最近一直在关注秋招,虽然还没轮到我,不过提前准备总是好的。近期听闻今年秋招形势严峻,为了更好的准备将来的实习、工作,我决定在招聘网站上爬取一些与数据有关的岗位信息,借以给自己将来的职业道路选择提供参考。
一、原理
通过Python的requests库,向网站服务器发送请求,服务器返回相关网页的源码,再通过正则表达式等方式在网页源码中提取出我们想要的信息。
二、网页分析
2.1岗位详情url
在智联招聘网站中搜索'大数据',跳转到大数据岗位页面,接下来我们点开开发者选项,刷新页面,在Network面板的XHR中发现了这样一个数据包:

XHR: XHR为向服务器发送请求和解析服务器响应提供了流畅的接口,能够以异步方式从服务器取得更多信息,意味着用户单击后,可以不必刷新页面也能取得新数据
在新的页面打开后:
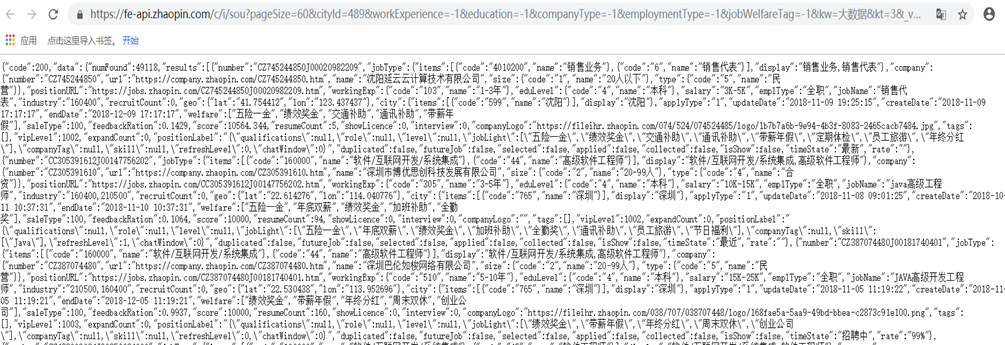
这个页面里出现的所有的岗位信息都在里面了:岗位名称、公司名称、薪水、地区、详情界面的url都在该json里。但是这些信息都不是最重要的,我需要岗位要求以及岗位职责的要求。
将该json解析,得到如下结构的json数据:

code的值为HTTP的响应码,200表示请求成功。而results数组则是该页面岗位信息的数据。点开第一条数据(results的第一个元素):
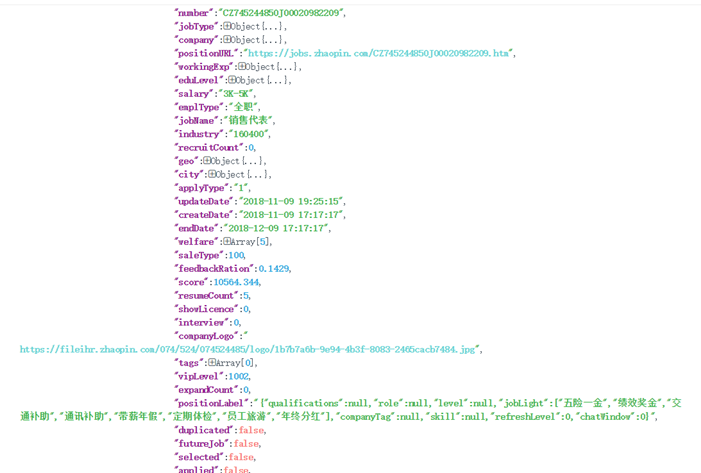
页面中出现的所有数据,以及相关的超链接都在这儿。其中,我们需要的是指向岗位详情界面的超链接——'positionURL'。点击该链接,进去该岗位信息详情页面:

好了,我们需要的信息出现了,不过为了简化页面分析的操作,以及尽可能地不被反爬,我决定选择移动适配的页面。
再打开开发者选项,在该岗位详情页面,刷新:
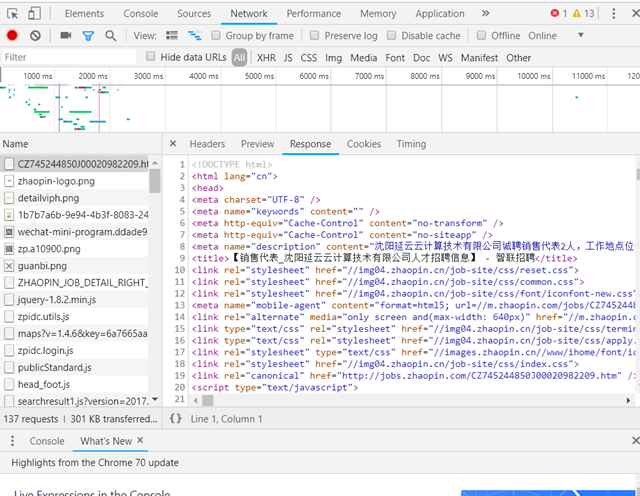
在<meta>中找到'mobile-agent',提取后面的url——'url=//m.zhaopin.com/jobs/CZ745244850J00020982209/',打开:

真清爽!
2.2 Xpath定位
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言
分析该网页的源代码,寻找我们所需信息的位置:
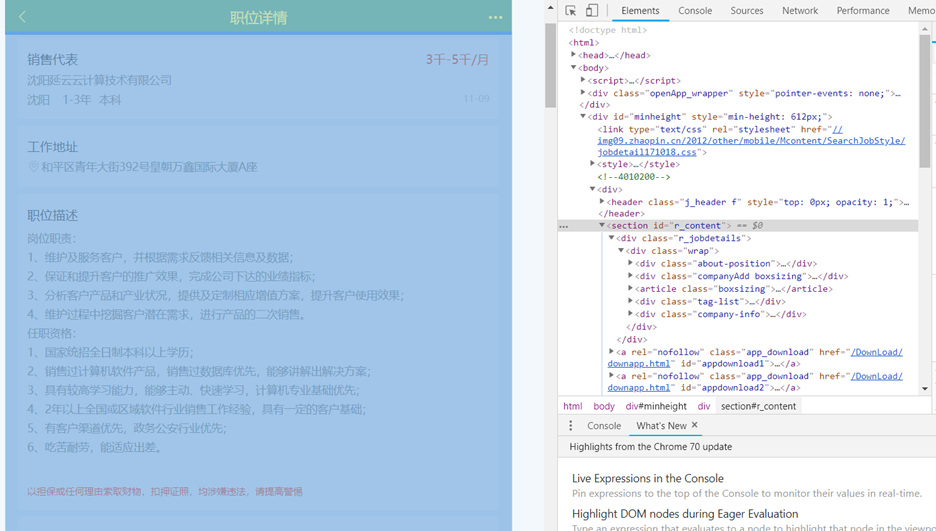
岗位名称、月薪、公司、地区、学历、年限信息都在'//*[@id="r_content"]/div[1]/div/div[1]/div[1]/'下。
-
title = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[1]/h1/text()')
-
pay = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[1]/div[1]/text()')
-
place = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[3]/div[1]/span[1]/text()')
-
campanyName = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[2]/text()')
-
edu = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[3]/div[1]/span[3]/text()')
岗位要求与岗位职责在同一个<div>标签里:
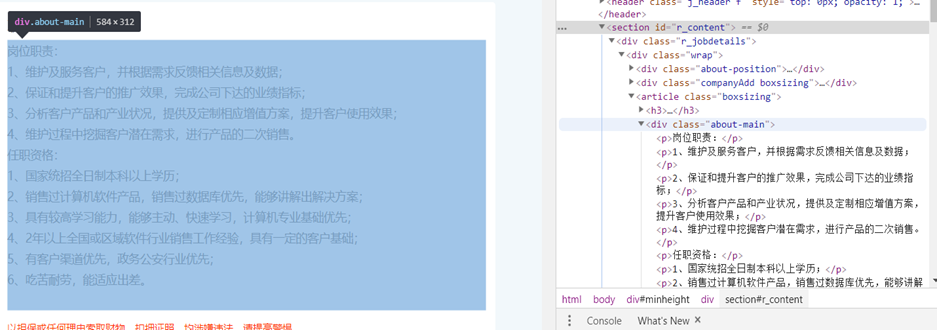
也爬出来:
-
comment = selector.xpath('//*[@id="r_content"]/div[1]/div/article/div/p/text()')
好了,最复杂的部分搞定。
三、JSON数据包地址
我们将前三页的数据包地址比对一下就能看出问题:
-
https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.14571817&x-zp-page-request-id=ce8cbb93b9ad4372b4a9e3330358fe7c-1541763191318-555474
-
https://fe-api.zhaopin.com/c/i/sou?start=60&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.14571817&x-zp-page-request-id=ce8cbb93b9ad4372b4a9e3330358fe7c-1541763191318-555474
-
https://fe-api.zhaopin.com/c/i/sou?start=120&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.14571817&x-zp-page-request-id=ce8cbb93b9ad4372b4a9e3330358fe7c-1541763191318-555474
-
https://fe-api.zhaopin.com/c/i/sou?start=180&pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=%E5%A4%A7%E6%95%B0%E6%8D%AE&kt=3&_v=0.14571817&x-zp-page-request-id=ce8cbb93b9ad4372b4a9e3330358fe7c-1541763191318-555474
1.我们可以看出第一页的url结构与后面的url结构有明显的不同。
2.非首页的url有明显的规律性。
3.'kw=*&kt'里的字符为'大数据'的UTF-8编码。
所以我们对数据包有如下的操作:
-
if __name__ == '__main__':
-
key = '大数据'
-
-
url = 'https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=' + key + '&kt=3&lastUrlQuery=%7B%22pageSize%22:%2260%22,%22jl%22:%22489%22,%22kw%22:%22%E5%A4%A7%E6%95%B0%E6%8D%AE%22,%22kt%22:%223%22%7D'
-
infoUrl(url)
-
-
urls = ['https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&kw='.format(i*60)+key+'&kt=3&lastUrlQuery=%7B%22p%22:{},%22pageSize%22:%2260%22,%22jl%22:%22489%22,%22kw%22:%22java%22,%22kt%22:%223%22%7D'.format(i) for i in range(1,50)]
-
for url in urls:
-
infoUrl(url)
四、源码结构
1、截取整个结果界面的JSON数据包,从中提取出各个招聘栏的url。
2、进入招聘详细信息页面,提取移动端url。
3、进入移动端界面,抓取需要的信息。
五、源码
-
'''''
-
智联招聘——爬虫源码————2018.11
-
'''
-
import requests
-
import re
-
import time
-
from lxml import etree
-
import csv
-
import random
-
-
fp = open('智联招聘.csv','wt',newline='',encoding='UTF-8')
-
writer = csv.writer(fp)
-
'''''地区,公司名,学历,岗位描述,薪资,福利,发布时间,工作经验,链接'''
-
writer.writerow(('职位','公司','地区','学历','岗位','薪资','福利','工作经验','链接'))
-
-
def info(url):
-
res = requests.get(url)
-
u = re.findall('<meta name="mobile-agent" content="format=html5; url=(.*?)" />', res.text)
-
-
if len(u) > 0:
-
u = u[-1]
-
else:
-
return
-
-
u = 'http:' + u
-
-
headers ={
-
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36'
-
}
-
-
res = requests.get(u,headers=headers)
-
selector = etree.HTML(res.text)
-
-
# # 岗位名称
-
title = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[1]/h1/text()')
-
# # 岗位薪资
-
pay = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[1]/div[1]/text()')
-
# # 工作地点
-
place = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[3]/div[1]/span[1]/text()')
-
# # 公司名称
-
companyName = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[2]/text()')
-
# # 学历
-
edu = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[3]/div[1]/span[3]/text()')
-
# # 福利
-
walfare = selector.xpath('//*[@id="r_content"]/div[1]/div/div[3]/span/text()')
-
# # 工作经验
-
siteUrl = res.url
-
workEx = selector.xpath('//*[@id="r_content"]/div[1]/div/div[1]/div[3]/div[1]/span[2]/text()')
-
# # 岗位详细
-
comment = selector.xpath('//*[@id="r_content"]/div[1]/div/article/div/p/text()')
-
writer.writerow((title, companyName, place, edu, comment, pay, walfare, workEx, siteUrl))
-
print(title, companyName, place, edu, comment, pay, walfare, workEx, siteUrl)
-
-
def infoUrl(url):
-
res = requests.get(url)
-
selector = res.json()
-
code = selector['code']
-
if code == 200:
-
data = selector['data']['results']
-
for i in data:
-
href = i['positionURL']
-
info(href)
-
time.sleep(random.randrange(1,4))
-
-
if __name__ == '__main__':
-
key = '大数据'
-
-
url = 'https://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=489&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=' + key + '&kt=3&lastUrlQuery=%7B%22pageSize%22:%2260%22,%22jl%22:%22489%22,%22kw%22:%22%E5%A4%A7%E6%95%B0%E6%8D%AE%22,%22kt%22:%223%22%7D'
-
infoUrl(url)
-
-
urls = ['https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize=60&cityId=489&kw='.format(i*60)+key+'&kt=3&lastUrlQuery=%7B%22p%22:{},%22pageSize%22:%2260%22,%22jl%22:%22489%22,%22kw%22:%22java%22,%22kt%22:%223%22%7D'.format(i) for i in range(1,50)]
-
for url in urls:
-
infoUrl(url)

Ps.因为某些原因,我打算每个月爬取智联招聘、51job的岗位信息一次,源码、优化都会以博客的形式写出来,欢迎关注~
源码地址:智联招聘_爬虫源码

