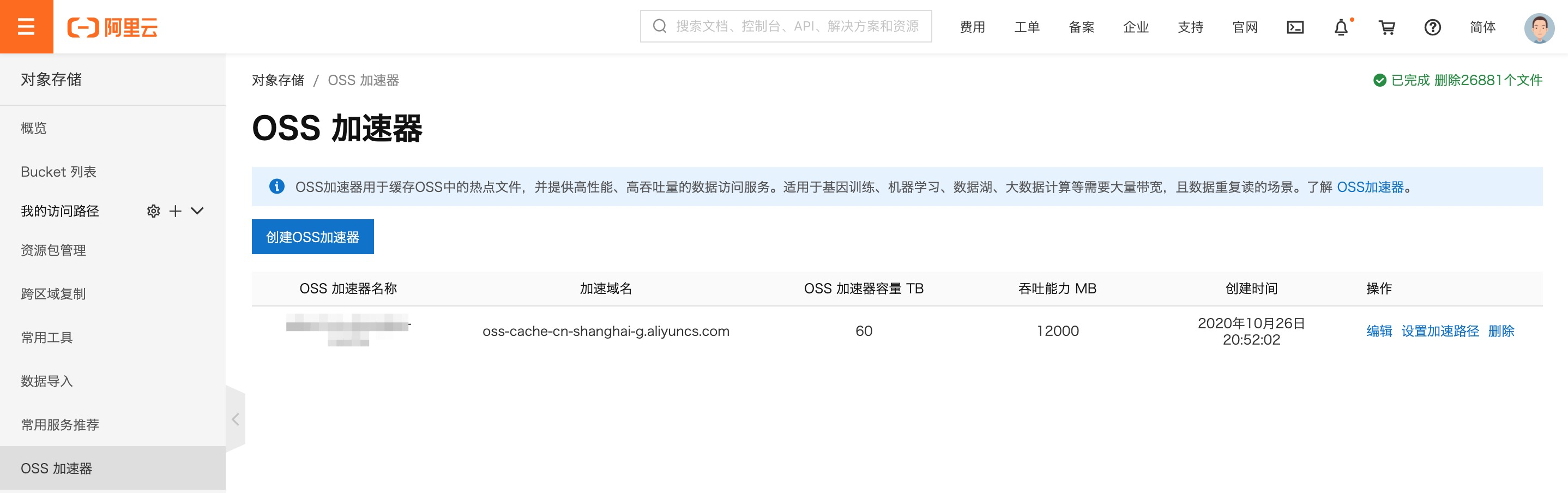
点击“创建OSS加速器”按钮后我们可以创建OSS加速器,这个时候会弹出"创建OSS加速器"对话框

您可以设置加速器的名称和容量,目前加速器的容量是20TB起步,最高可以设置100TB(更高的容量需要开工单进行申请),容量步长为5TB。目前OSS加速器支持的的可用区是上海的cn-shanghai-g可用区,其他的可用区正在逐步开放中。
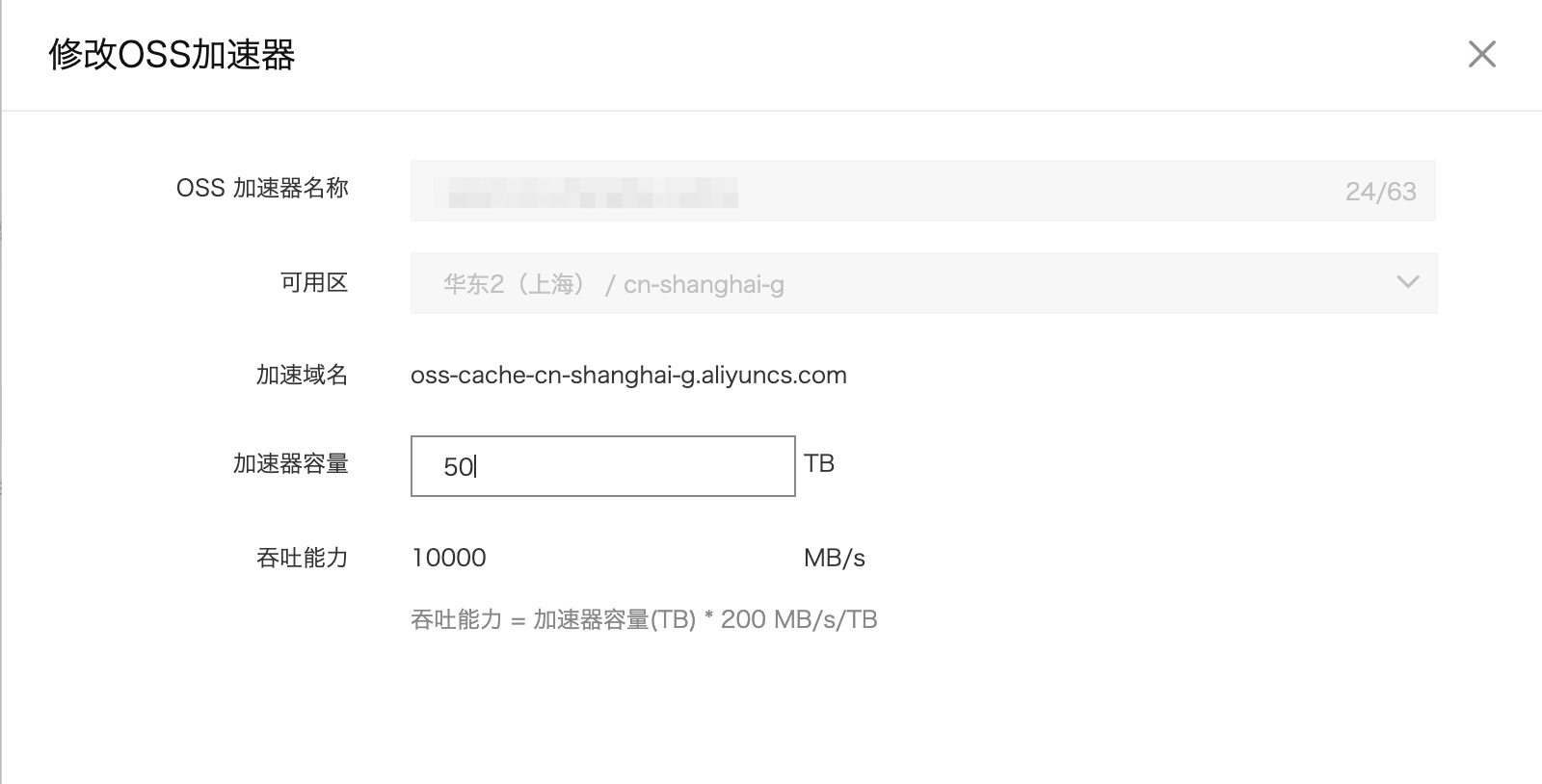
修改加速器容量
创建好加速器后,我们还可以修改加速器的容量,修改加速器的容量同样会修改相关的带宽(吞吐)指标(这里显示的是MB/s,可以自行折算成Mbps或Gbps)。
设置加速路径
创建好加速器后,我们需要设置加速路径(加速路径是指当访问对象的前缀匹配加速路径时,会访问加速器进行加速数据访问)。
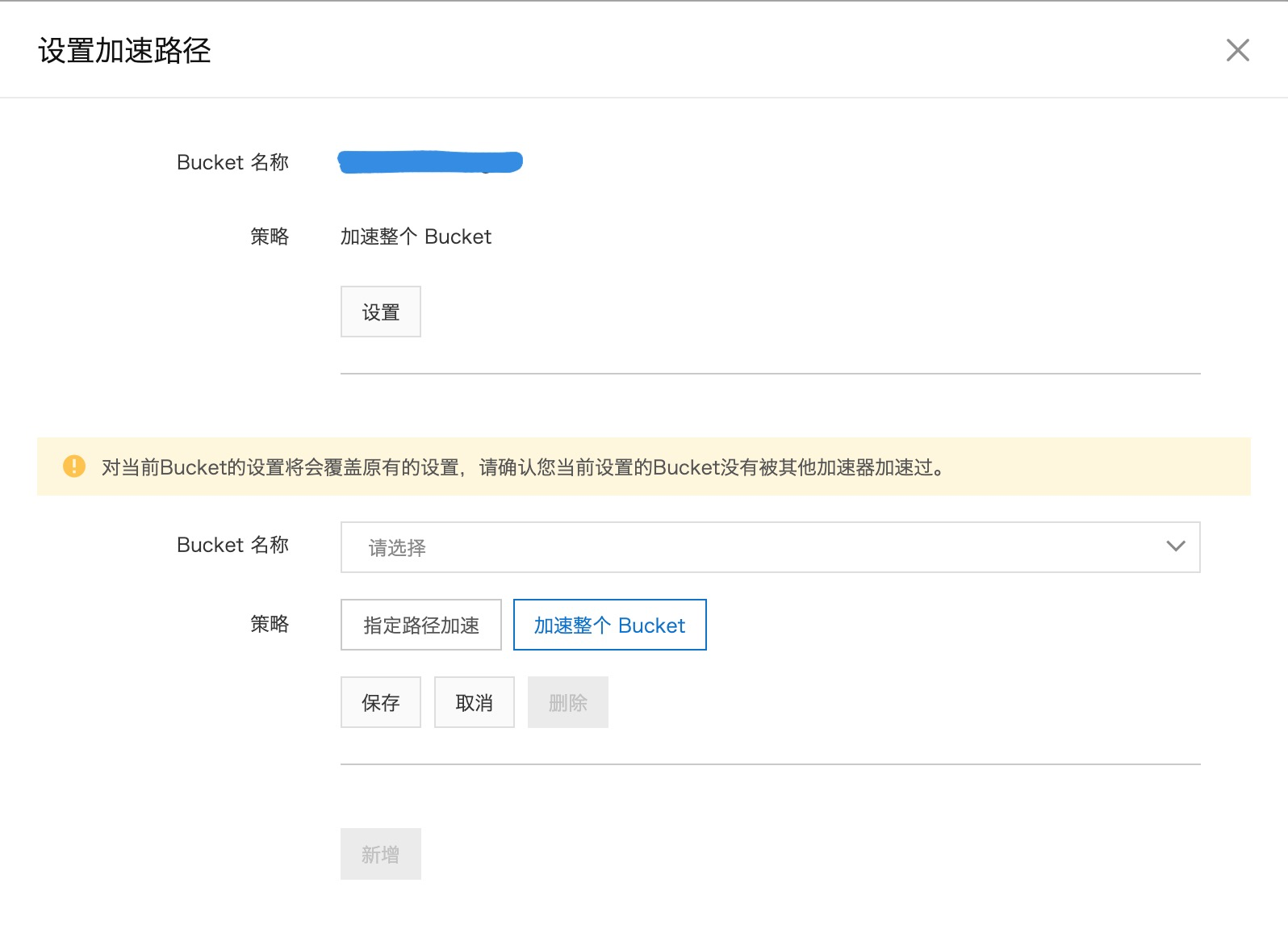
目前一个加速器可以可以配置的bucket数量无限制,每个bucket可以配置最多10个加速路径(如果不设置加速路径的话,将会加速整个bucket里面的数据读取)。
效果展示
下面我们展示一下加速容量从40TB提升到100TB,然后再降为70TB的效果图(图上的带宽吞吐单位是Byte/s,读取的对象之前访问过,已经缓存在加速器中)。
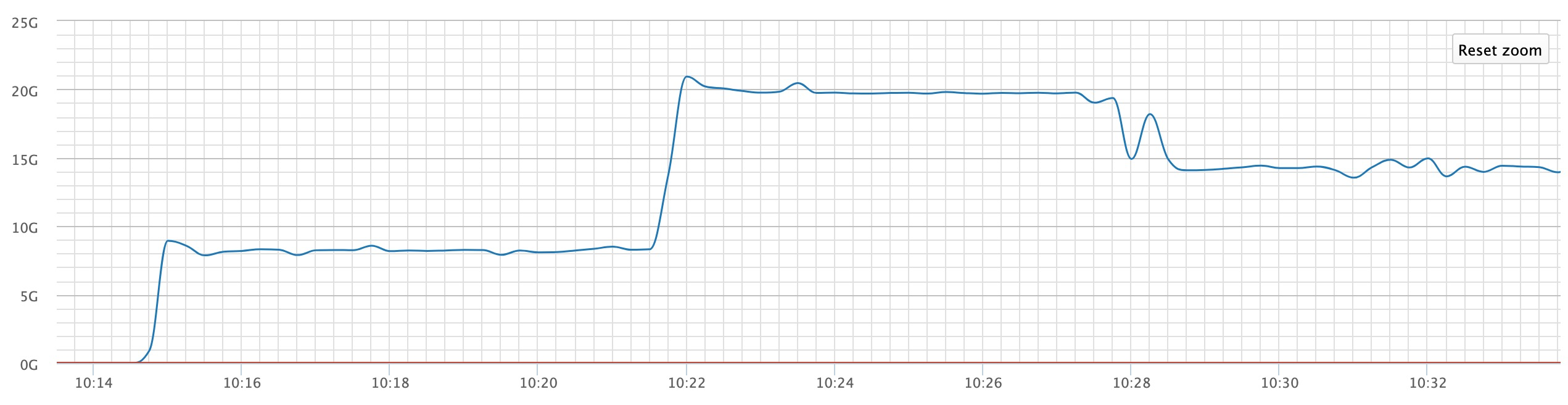
40TB的加速器容量对应的读带宽约是62.5Gbps,当我们将加速器容量提升到100TB时,带宽上升到约156.25Gbps,然后我们将加速器容量降低到70TB,我们可以看到带宽降到约109.375Gbps。可见OSS加速器可以很好地实现读吞吐带宽的按需提升,弹性伸缩,满足相关业务的需求。
试用申请
目前阿里云对象存储OSS加速器在邀测使用中,阿里云企业认证用户可申请试用,点击立即申请

