Spark是一个基于内存的通用数据处理引擎,可以进行大规模数据处理和分析。它提供了高效的数据存储、处理和分析功能,支持多种编程语言和数据源,包括Hadoop、Cassandra、HBase等。
Spark具有以下特点:
高效性:Spark使用内存计算技术,可以快速地进行数据处理和分析,比传统的磁盘读写方式更加高效。
易用性:Spark提供了简洁的API和丰富的库,可以方便地进行数据处理和分析,同时支持多种编程语言,如Java、Scala、Python等。
可扩展性:Spark可以在集群中运行,支持水平扩展,可以根据需要增加或减少节点数量,以满足不同的数据处理需求。
容错性:Spark具有自动容错机制,可以保证数据处理过程中的稳定性和可靠性。
多样性:Spark支持多种数据源和格式,可以处理结构化和非结构化数据,包括文本、图像、视频等。
总之,Spark是一个功能强大、高效、易用的数据处理引擎,适用于大规模数据处理和分析任务。
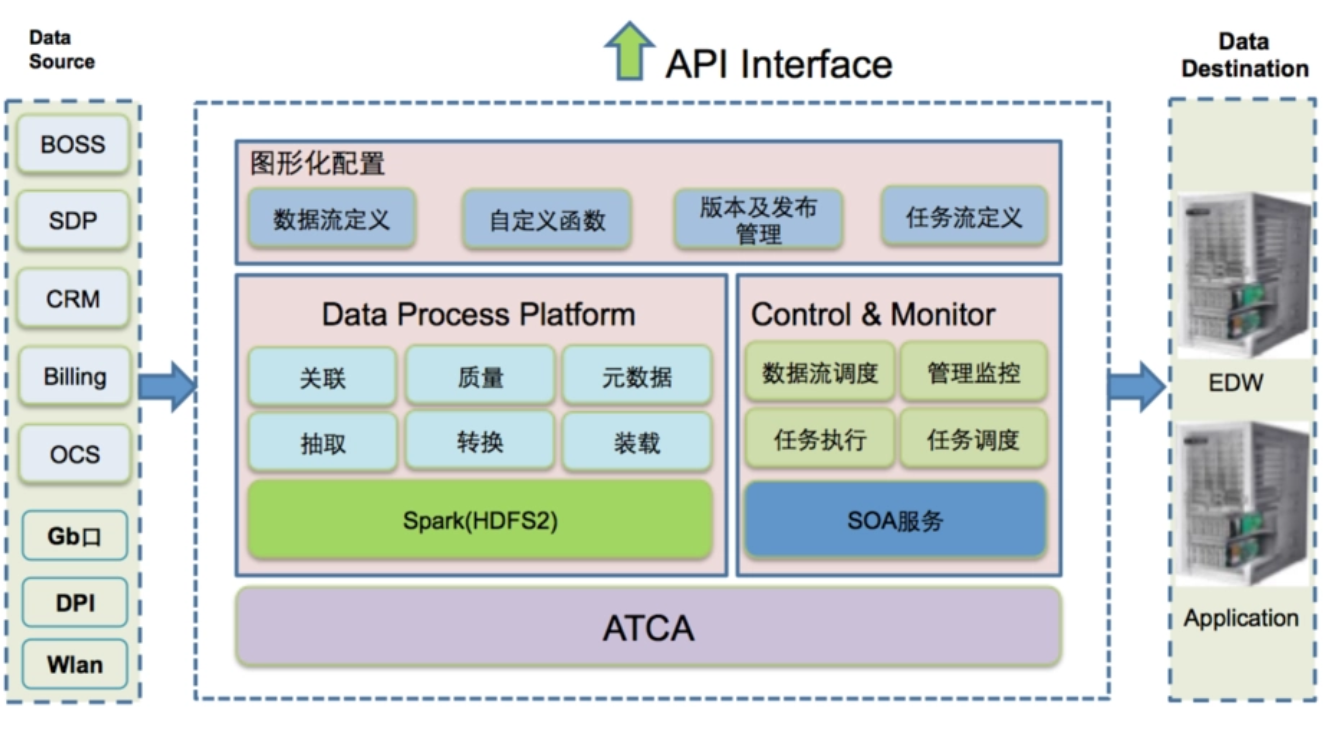
Spark的主要应用场景包括复杂的批量处理、交互式查询、流处理、机器学习和图计算等。具体如下:
- 复杂批量处理:Spark能够处理大量数据,适用于需要处理海量数据的场合,即使处理速度相对较慢,通常在数十分钟到数小时之间也是可以接受的。
- 交互式查询:与传统的数据仓库相比,Spark提供了更快的查询响应时间,适合需要快速数据分析的场景。
- 流处理:Spark Streaming允许实时处理数据流,这对于需要快速分析和响应的应用场景非常有用。
- 机器学习:Spark的MLlib库提供了多种机器学习算法,适合需要执行复杂数据挖掘和分析的任务。
- 图计算:GraphX是Spark中用于图计算的库,支持大规模的图处理任务。
综上所述,Spark因其高效、灵活和易扩展的特点,被广泛应用于大数据分析、实时数据处理、机器学习等领域。