近期公司有一个需求,将设备导出的温度数据,使用线上的方式进行分析,取代原先使用Excel的方式分析查看图表,看了python的streamlit web框架,符合此次开发需求,可以快速开发
1.数据分析思路
查看分析设备数据
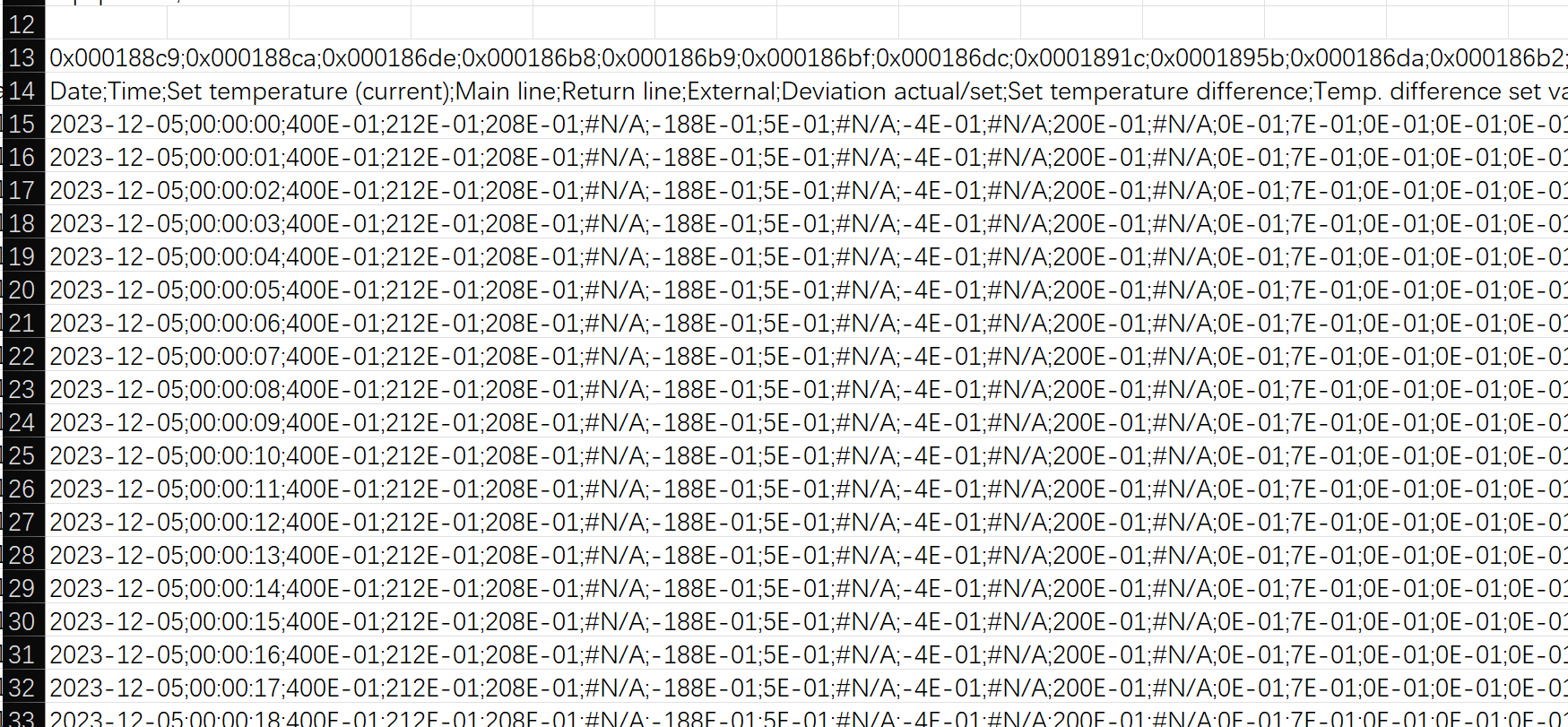
设备导出的数据为CSV文件,从第14行开始为温度数据,数据使用科学计数表示,数据之间使用“逗号分隔”,数据组织较为简单
2.程序开发思路
根据对CSV温度数据的分析,如此我们可以使用“pandas”库来读取所有数据,并将科学计数的数据转换为10进制表示,将转换完的数据使用图表matplotlib库展示出来即可,
3.开发
import streamlit as st
import pandas as pd
from dataprocessing import dataprocessing,datatimeSubdatatime,max_min_avg_stand
import matplotlib.pyplot as plt
import streamlit as st:导入streamlit 框架包,
import pandas as pd:读取分析CSV数据
from dataprocessing import dataprocessing,datatimeSubdatatime,max_min_avg_stand:分析时间,分析数据取最大值最小值等
import matplotlib.pyplot as plt:图表显示库
3.1 主要程序
根据对CSV文件的分析,我们使用Python中的列表存储数据,方便我们对数据进行筛选
#开始处理CSV文件并显示
# 读取CSV文件
my_bar = st.progress(0)
my_bar.progress(10, text="开始读取CSV文件")
data = pd.read_csv(uploaded_files, encoding='utf16', skiprows=13)
# 获取行数
lines = data.values.shape
print(lines)
# 提取第一行数据并去除分号
infolist = []
my_bar.progress(12, text="开始分析CSV文件")
for i in range(lines[0]):
newinfolist = []
cleaned_data = str(data.values[i][0]).split(';')
# 打印清洗后的数据
# HB时间
HBdata = f"{cleaned_data[0]}:{cleaned_data[1]}"
# 设定温度(电流)
temperature = dataprocessing(cleaned_data[2])
# 正线
Mainline = dataprocessing(cleaned_data[3])
# 回流管
Returnline = dataprocessing(cleaned_data[4])
# 流量
Flowrate = dataprocessing(cleaned_data[11])
# 系统压力
Systempressure = dataprocessing(cleaned_data[14])
# 调节比率
Regulationratio = dataprocessing(cleaned_data[9])
# 设定值系统压力
Setvaluesystempressure = dataprocessing(cleaned_data[13])
# 泵压差
Pumppressuredifferential = dataprocessing(cleaned_data[16])
newinfolist.append(HBdata)
newinfolist.append(temperature)
newinfolist.append(Returnline)
newinfolist.append(Flowrate)
newinfolist.append(Systempressure)
newinfolist.append(Mainline)
newinfolist.append(Regulationratio)
newinfolist.append(Setvaluesystempressure)
newinfolist.append(Pumppressuredifferential)
infolist.append(newinfolist)
数据展示示例
['2023-07-06:21:52:03', 40.0,39.3, 10.0, 0.7, 38.6, 0.7, 0, 0.1]
有了列表组成的数据,那么我们对其进行找出最大值最小值就容易多了
如求出最大值,下面这个函数,将我们需要分析的列表数据的索引传到里面,并将所有数据也传进去,将返回最大值,最小值等
Settempervalue = max_min_avg_stand(1,infolist)
def max_min_avg_stand(index:int,infolist):
# 计算每个子列表中第二个元素的最大值
max_values = max(sublist[index] for sublist in infolist)
# 计算每个子列表中第二个元素的最小值
min_values = min(sublist[index] for sublist in infolist)
# 计算平均值
average_value = sum(sublist[index] for sublist in infolist) / len(infolist)
# 提取第二个元素到一个列表中
second_elements = [sublist[index] for sublist in infolist]
# 计算标准差
standard_deviation = np.std(second_elements)
# 输出结果
return [max_values, min_values, average_value,standard_deviation]
还需要实现一个功能,就是人员选择什么就是就在图表中显示什么数据,
那么我们使用streamlit框架创建一个多选框,多选框会返回一个数据,包含索引和“”列名
options = st.multiselect(
'请选择需要查看的数据',
['Set temperature(current)', 'Return line', 'Flow rate', 'System pressure', 'Main line', 'Regulation ratio',
'Set value system pressure', 'Pump pressure differential'],
['Set temperature(current)'])
我们再次声明一个空列表,将选择的数据名称放入其中,已便后续对已选择的数据做判断
for count in range(len(options)):
optionslist.append(options[count])
判断已选择的数据是否存在,存在则在图表中创建相关数据图
if "Set temperature(current)" in optionslist:
ax.plot(xlist, ylist, color='#000000', label='Set temperature(current)')
至此,主要代码逻辑完成
展示效果:地址:Streamlit (mgghbcsv.streamlit.app)
全部代码地址:GitHub - yigedaigua/MGHB: 这是一个通过python Steamlit框架开发的HB模温机数据分析Web
4.部署
官方提供了免费的部署,速度还行,
需要注意:
需要将代码上传至GitHub,并在代码中包含requirements.txt所有依赖信息,
使用命令“pip freeze > requirements.txt”生成
