作为一名Python程序员,我天天跟数据打交道,数据一多,传统的处理方式就有点儿力不从心。EMR Serverless Spark的出现,对我来说就像找到了一把屠龙刀,终于可以大干一场了。
第一章:安装与配置,轻松上手
安装配置这块,阿里云的文档写得是真清楚,跟着步骤一步步来,一点儿也不费劲。不过,一开始找入口的时候,我确实绕了点弯路,但熟悉了之后,就轻车熟路了。
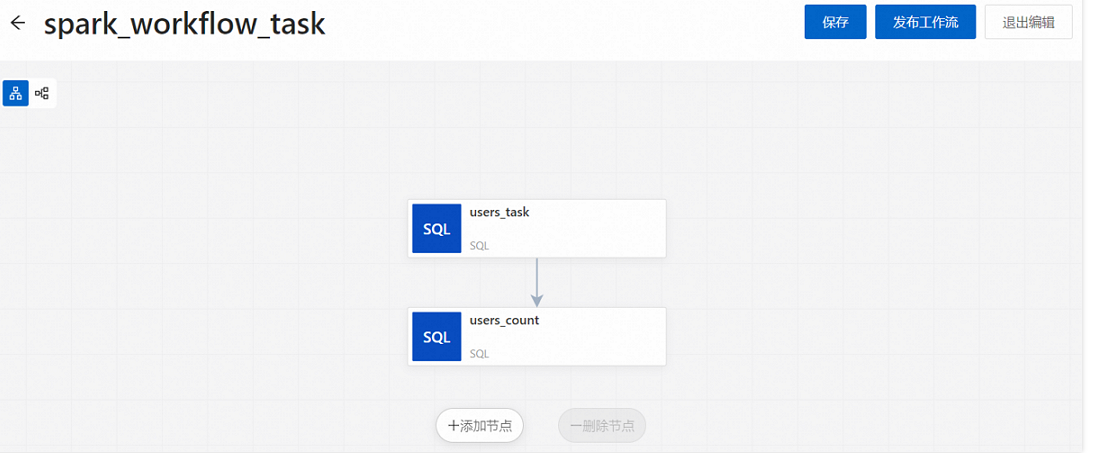
第二章:数据处理实践,大展拳脚
- 数据接入:我试了试从OSS拉数据,速度嗖嗖的,比我那破笔记本快多了,简直就像坐了火箭。
- 任务开发:用PySpark写任务,熟悉的感觉,就像写Python脚本一样顺手。我写了一个处理日志数据的脚本,运行起来飞快,效果杠杠的。
- 作业调度:设置了几个定时任务,EMR Serverless Spark的调度器稳得一批,从没掉过链子,让我省心不少。
第三章:性能与稳定性,稳如老狗
性能这块,EMR Serverless Spark真是没得说,比我之前用过的那些破烂集群强多了。稳定性也是杠杠的,跑了一个月,稳如老狗,从来没给我掉过链子。
第四章:运维体验,省事省心
以前运维Spark集群,那叫一个心累。现在好了,全托管,啥也不用管,省了不少心。就像找了个贴心管家,啥事都给你安排得明明白白。
第五章:成本与收益,精打细算
按需付费,这模式我喜欢。不像以前,还得自己买机器,成本高得吓人。现在,用多少花多少,收益也上来了,这账算得门儿清。
第六章:产品功能体验,面面俱到
- 接入便捷性:接入数据源挺方便,支持多种数据格式,这点做得不错,让我少操了不少心。
- 数据开发体验:写Spark任务跟写Python一样,开发效率高,这点深得我心。我还尝试了一些复杂的数据处理逻辑,都能轻松应对。
- 弹性伸缩:资源自动扩展,用起来很灵活。我试了试在高负载下的表现,扩展得很及时,没有出现性能瓶颈。

第七章:改进建议
- 问题诊断:有时候任务挂了,找原因得费点劲,希望日志能更详细些。最好能有个智能诊断系统,一键定位问题所在。
- 自动化功能:要是能自动优化查询计划,自动调整资源分配,那就更完美了。我尝试了一些复杂的查询,如果能自动优化,效率会更高。
第八章:联动效应,打造数据处理闭环
EMR Serverless Spark跟阿里云的其他产品,比如MaxCompute、DataWorks,如果能联动起来,那就真能打造个数据处理的闭环了。我试了试和DataWorks的集成,确实方便不少,如果能进一步扩展,那就更牛了。

第九章:性能不错
EMR Serverless Spark这货,用起来真挺爽。性能好,稳定性高,运维省事,成本还低。问题诊断这块儿还得加强。总之,值得一试。
第十章:总结发言
1、EMR Serverless Spark服务最佳实践测评:
我最喜欢的就是它能和各种数据源结合,不管是用户行为分析还是大规模数据处理,都能轻松应对。就像写Python脚本一样,我只需要把数据扔进去,它就能帮我分析出有价值的信息。
稳定性和性能方面,EMR Serverless Spark表现得相当出色。相比其他引擎和自建Spark集群,它省去了一大堆运维的麻烦,让我能更专注于数据分析本身。
作为全托管的服务,EMR Serverless Spark在成本和收益上也给了我很大的惊喜。它按需付费,不用自己维护硬件,成本更低;而且计算效率高,收益自然也就上来了。
2、EMR Serverless Spark服务体验评测:
体验过程中,产品内引导和文档帮助做得挺到位,让我很快就上手了。但对于一些高级功能,我觉得还可以增加更多的示例和教程。
产品功能基本满足了我的预期,接入便捷,数据开发体验流畅,弹性伸缩也很灵活。不过,我觉得在一些特定业务场景下,还可以进一步优化。
对于业务场景,我觉得EMR Serverless Spark还可以增加一些自动化的功能,比如自动优化查询计划,自动调整资源分配等。
EMR Serverless Spark和其他产品的联动组合可能性很大,比如和阿里云的数据分析产品、数据可视化工具等结合,打造一个完整的数据处理和分析解决方案。
3、LAP引擎的对比测评:
我之前用过一些Spark引擎,商业的和开源的都有。EMR Serverless Spark在满足业务需求方面,功能全面,性能出色,可扩展性强,多协议支持,效率也很高。
我觉得EMR Serverless Spark好的地方在于它的全托管特性,省去了运维的麻烦;而且它的多租户隔离和安全性也做得很好。不过,在问题诊断方面,我觉得还可以进一步优化,比如提供更详细的日志和监控数据。
EMR Serverless Spark作为一款云原生的Serverless Spark计算产品,它在数据处理和分析方面给了我很大的帮助。它简化了数据处理的流程,提高了效率,降低了成本,让我能更专注于数据的价值提炼。有兴趣的话,不妨来体验一下,看看它能不能成为你数据处理的得力助手。




