分布式系统详解--框架(Hadoop-集群搭建)
前面的文章也简单介绍了,hadoop的环境搭建分为三种,单机版,伪分布式,全分布式。这篇文章为介绍hadoop的全分布式的架构搭建。
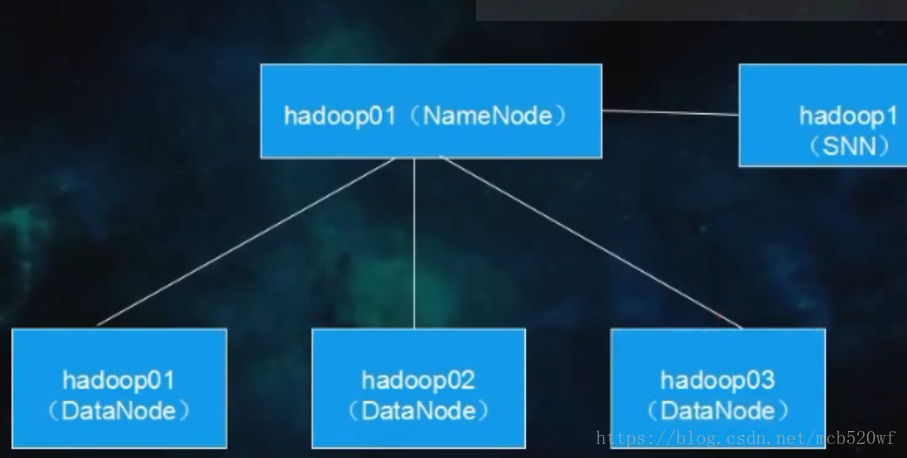
一、步骤总纲

二、搭建规划
| 主机名称 | IP地址 | 功能 |
| MyLinux | 192.168.71.233 | NameNode、DataNode、resourcemanager、nodemanager |
| centos01 | 192.168.71.234 | DataNode、nodemanager |
| centos02 | 192.168.71.235 | DataNode、nodemanager |
三、配置hadoop的相关配置文件
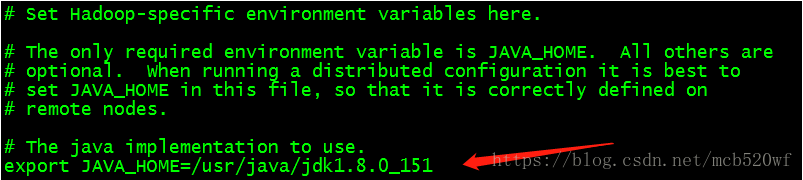
3.1 vi ./etc/hadoop/hadoop-env.sh 告诉hadoop jdk的安装目录。
3.2 vi ./etc/hadoop/core-site.xml
在<configuration></configuration>里面进行配置。
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Mylinudfs-->0</value> </property> <!--配置操作hdfs的缓冲大小--> <property> <name>io.file.buffer.size</name> <value>4096</value> </property> <!--配置临时数据存放目录--> <property> <name>hadoop.tmp.dir</name> <value>/home/bigdata/tmp</value> </property> </configuration>
3.3 vi ./etc/hadoop/hdfs-site.xml
在<configuration></configuration>里面进行配置。
<configuration> <!--副本数也叫副本因子--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--块大小--> <property> <name>dfs.block.size</name> <value>134217728</value> </property> <!--hdfs存储的元数据位置--> <property> <name>dfs.namenode.name.dir</name> <value>/home/hadoopdata/dfs/name</value> </property> <!--hdfs的数据存放位置--> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoopdata/dfs/data</value> </property> <!--hdfs的检测目录--> <property> <name>fs.checkpoint.dir</name> <value>/home/hadoopdata/checkpoint/dfs/cname</value> </property> <!--hdfs的namenode的web ui地址--> <property> <name>dfs.http.address</name> <value>MyLinux:50070</value> </property> <!--hdfs的Secondarynamenode 的web ui地址--> <property> <name>dfs.secondary.http.address</name> <value>MyLinux:50090</value> </property> <!--是否开启web操作hdfs--> <property> <name>dfs.webhdfs.enabled</name> <value>false</value> </property> <!--是否开启hdfs的权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
3.4 vi ./etc/hadoop/mapred-site.xml
因为在 /etc/hadoop/ 下面没有mapred-site.xml 但是有一个 mapred-site.xml.template
先进行拷贝:
mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
在<configuration></configuration>里面进行配置。
<configuration> <!--指定mapreduce的运行框架--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property> <!--历史服务的通讯地址--> <property> <name>mapreduce.jobhistory.address</name> <value>MyLinux:10020</value> </property> <!--历史服务的web ui 通讯地址--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>MyLinux:19888</value> </property> </configuration>
3.5 vi ./etc/hadoop/yarn-site.xml
在<configuration></configuration>里面进行配置。
<configuration> <!--指定resouceManager 所启动的服务主机名--> <property> <name>yarn.resourcemanager.hostname</name> <value>MyLinux</value> </property> <!--指定resouceManager 的shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--指定resouceManager 的内部通信地址 --> <property> <name>yarn.resourcemanager.address</name> <value>MyLinux:8032</value> </property> <!--指定resouceManager的scheduler内部通信地址 --> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>MyLinux:8030</value> </property> <!--指定resouceManager的source-tracker内部通信地址 --> <property> <name>yarn.resourcemanager.source-tracker.address</name> <value>MyLinux:8031</value> </property> <!--指定resouceManager的admin内部通信地址 --> <property> <name>yarn.resourcemanager.admin.address</name> <value>MyLinux:8033</value> </property> <!--指定resouceManager的web ui监控地址 --> <property> <name>yarn.resourcemanager.webapp.address</name> <value>MyLinux:8088</value> </property> </configuration>
3.6 vi ./etc/hadoop/slaves
MyLinux centos01 centos02
四、分发hadoop文件到所有机子上去
4.1 删除其他两台机器的hadoop文件(原来是配置了单机安装)
rm -rf /opt/hadoop-2.7.5
4.2 执行命令复制
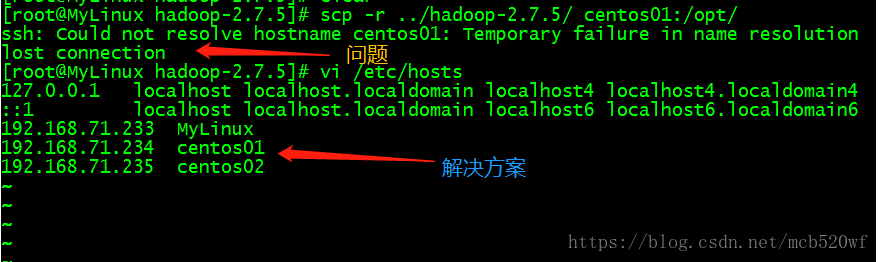
scp -r ../hadoop-2.7.5/ centos01:/opt/
scp -r ../hadoop-2.7.5/ centos02:/opt/
如果出现下面的情况:则需要在/etc/hosts 的文件中添加其他主机IP地址。
五、格式化文件
hadoop namenode -format 成功后
查看文件

六、启动
6.1 启动方式
(1)全启动 start-all.sh
(2)模块启动
start-dfs.sh
start-yarn.sh
(3)单个进程启动
hadoop-daemon.sh start/stop namenode
hadoop-daemons.sh start/stop datanode
yarn-daemon.sh start/stop namenode
yarn-daemons.sh start/stop datanode
mr-jobhistory-daemon.sh start/stop historyserver
6.2 测试模块启动
进入hadoop-2.7.5 输入 ./sbin/start-dfs.sh 要求输入多次密码
(1)进程按照规划出现
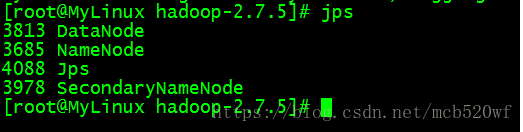
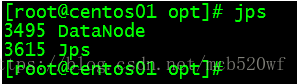
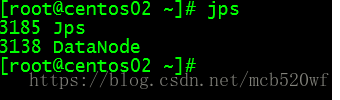
A。输入jps 查看进程分别是 服务器MyLinux、centos01、centos02
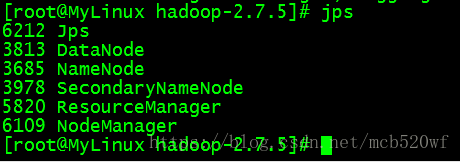
B。在sbin目录下面,启动yarn命令 start-yarn.sh
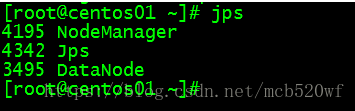
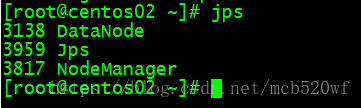
(2)查看对应模块的web ui监控是否正常。192.168.71.233:50070
可以查看网站图示:
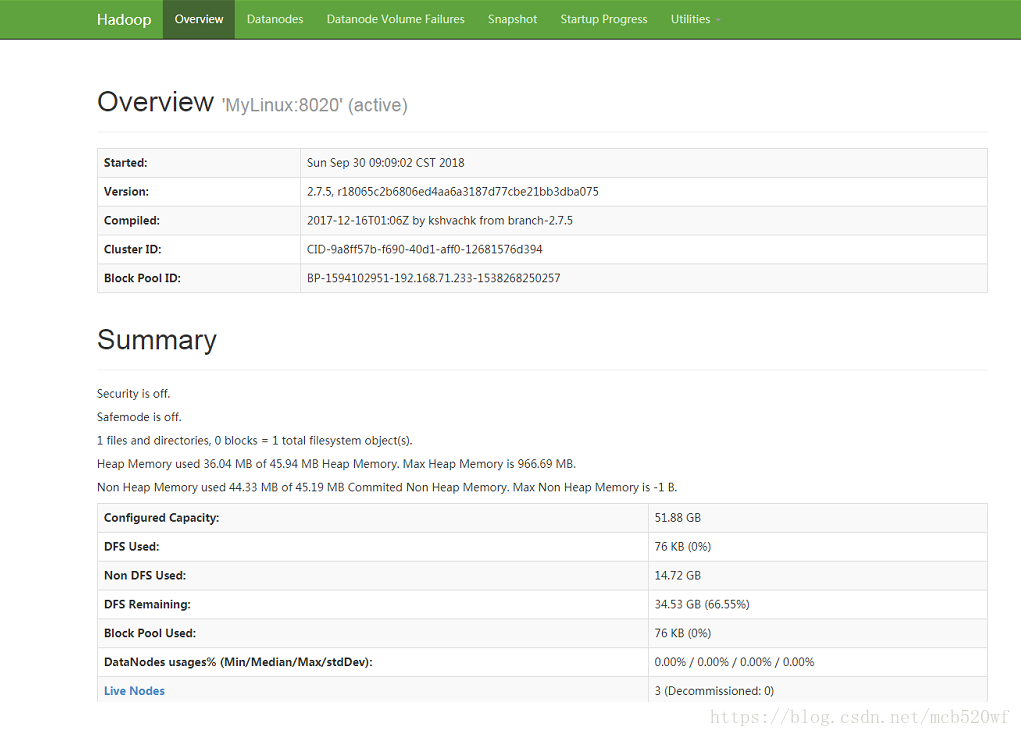
倘若出现该服务器步骤一中,进程均已开启,而在windows下访问该端口却无法访问的情况。进行下面的操作。
第一步:开启防火墙 service iptables start
第二步:关闭防火墙 service iptables stop
(3)检测上传下载文件(hdfs),跑mapreduce作业
A。从任意目录中上传文件到hdfs系统的根目录中。
hdfs dfs -put ./README.txt /
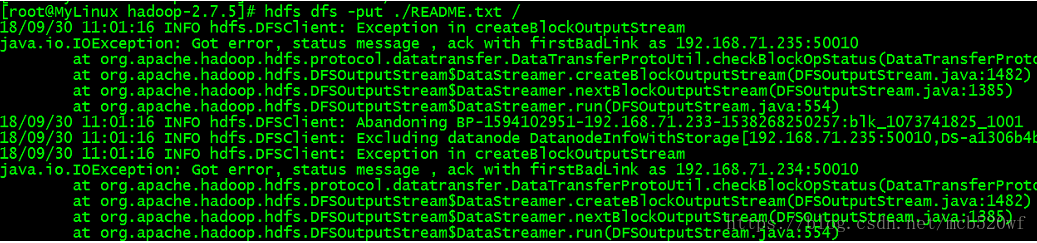
解决方案:关闭datanode的防火墙(所有服务器均关闭)
上传完成
命令 hdfs dfs -cat /README.txt 来查看上传的文件打开详情
命令 hdfs dfs -ls / 来查看该hdfs系统下的文件列表
B。跑一个mapreduce作业查询单词数。
yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar wordcount /README.txt /out/00
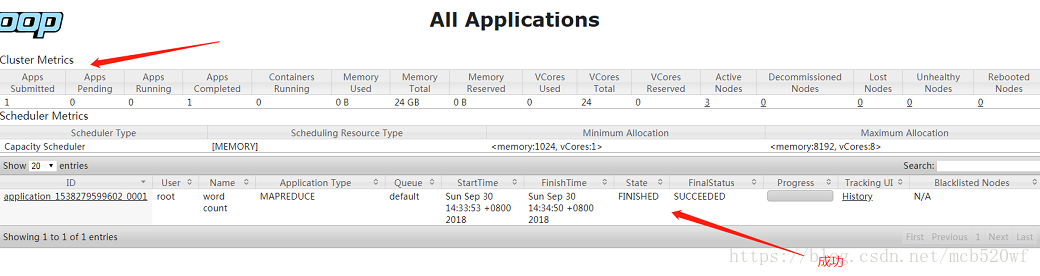
查看命令 hdfs dfs -cat /out/part-r-00000
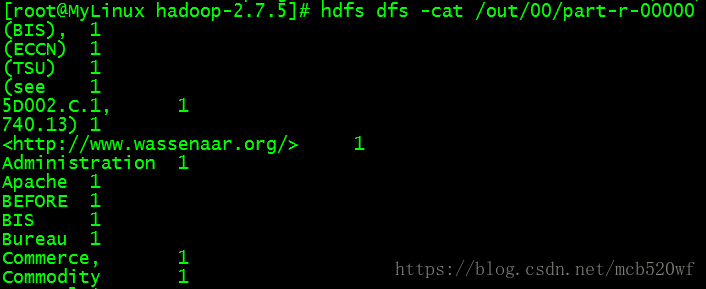
在这里记录了每一个单词的个数,hdfs集群搭建成功。

