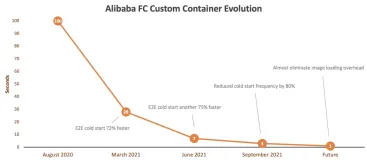
数据中心正在转变为人工智能生产的现代工厂。因此,传统的通用计算正在为加速计算让路也就不足为奇了。

在相当长的一段时间里,数据中心一直处于技术创新和转型的前沿。近年来,他们经历的最重要的变化之一是从通用计算转向加速计算。这种转变是由对更快的处理速度、更高的效率的需求以及处理复杂工作负载(如人工智能、机器学习和大数据分析)的需求驱动的。
长期以来,依赖于传统中央处理器(CPU)的通用计算一直是数据中心的标准。然而,随着数据量和复杂性呈指数级增长,CPU已经难以满足处理需求。这促使人们寻找能够提供更高性能和效率的替代解决方案。
加速计算利用专用硬件,如图形处理单元(GPU)、现场可编程门阵列(FPGA)和专用集成电路(asic),从CPU卸载特定任务。这些加速器旨在更有效地处理并行处理任务,使其成为需要大量计算能力的工作负载的理想选择。
随着人工智能相关应用的持续增长,未来十年,数据中心运营商预计将在加速计算硬件上投入数十亿美元的资本支出。
人工智能需要的计算能力是公共云的三倍。它还需要更多的基础设施和设施。据一家市场研究公司称,到2027年,全球数据中心资本支出预计将增长11%,达到4000亿美元。CPU刷新周期、加速计算和边缘计算是推动这些投资的主要因素。
通过将加速器与传统CPU结合在一起,数据中心可以针对不同类型的任务和应用程序优化其基础设施。
GPU在加速计算中的作用
GPU或图形处理单元在加速计算方面发挥着至关重要的作用,通过利用其并行处理能力来执行比传统CPU更快的复杂计算和任务。GPU最初是为在视频游戏和其他图形密集型应用中渲染图形而设计的,现在已经发展成为科学研究、人工智能、机器学习等领域的宝贵工具。
GPU的架构允许它们同时处理数千个任务,使它们成为可以分解成更小的并行进程的任务的理想选择。这种并行处理能力使GPU能够显著加快数据分析、图像处理、深度学习和模拟等任务的计算速度。例如,Nvidia Hopper是最新一代GPU,专门用于提高加速计算能力。
使用GPU加速计算的关键优势之一是它们能够并行处理大量数据,这可以大大减少处理时间并提高整体性能。这使得GPU在涉及复杂计算和大型数据集的领域不可或缺,使研究人员和开发人员能够更快地获得结果并更有效地利用计算资源。
自适应路由算法需要处理大象流和现代数据中心流量模式的频繁变化。CPU、GPU、DPUs(数据处理单元)和supernic组合成一个加速计算结构,以优化网络工作负载。
加速计算的优点
- 处理速度更快:与传统CPU相比,使用GPU和FPGA等专用硬件的加速计算可以显著加快数据处理任务的速度。
- 能源效率:加速计算也可以比传统的基于CPU的系统更节能。通过将某些计算密集型任务卸载到专门的硬件上,数据中心可以减少电力消耗并降低运营成本。
- 提高性能:加速计算的并行处理能力可以提高特定类型工作负载的性能,例如机器学习、人工智能和数据分析。这可以帮助数据中心向用户提供更快、更可靠的服务。
- 可扩展性:加速计算可以轻松扩展以满足数据中心不断增长的需求。通过添加更多的GPU或其他加速器,数据中心可以提高其处理能力,而无需彻底检修其整个基础设施。
- 节省成本:从长远来看,加速计算可以为数据中心节省成本。通过优化性能和能源效率,数据中心可以降低运营费用并最大化投资回报。
数据中心作为人工智能生产工厂
数据中心是推动人工智能革命的现代工厂,是推动人工智能产生的重要基础设施。大型语言模型(LLM)和生成式人工智能在加速计算中发挥着重要作用,使构建高效、强大的人工智能应用成为可能。这些中心是大型设施,配备了数千台服务器和先进的网络系统,旨在以闪电般的速度处理和处理大量数据。
就像工厂将原材料转化为成品一样,数据中心将原始数据转化为智能洞察和预测。这些中心处理的数据作为驱动人工智能引擎的燃料,使机器能够自主学习、适应和做出决策。通过利用强大的计算资源和复杂的软件框架,数据中心促进人工智能模型在大量数据集上的训练,使它们能够随着时间的推移不断提高其性能和准确性。
此外,作为人工智能生成工厂的数据中心象征着技术与创新的融合,在这里,尖端的硬件和软件结合在一起,突破了可能的界限。从聊天机器人到整个生产设施的自动化,人工智能的机会正在迅速扩大,预计到2030年将增长20倍,达到1.9万亿美元。
从通用计算到加速计算的转变代表了数据中心行业的重大演变。随着组织不断采用新兴技术和数据密集型工作负载,加速计算将在推动数据中心运营的创新、效率和性能方面发挥至关重要的作用。通过利用专业硬件加速器的力量,数据中心可以满足数字时代的需求,并为计算的未来开启新的可能性。