1.算法仿真效果
matlab2022a仿真结果如下: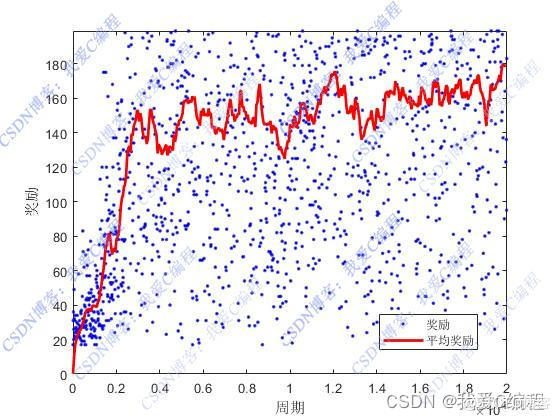
2.算法涉及理论知识概要
基于Q-learning的强化学习方法应用于小车倒立摆控制系统,是通过让智能体(即控制小车的算法)在与环境的交互过程中学习到最优的控制策略,以保持倒立摆在不稳定平衡状态下的直立。Q-learning作为一种无模型的强化学习算法,特别适合解决这类动态环境下的决策问题。
Q-learning的核心在于学习一个动作价值函数Q(s,a),该函数衡量了在状态s下采取行动a后,预期累积奖励的总和。其更新规则为:

小车倒立摆系统由一个小车和其上一根可自由摆动的杆组成,目标是通过控制小车在水平轨道上的移动,使摆杆维持在直立状态。系统状态通常由小车位置x、小车速度v、摆杆角度θ以及摆杆角速度˙θ˙来描述,即s=(x,v,θ,θ˙)。
在倒立摆控制系统中,动作空间通常定义为小车的加速度或力的大小,记作a。每一步,智能体基于当前状态st选择一个动作at,并观察到新的状态st+1和即时奖励rt+1。奖励设计是关键,一般而言,当摆杆接近直立且小车稳定时给予正奖励,反之则给予负奖励或惩罚。
当状态空间或动作空间非常大时,直接使用表格方法不可行,此时引入函数近似来估算Q值。假设有一个函数近似器Q(s,a∣θ),其中θ是参数向量,更新规则变为梯度上升形式:

在深度Q-learning(DQN)中,通常使用深度神经网络作为Q函数的近似器,利用经验回放和固定目标网络来稳定学习过程。
3.MATLAB核心程序
```。。。。。。........................................................% 时间步循环
for t = 1:Times
t
% 更新j
idj = NewState;
% 策略:使用贪婪方法定义动作
[~,idi] = max(Qtable(idj,:));
A = action(idi);
% 更新状态
[State,Reward,~] = func_model(State,A);
% 量化连续状态以提取下一个状态索引
NewState = func_idx(State,Cars); % extract state index
ha = gca(h2);
%车位置和杆角度
x = State(1);
theta = State(3);
Car_show1 = findobj(ha,'Tag','Car_show1');
Car_show2 = findobj(ha,'Tag','Car_show2');
% 更新车和杆的位置
[Xcar,~] = centroid(Car1);
[Xp,Yp] = centroid(Car_show3);
dx = x - Xcar;
thetad = theta - atan2(Xcar-Xp,Yp-0.25/2);
Car1 = translate(Car1,[dx,0]);
Car_show3 = translate(Car_show3,[dx,0]);
Car_show3 = rotate(Car_show3,rad2deg(thetad),[x,0.25/2]);
Car_show1.Shape = Car1;
Car_show2.Shape = Car_show3;
pause(0.02)
end
0Z_004m
```
