Facebook AI Research(FAIR)今天宣布发布Tensor Comprehensions,这是一个C++库和数学语言,旨在帮助弥合研究人员和工程师在从事机器学习任务时,在沟通上的差距;研究人员习惯使用数学运算,而工程师则专注在不同的硬件后端运行大规模ML模型的实际需求。
相比其他库,Tensor Comprehensions 的主要不同是对Just-In-Time编译有独特的研究,能够自动按需生成机器学习社区需要的高性能代码。
只需几分钟生成高性能CPU/GPU代码,生产力实现数量级提高
要创建新的高性能机器学习(ML)层,典型的工作流程一般包含两个阶段,时间往往需要好几天乃至数周:
1、首先,一位研究人员在numpy级别的抽象中编写了一个新的层,并将其与像PyTorch这样的深度学习库链接起来,然后在小规模实验中对其进行测试。想法得到验证后,相关的代码,性能需要加快一个数量级才能运行大规模实验。
2、接下来,一位工程师为GPU和CPU编写高效代码,而这又需要:
- 这名工程师需要是高性能计算的专家,这方面人才数量有限
- 这名工程师需要获取上下文,制定策略,编写和调试代码
- 将代码移到后端需要进行一些枯燥但必须完成的任务,例如反复进行参数检查和添加Boilerplate集成代码
因此,在过去的几年中,深度学习社区在很大程度上都依靠CuBLAS,MKL和CuDNN等高性能库来获得GPU和CPU上的高性能代码。不使用这些库提供的原语来进行试验,需要极高的工程水平,这对不少研究人员都构成了很大的挑战。
如果有套件能够将上述过程从几周缩短为几分钟,我们预期,将这样一个套件开源将具有重大实用价值。有了Tensor Comprehensions,我们的愿景是让研究人员用数学符号写出他们的想法,这个符号自动被我们的系统编译和调整,结果就是具有良好性能的专用代码。
在这次发布的版本中,我们将提供:
- 表达一系列不同机器学习概念的数学符号
- 用于这一数学符号的基于Halide IR的C++前端
- 基于Integer Set Library(ISL)的多面体Just-in-Time(JIT)编译器
- 基于进化搜索的多线程、多GPU自动调节器
使用高级语法编写网络层,无需明确如何运行
最近在高性能图像处理领域很受欢迎的一门语言是Halide。Halide使用类似的高级函数语法来描述图像处理流水线,然后在单独的代码块中,明确将其调度(schedule)到硬件上,详细指定运算如何平铺、矢量化、并行和融合。这对于拥有架构专业知识的人来说,是一种非常高效的语言,但对于大多数机器学习从业者却很难使用。目前有很多研究积极关注Halide的自动调度(Automatic scheduling),但对于在GPU上运行的ML代码,还没有很好的解决方案。
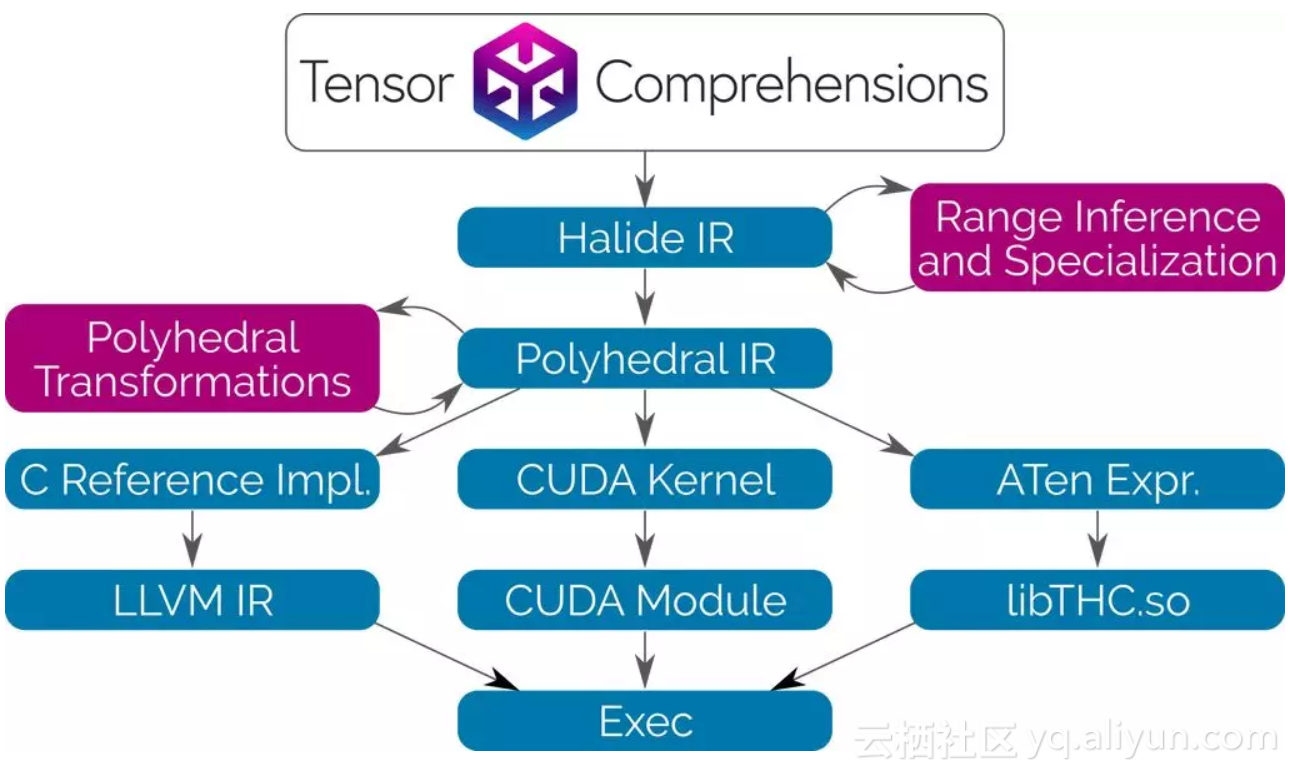
Tensor Comprehensions使用Halide编译器作为库。在Halide的中间表示(IR)和分析工具的基础上,将其与多面体编译技术相结合,使用者可以用类似的高级语法编写网络层,而无需明确它将如何运行。我们还成功使语言更加简洁,无需指定减法(reduction)的循环边界。

Tensor Comprehensions使用Halide和Polyhedral Compilation 技术,自动合成CUDA内核。这种转换会为通用算子融合、快速本地内存、快速减法和JIT类型特化进行优化。由于没有或者没有去优化内存管理,我们的流程可以轻松高效地集成到任何ML框架和任何允许调用C++函数的语言中。
与传统的编译器技术和库的方法相反,多面编译(Polyhedral Compilation)让Tensor Comprehensions为每个新网络按需调度单个张量元素的计算。
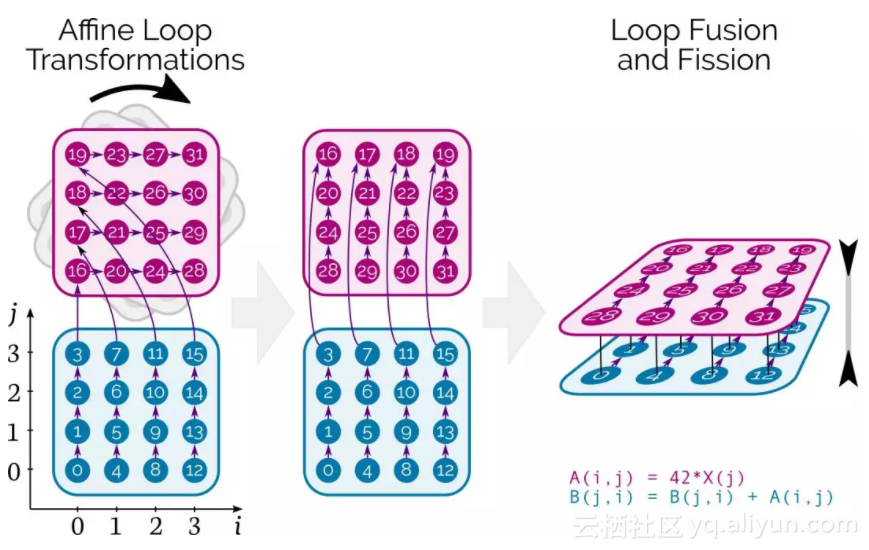
在CUDA层面,Tensor Comprehensions结合了affine loop transformations,fusion/fission和自动并行处理,同时确保数据在存储器层次结构中正确移动。
图中的数字表示最初计算张量元素的顺序,箭头表示它们之间的依赖关系。在这个例子中,数字旋转对应loop interchange,深度算子融合就发生在这个过程中。
性能媲美乃至超越Caffe2+cuBLAS
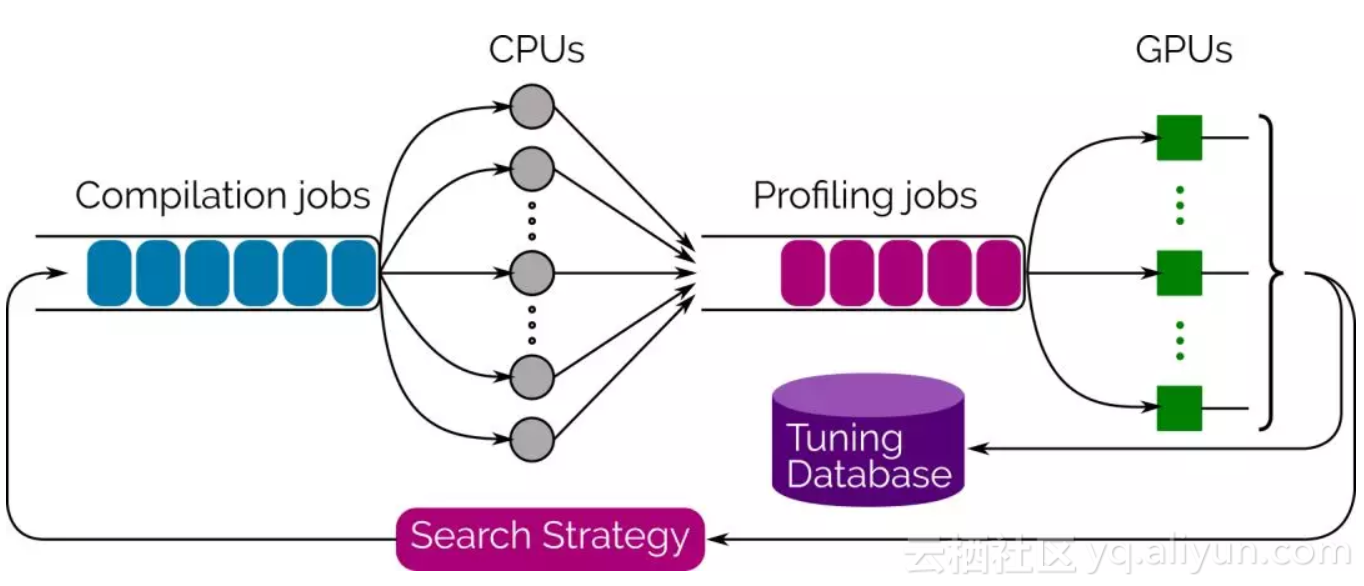
为了推动搜索过程,我们还提供了一个集成的多线程、多GPU自动调谐库(autotuning library),它使用Evolutionary Search来生成和评估数千种实现方案,并从中选择性能最佳的方案。只需调用Tensor Comprehension的tune函数,你就能实时地看着性能提高,到你满意时停止即可。最好的策略是通过protobuf序列化,立即就可重用,或在离线情况下。
在性能方面,尽管我们还有很多需要改进的地方,但在某些情况下,Tensor Comprehensions 已经可以媲美甚至超越当前整合了手动调整库的ML框架。这主要通过将代码生成策略适应特定问题大小的能力来实现的。下面的条形图展示了将Tensor Comprehensions自动生成的内核与Caffe2和ATen(使用CuDNN)相比较时的结果。更多信息,请参阅论文(见文末链接)。
随着我们扩大至更多硬件后端,Tensor Comprehensions将补充硬件制造商(如NVIDIA和Intel)编写的速度很快的库,并将与CUDNN,MKL或NNPack等库一起使用。
未来计划
这次发布的版本将让研究人员和程序员用与他们在论文中使用的数学语言来编写网络层,并简明地传达他们程序的意图。同时,研究人员还能在几分钟之内将他们的数学符号转化成能够快速实施的代码。随着工具链的不断增长,我们预计可用性和性能将会增加,并使整个社区受益。
我们将在稍后发布PyTorch的Tensor Comprehensions集成。
我们感谢与框架团队的频繁交流和反馈,并期待着将这一令人兴奋的新技术带入你最喜爱的ML框架。
FAIR致力于开放科学并与机器学习社区合作,进一步推动AI研究。Tensor Comprehensions(已经在Apache 2.0协议下发布)已经是Facebook,Inria,苏黎世联邦理工学院和麻省理工学院的合作项目。目前工作还处于早期阶段,我们很高兴能够尽早分享,并期望通过社区的反馈来改进它。
原文发布时间为:2018-02-15
本文作者:文强
本文来自云栖社区合作伙伴新智元,了解相关信息可以关注“AI_era”微信公众号

