前言:
本系列文章包括:
1、 理解Hash、Merge、Nested Loop关联策略。
对于性能优化,需要集中处理以下的问题:
1、 为你的环境创建性能基线。
2、 监控现在的性能并发现瓶颈。
3、 解决瓶颈以便得到更好的性能。
一个预估执行计划是描述查询将会如何执行的一个蓝图,而一个实际执行计划就是一个查询执行时实际发生的镜像。通过对比两个执行计划,可以发现查询是否真的按照预估执行计划来执行。
在执行计划中,有一些非常重要的操作符需要清楚:
1、 Join策略:SQLServer有3种策略——哈希、合并、嵌套循环。每种策略都有其优缺点,本章将讲述这部分。
2、 扫描和查找是SQLServer用于读取数据的两种方式,这两种方式在性能优化中是核心概念。将会在下一篇中讲述。
3、 键查找有时候会成为主要的性能问题。因为存储引起必须从非聚集索引中跳到聚集索引,一边找到非聚集索引中的非键值列的值。这样的行为通常很耗时间。
理解哈希、合并、嵌套循环连接策略
SQLServer提供了3中JOIN的策略,它们没有绝对的好和坏之分。
1、 哈希(Hash Join):SQLServer选择哈希关联作为物理操作符,一边对于大容量数据,且未排序或者没有索引时进行查询。两个进程关联起来进行哈希关联,它们为【建立】和【探测】,在【建立】进程中,会从建立输入(即join的左表中,但是可能这个左表会在优化过程中交换位置,使得不一定就是实际上的左表。)读取所有行,然后在内存中创建一个符合关联条件的哈希表。在【探测】进程中,会从探测表(输入的右表)中读取所有的行,并根据关联条件,与之前创建的内存哈希表匹配。
2、 合并(Merge Join):如果关联表中已经排序,SQLServer会选择合并关联。合并关联要求关联条件中最少有一个是已经被排序了的。如果数据量不大的时候,这比哈希关联更加有效,它并不是重负荷关联的方式。
3、 嵌套循环(Nested Loop):在最少两个结果集中,使用嵌套循环会比较有效,这两个结果集中,作为外部表的集合要小,而内部循环结果集具有有效的索引。这种方式不适用于大结果集。
准备工作:
下面将创建两个表,然后看看各种关联方式的执行计划:
USE AdventureWorks
GO
IF OBJECT_ID('SalesOrdHeaderDemo') IS NOT NULL
BEGIN
DROP TABLE SalesOrdHeaderDemo
END
GO
IF OBJECT_ID('SalesOrdDetailDemo') IS NOT NULL
BEGIN
DROP TABLE SalesOrdDetailDemo
END
GO
SELECT *
INTO SalesOrdHeaderDemo
FROM Sales.SalesOrderHeader
GO
SELECT *
INTO SalesOrdDetailDemo
FROM Sales.SalesOrderDetail
GO
步骤:
1、 执行一下查询,并开启执行计划(Ctrl+M):
SELECT sh.*
FROM SalesOrdDetailDemo AS sd
INNER JOIN SalesOrdHeaderDemo AS sh ON sh.salesorderID = sd.salesorderid
GO
2、 然后从执行计划截图中可以看到使用了哈希连接:
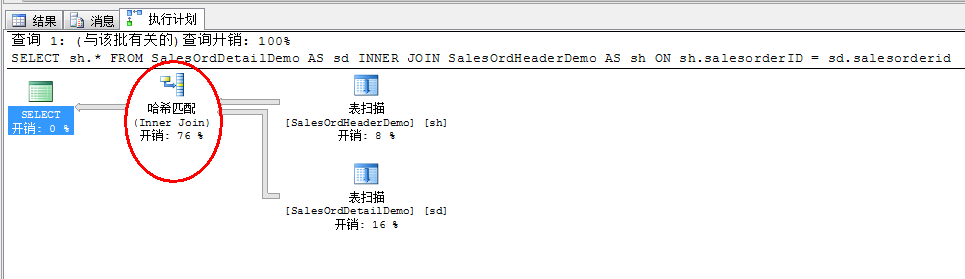
3、 现在先创建唯一的聚集索引在两个表中:
CREATE UNIQUE CLUSTERED INDEX idx_salesorderheaderdemo_SalesOrderID ON salesordheaderdemo(SalesOrderID) GO CREATE UNIQUE CLUSTERED INDEX idx_SalesDetail_SalesOrderID ON SalesOrdDetailDemo(SalesOrderID,SalesOrderDetailID) GO
4、 再次执行步骤1的语句:
5、 截图是第二次执行的执行计划,可以发现变成了合并连接,并且表扫描变成了聚集索引扫描:
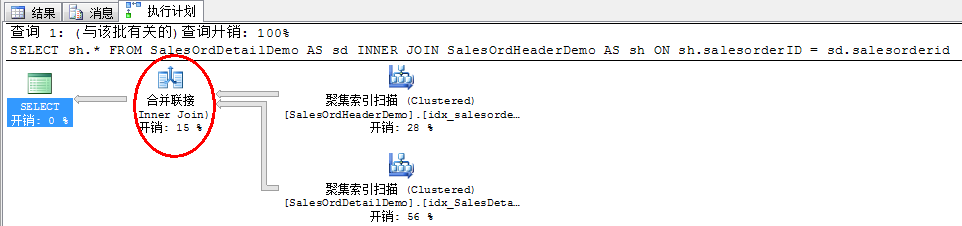
6、 现在来看看嵌套循环关联,在上面的查询中添加where条件来限定查询的结果集:
SELECT sh.*
FROM SalesOrdDetailDemo AS sd
INNER JOIN SalesOrdHeaderDemo AS sh ON sh.salesorderID = sd.salesorderid
WHERE sh.salesorderid = 43659
GO
7、 从执行结果中看到现在关联变成了嵌套循环:
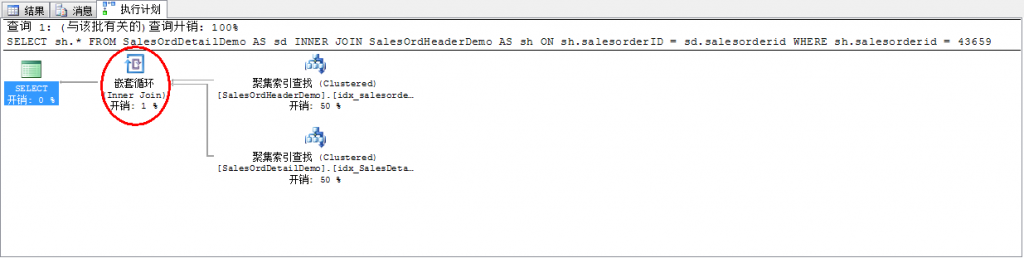
分析:
前面已经提到,哈希关联工作在大数据量且关联字段没有排序的关联中。所以在步骤1中,由于没有索引或者预先排序,数据的关联会使用哈希关联。
在步骤3中,创建了一个唯一的聚集索引,所以表已经通过聚集索引排序了,此时优化器会选择合并关联。
在步骤6中,由于使用了where条件限制数据集的大小,同时由于已经排序,所以使用了嵌套循环关联。
每一种关联方法都有其优缺点,视乎如何优化而已。有时候哈希关联有其非常重要的作用,但是如果可以,强烈建议每个表都应该有一个唯一的聚集索引,一边使用合并关联,如果不可以,千万别尝试使用OPTION提示符来把关联改成合并或者嵌套循环,这可能会降低性能。而嵌套循环仅在小结果集的时候运行的最好。

