摘要:本文由墨芷技术团队唐铎老师分享,主要讲述其技术团队内部引入流计算的整个过程,包括最初的决策、期间的取舍以及最终落地,一路走来他们的思考、感悟以及经验分享。
- 初识 Flink
- 为什么一定要上 Flink
- 一个小例子
- 总结
Tips:“实时即未来”在很多人的眼中可能只是一句口号,但在墨芷,这是他们亲手创造的故事。
大家好,我们是浙江墨芷信息科技有限公司,一个刚刚满3年的创业团队,主营业务是电商代运营,目前是淘宝四星级服务商。
我们的核心团队先后服务于国内知名女装、家电、母婴、男装、童装、珠宝饰品、化妆品等多个品类知名品牌商,具有丰富的品牌运营管理经验,服务过的品牌均在行业前列。
主营业务围绕泛时尚领域(服装、婴童、美妆、生活家居、珠宝饰品)互联网平台品牌运营及全网品牌推广,涉及品牌定位与推广、电商运营、商品企划与经营、视觉设计、营销推广、顾客服务、仓储物流等综合端到端服务。
本文将分享墨芷与流计算结缘的故事。
01 初识Flink
第一次接触 Flink 流计算是在18年9月的云栖大会上,大沙老师与在场以及线上的开发者们分享 Flink,会场座无虚席,会场门外还围着三五层的听众。虽然老师的讲解时间不长,听的也是一知半解,却有种很强烈感觉,“实时,即是未来”。
从云栖小镇回来后,跟自己的团队讨论了一下,大家决定向 Flink 开进,但前进的难度是我们没有预料到的。那个时候学习资料很少,一本《Flink 基础教程》被我们翻来复去的看,动手实操门槛较高,进度非常不理想。

图1 云栖大会流计算分会场
19年3月,有幸参加了在杭州举行的 Flink 用户交流会,报名时只是抱着学习的心态去旁听,但到现场后震惊了,参会的不仅是 Flink 的深度用户,更甚的是每位都来自估值百亿以上的大厂。无论是讨论的内容还是出身都让我们感到自卑。
回来之后的第二天,一起去的五个人不约而同的都到公司加班,即便不说透,这次会议给大家带来的心丽冲击是巨大的,也促使了我们下定决心,即便难度再大也要把 Flink 应用起来。
在此一个月之后,我们用 Java 编写的 Flink Job 上线了,即便实现的功能很简单,但这是我们坚实的一小步。

图2 社区里广为流传的一张照片
2020年年初,疫情肆虐,团队人员变动,客观条件使我们不得不放弃之前用 Java 编写的一切,转投 Python。这个决定极其艰难,我们很清楚,一切将回到原点。
但我们与 Flink 的缘分还没结束。刚好,我们看到社区发起了 PyFlink 扶持计划,于是邮件咨询,也有幸被眷顾。接下来的一个月时间,我们在金竹、付典、断尘几位老师的帮助下,将原有的 Flink Job 迁移到了 PyFlink 上,同时也带着需求去学习 PyFlink 的特性。这才有了与大家分享学习成果的机会。
02 为什么一定要上Flink
说到这,一定有同行问,为啥一个小微企业还要上流计算,用得上吗?
我们面临的是若干个严峻的事实:
- 人员数量的膨胀带来了成倍的开销。公司用了3年时间,将团队规模扩张到的150人,在嘉兴这个小城市里这是很不容易的一件事,而且主业是电商代运营,这种工作更像我们软件行业的项目外包。一提到外包,同行们肯定会联想到人力配备,简单讲,有项目做才能养活人,没项目的话,闲置的人力成本就是亏本买卖。
- 人效提升困难,规定再严格的 KPI 也会有瓶颈。同事们每天上班第一件事就是发前一天的销售业绩,只是这个小小的日报,就要耗费半个小时的时间,数据的时效又是“T + 1”,略显滞后。
- 在做直通车推广时,由于同事的疏忽,一些已经不再需要付费推广或可以降低竞价的商品还在按照原计划持续烧钱,人工监控很难及时地发现这些问题。
作为 IT 规划的主导者,一直以来我都希望可以依托团队在电商经营上丰厚的经验及操盘能力,这样目标很明了,就是搭建我们自己的数据实时决策平台。
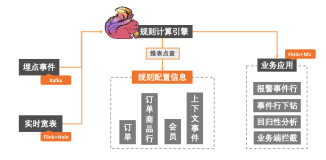
决策,我们暂且拆开来看,决断与策略。团队自有经验及做事的判断逻辑,我们把它划到策略一侧,现在我们缺少的是“决断的能力”,决断既要考虑准确性,又要顾及时效性,当然,如果决断时能渐进地优化策略也是极好的。所以我们大致规划了图3中的架构。从下至上依次为我们的 DataSource(数据源),Swarm(多源数据收集平台),DW(数据仓库),NB(电商离线数据中台),Radical(电商数据决策平台)。数据逐层向上被收集,保存,计算,展现,应用,而Flink在数据的生命周期内担当实时计算的重要任务。
还记得电商场景下商家被薅羊毛的新闻吗?
目前没有任何一款电商 ERP 有针对这方面的功能设计。如果可以编写一个基于 Flink 流计算的实时监控异常销售情况的小插件,在获取到订单中的实付金额去比对之前的商品价格,再结合最新的库存计算后判断得出结果,适时弹出告警,那样的悲剧是否可以避免?
当然,对于电商场景下实时计算的应用点可以开的脑洞是没有边界的,况且,如果以上的系统通过不断地迭代和优化,是否会代替人工成本呢?如果做到了,那一定是一个新的开端。
项目来项目走,短短三年,我们这个小微企业没有记录多大的数据量,无非就是店铺的运营和订单数据,数据采集平台帮助我们秒级地监控在运营的15家店铺,每个店铺有60多个数据监控点。但只有依托 Flink 的流计算,我们才能尽早地从查看到我们想要的数据结果并且做出正确的决策,今天给大家分享的例子也是在这个背景上的。

图3 架构图与技术栈(数据流向)
03 一个小例子
根据我们自身的需求以及 Flink 的特性,我们搭建了一个基于 Flink 流计算的实时监控系统,以监测异常情况。以下是一个线上商品价格实时监控的小例子,这是我们在参加 PyFlink 扶持计划这段时间里完成的,希望可以让大家感受到 PyFlink 开发的便捷。
项目背景
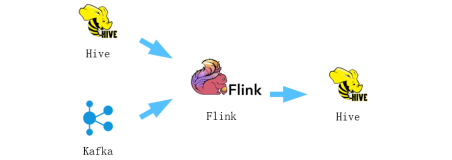
公司里有一个美妆经销项目,即存在旗舰店的同时有数以千计的经销商店铺,业务同事希望可以通过技术手段监控经销商店铺的商品价格不低于旗舰店,避免影响旗舰店销售,于是我们想到如下思路:

图4 问题解决思路
实践过程
根据以上思路,我们先采集到了如下数据样例:
{"shop_name": "经销商1",
"item_name": "凝时精华",
"item_url": "https://*****",
"item_img": "https://*****",
"item_price": 200.00,
"discount_info": "['每满200减20,上不封顶']",
"item_size": ""},
{"shop_name": "经销商2",
"item_name": "精华油1",
"item_url": "https://*****",
"item_img": "https://",
"item_price": 200.00,
"discount_info": "['每满200减15,上不封顶']",
"item_size": "125ml"}然后,根据数据样例可以编写注册 Kafka source 的方法。
# register kafka_source
def register_rides_source_from_kafka(st_env):
st_env \
.connect( # declare the external system to connect to
Kafka()
.version("universal")
.topic("cbj4")
# .topic("user")
.start_from_earliest()
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
) \
.with_format( # declare a format for this system
Json()
.fail_on_missing_field(True)
.schema(DataTypes.ROW([
DataTypes.FIELD('shop_name', DataTypes.STRING()),
DataTypes.FIELD('item_name', DataTypes.STRING()),
DataTypes.FIELD('item_url', DataTypes.STRING()),
DataTypes.FIELD('item_img', DataTypes.STRING()),
DataTypes.FIELD('item_price', DataTypes.STRING()),
DataTypes.FIELD('discount_info', DataTypes.STRING()),
DataTypes.FIELD('item_size', DataTypes.STRING()),
]))) \
.with_schema( # declare the schema of the table
Schema()
.field("shop_name", DataTypes.STRING())
.field("item_name", DataTypes.STRING())
.field("item_url", DataTypes.STRING())
.field("item_img", DataTypes.STRING())
.field("item_price", DataTypes.STRING())
.field('discount_info', DataTypes.STRING())
.field("item_size", DataTypes.STRING())
) \
.in_append_mode() \
.register_table_source("KafkaSource")商品价格参考的 CSV 文件的数据样例为:
1,精华油1,125ml,**,************,敏感肌可用的全身精华油,****,200,180
2,精华油1,200ml,**,************,提亮美白、淡化疤痕,****,300,280
3,按摩油1,125ml,**,************,有效增加肌肤弹性,****,200,180
4,按摩油1,200ml,**,************,持续柔润滋养肌肤,****,300,280
5,按摩油2,125ml,**,************,润弹紧致,深层滋润肌肤,****,300,280
6,沐浴露,500ml,**,************,舒缓镇静,滋润干燥的皮肤,防止肌肤干燥,****,100,80
7,凝时精华,4x6ml,**,************,密集淡纹 多效抗氧 紧致弹润,****,200,180
8,精华油2,30ml,**,************,改善脆弱敏感干皮。小分子精华渗透肌底,密集补水,****,200,180
9,洁面凝胶,200ml,**,************,痘肌洁面优选,****,100,80于是我们可以编写注册 CSV source 的方法。
# register csv_source
def register_rides_source_from_csv(st_env):
# 数据源文件
source_file = '/demo_job1/控价表.csv'
# 创建数据源表
st_env.connect(FileSystem().path(source_file)) \
.with_format(OldCsv()
.field_delimiter(',')
.field('xh', DataTypes.STRING()) # 序号
.field('spmc', DataTypes.STRING()) # 商品名称
.field('rl', DataTypes.STRING()) # 容量
.field('xg', DataTypes.STRING()) # 箱规
.field('txm', DataTypes.STRING()) # 条形码
.field('gx', DataTypes.STRING()) # 功效
.field('myfs', DataTypes.STRING()) # 贸易方式
.field('ztxsjg', DataTypes.STRING()) # 主图显示价格
.field('dpzddsj', DataTypes.STRING()) # 单瓶最低到手价
) \
.with_schema(Schema()
.field('xh', DataTypes.STRING()) # 序号
.field('spmc', DataTypes.STRING()) # 商品名称
.field('rl', DataTypes.STRING()) # 容量
.field('xg', DataTypes.STRING()) # 箱规
.field('txm', DataTypes.STRING()) # 条形码
.field('gx', DataTypes.STRING()) # 功效
.field('myfs', DataTypes.STRING()) # 贸易方式
.field('ztxsjg', DataTypes.STRING()) # 主图显示价格
.field('dpzddsj', DataTypes.STRING()) # 单瓶最低到手价
) \
.register_table_source('CsvSource')以及,我们想要输出到 CSV 的样式:
经销商1,按摩油1,https://**********,https://**********,200.00,[],125ml,200.0,3,按摩油1,125ml,**,************,敏感肌可用的全身精华油,****,200,180
经销商2,精华油2,https://**********,https://**********,190.00,[],30ml,190.0,8,精华油2,30ml,**,************,改善脆弱敏感干皮。小分子精华渗透肌底,密集补水,****,200,180
经销商3,精华油2,https://**********,https://**********,200.00,[],30ml,200.0,8,精华油2,30ml,**,************,改善脆弱敏感干皮。小分子精华渗透肌底,密集补水,****,200,180
经销商1,精华油2,https://**********,https://**********,200.00,['每满200减20;上不封顶'],30ml,180,8,精华油2,30ml,**,************,改善脆弱敏感干皮。小分子精华渗透肌底,密集补水,****,200,180
经销商1,按摩油1,https://**********,https://**********,200.00,['每满200减20;上不封顶'],125ml,180,3,按摩油1,125ml,**,************,有效增加肌肤弹性,****,200,180
经销商3,按摩油1,https://**********,https://**********,200.00,['每满200减20;上不封顶'],125ml,180.0,3,按摩油1,125ml,**,************,有效增加肌肤弹性,****,200,180
经销商2,精华油1,https://**********,https://**********,200.00,['每满200减20;上不封顶'],125ml,180.0,1,精华油1,125ml,**,************,敏感肌可用的全身精华油,****,200,180
经销商3,精华油1,https://**********,https://**********,200.00,['每满200减20;上不封顶'],125ml,180.0,1,精华油1,125ml,**,************,敏感肌可用的全身精华油,****,200,180
经销商1,精华油1,https://**********,https://**********,300.00,['每满200减20;上不封顶'],200ml,280.0,2,精华油1,200ml,**,************,提亮美白、淡化疤痕,****,300,280
经销商1,精华油1,https://**********,https://**********,190.00,['每满200减20;上不封顶'],125ml,190.0,1,精华油1,125ml,**,************,敏感肌可用的全身精华油,****,200,180根据输出样式,我们来编写注册 CSV sink 的方法。
# register csv sink
def register_sink(st_env):
result_file = "./result.csv"
sink_field = {
"shop_name": DataTypes.STRING(),
"item_name": DataTypes.STRING(),
"item_url": DataTypes.STRING(),
"item_img": DataTypes.STRING(),
"item_price": DataTypes.STRING(),
"discount_info": DataTypes.STRING(),
# "discount_info": DataTypes.ARRAY(DataTypes.STRING()),
"item_size": DataTypes.STRING(),
"min_price": DataTypes.FLOAT(),
"xh": DataTypes.STRING(),
"spmc": DataTypes.STRING(),
"rl": DataTypes.STRING(),
"xg": DataTypes.STRING(),
"txm": DataTypes.STRING(),
"gx": DataTypes.STRING(),
"myfs": DataTypes.STRING(),
"ztxsjg": DataTypes.STRING(),
"dpzddsj": DataTypes.STRING(),
}
st_env.register_table_sink("result_tab",
CsvTableSink(list(sink_field.keys()),
list(sink_field.values()),
result_file))输入和输出都有了,我们根据业务同事要求的计算和判断逻辑,即销商店铺的商品价格不低于旗舰店这个规则去编写。
根据编写业务的逻辑,Table API 中算子不能满足所有需求,所以我们需要自定义 UDF 去处理其中几个字段,分别为“根据商品名称匹配实际商品”,“根据商品名称、商品页面价格,识别商品容量”,“按需计算优惠价格”,“格式化优惠券信息”等。
# -*- coding: utf-8 -*-
import re
import logging
from pyflink.table import DataTypes
from pyflink.table.udf import udf, ScalarFunction
# Extend ScalarFunction
class IdentifyGoods(ScalarFunction):
""" 识别商品名称,与标准商品名称对应 """
def eval(self, item_name):
logging.info("进入 UDF")
logging.info(item_name)
# 标准商品名称
regexes = re.compile(r'[精华油洁面凝胶沐浴露凝时精华12]')
items = ["精华油1", "按摩油1", "按摩油1", "精华油2", "洁面凝胶", "沐浴露", "凝时精华"]
items_set = []
for index, value in enumerate(items):
items_set.append(set(list(value))) # 一个标题转成 set,方便做交集
# 先匹配商品名称之外的字符,再去掉
sub_str = re.sub(regexes, '', item_name)
spbt = re.sub(repr([sub_str]), '', item_name) # repr 强制变量非转义
# 找到最为匹配的商品标题,否则认作未知商品
intersection_len = 0
items_index = None
for index, value in enumerate(items_set):
j = value & set(list(spbt)) # 交集
j_len = len(list(j))
if j_len > intersection_len:
intersection_len = j_len
items_index = index
item_name = '未知商品' if items_index is None else items[items_index]
logging.info(item_name)
return item_name
identify_goods = udf(IdentifyGoods(), DataTypes.STRING(), DataTypes.STRING())
class IdentifyCapacity(ScalarFunction):
""" 根据商品名称、商品页面价格,识别商品容量 """
def eval(self, item_name, price):
# 初始化 商品价格与商品规格
price = 0 if len(price) == 0 else float(price)
item_size = ''
# 此处,判断逻辑待修改重构,存在以外BUG
if float(price) <= float(5):
logging.info('这是优惠券!!!')
elif item_name == "精华油1" and price > 200 and price <= 300:
item_size = '200ml'
elif item_name == "精华油1" and price <= 200:
item_size = '125ml'
elif item_name == "精华油1" and price >= 300:
item_size = '精华油1组合装'
elif item_name == "按摩油1" and price > 200 and price <= 300:
item_size = '200ml'
elif item_name == "按摩油1" and price <= 200:
item_size = '125ml'
elif item_name == "按摩油1" and price >= 300:
item_size = '按摩油1组合装'
elif item_name == "按摩油2":
item_size = '125ml'
elif item_name == "精华油2":
item_size = '30ml'
elif item_name == "洁面凝胶":
item_size = '200ml'
elif item_name == "沐浴露":
item_size = '500ml'
elif item_name == "凝时精华":
item_size = '4x6ml'
return item_size
identify_capacity = udf(IdentifyCapacity(), [DataTypes.STRING(), DataTypes.STRING()], DataTypes.STRING())
# Named Function
@udf(input_types=[DataTypes.STRING(),DataTypes.STRING()],result_type=DataTypes.FLOAT())
def get_min_price(price, discount_info):
""" 按需计算优惠价格 """
price = 0 if len(price) == 0 else float(price)
# 匹配所有优惠券
coupons = []
for i in eval(discount_info):
regular_v1 = re.findall(r"满\d+减\d+", i)
if len(regular_v1) != 0:
coupons.append(regular_v1[0])
regular_v2 = re.findall(r"每满\d+减\d+", i)
if len(regular_v2) != 0:
coupons.append(regular_v2[0])
# 如果有优惠券信息,则计算最低价
min_price = price
mayby_price = []
if len(coupons) >= 0:
regexes_v2 = re.compile(r'\d+')
for i in coupons:
a = re.findall(regexes_v2, i)
cut_price = min(float(a[0]), float(a[1]))
flag_price = max(float(a[0]), float(a[1]))
if flag_price <= price:
mayby_price.append(min_price - cut_price)
if len(mayby_price) > 0:
min_price = min(mayby_price)
return min_price
# Callable Function
class FormatDiscountInfo(object):
""" 格式化优惠券信息,以便输出 .csv 文件使用 """
def __call__(self, discount_str):
discount_str = str(discount_str).replace(',', ";")
return discount_str
format_discount_info = udf(f=FormatDiscountInfo(), input_types=DataTypes.STRING(), result_type=DataTypes.STRING())最后编写计算 job 的主体方法:
# query
def calculate_func(st_env):
# 坐标为采集数据表
left = st_env.from_path("KafkaSource") \
.select("shop_name, "
"identify_goods(item_name) as item_name, " # 识别商品名称与基础信息表对应
"item_url, "
"item_img, "
"item_price, "
"discount_info, "
"item_size"
) \
.select("shop_name, "
"item_name, "
"item_url, "
"item_img, "
"item_price, "
"discount_info, "
"identify_capacity(item_name, item_price) as item_size, " # 根据商品名称与商品标价识别商品容量
"get_min_price(item_price, discount_info) as min_price " # 根据页面价与优惠信息计算最低价
) \
.select("shop_name, "
"item_name, "
"item_url, "
"item_img, "
"item_price, "
"format_discount_info(discount_info) as discount_info, " # 格式化优惠信息,方便存放到 .csv文件
"item_size, "
"min_price "
)
# 右表为基础信息表
right = st_env.from_path("CsvSource") \
.select("xh, spmc, rl, xg, txm, gx, myfs, ztxsjg, dpzddsj")
result = left.join(right).where("item_name = spmc && item_size = rl") # 按商品名称、商品容量 join 两表
result.insert_into("result_tab") # 输出 join 结果至 csv sink
# main function
def get_price_demo():
# init env
env = StreamExecutionEnvironment.get_execution_environment()
env.set_parallelism(1) # 设置并行度
env.set_stream_time_characteristic(TimeCharacteristic.EventTime)
st_env = StreamTableEnvironment.create(
env,environment_settings=EnvironmentSettings.new_instance().use_blink_planner().build())
# register source
register_rides_source_from_csv(st_env)
register_rides_source_from_kafka(st_env)
# register sink
register_sink(st_env)
# register function
st_env.register_function("identify_goods", identify_goods)
st_env.register_function("identify_capacity", identify_capacity)
st_env.register_function("get_min_price", get_min_price)
st_env.register_function("format_discount_info", format_discount_info)
# query
calculate_func(st_env)
# execute
print("提交作业")
st_env.execute("item_got_price")04 总结
工程上线后,由于数据收集端在不停的提供数据,借助流计算,我们已经鉴别出 200 个涉嫌违规定价的商品链接,在维护品牌力和价格力的同时,避免旗舰店销售损失 40 余万,而这只是我们众多监控用 Flink Job 中的一个。
在本着“将企业越做越小,市场越做越大”思路的今天,使用 IT 技术来代替人工作业已经是最快捷的一条路,即便像我们这种小微企业并不像大厂那样是技术主导,只要产出能被业务同事喜欢使用且提高工作效率的功能,同时被公司高层所重视,那我们的工作就是有意义的且可持续的。
如果你也像我们一样,以 Python 语言为主,开发工作多为数据分析和实时决策,又渴望享受流计算带来的准确、高效和便捷,那么,欢迎加入 PyFlink 生态,让我们一起为她的明天添砖加瓦。同时 Flink 1.11 版本也预计将在 6 月中下旬发布,届时 PyFlink 将携 Pandas 强势来袭。
最后,再次感谢在扶持计划中所有帮助过我们的人!总之, PyFlink,你值得拥有。

如果您也对 PyFlink 社区扶持计划感兴趣,可以填写下方问卷,与我们一起共建 PyFlink 生态。
PyFlink 社区扶持计划: