面壁小钢炮 MiniCPM 系列,再次推出超强端侧多模态模型 MiniCPM-Llama3-V 2.5,且支持 30+ 多种语言
- 端侧多模态综合性能:超越多模态巨无霸 Gemini Pro 、GPT-4V
- OCR 能力 SOTA!9 倍像素更清晰,难图长图长文本精准识别
- 图像编码快 150 倍!首次端侧系统级多模态加速
随着大模型参数愈益降低、端侧算力愈益增强,高性能端侧模型势头强劲。而手机、PC等智能终端设备因其高频的影像视觉处理需求,对在端侧部署AI模型提出了更高的多模态识别与推理能力要求。
从面壁「小钢炮」三月三级跳的迅猛进化来看,推动推理成本大幅降低、大模型高效落地,胜利在望!
➤ MiniCPM-Llama3-V 2.5 开源地址:
🔗 https://github.com/OpenBMB/MiniCPM-V
➤ MiniCPM 系列开源地址:
🔗 https://github.com/OpenBMB/MiniCPM
OCR 能力SOTA
MiniCPM-Llama3-V 2.5 以 8B 端侧模型参数量级,贡献了惊艳的 OCR(光学字符识别)SOTA 成绩,以及端侧模型中的优秀多模态综合成绩与幻觉能力水平。

模型雷达图显示 MiniCPM-Llama3-V 2.5 综合能力水平全面优秀
OCR(光学字符识别)是多模态大模型最重要的能力之一,也是考察多模态识别与推理能力的硬核指标。新一代 MiniCPM-Llama3-V 2.5 在 OCR 综合能⼒权威榜单 OCRBench 上,越级超越了 GPT-4o、GPT-4V、Claude 3V Opus、Gemini Pro 等标杆模型,实现了性能 SOTA。
在评估多模态大模型性能可靠性的重要指标——幻觉能力上,MiniCPM-Llama3-V 2.5 在 Object HalBench 榜单上超越了 GPT-4V 等众多模型(注:目标幻觉率应为 0)。
在旨在评估多模态模型的基本现实世界空间理解能力的 RealWorldQA 榜单上,MiniCPM-Llama3-V 2.5 再次超越 GPT-4V 和 Gemini Pro,这对 8B 模型而言难能可贵。
模型体验
体验链接:
https://modelscope.cn/studios/OpenBMB/MiniCPM-Llama3-V-2_5-int4-demo
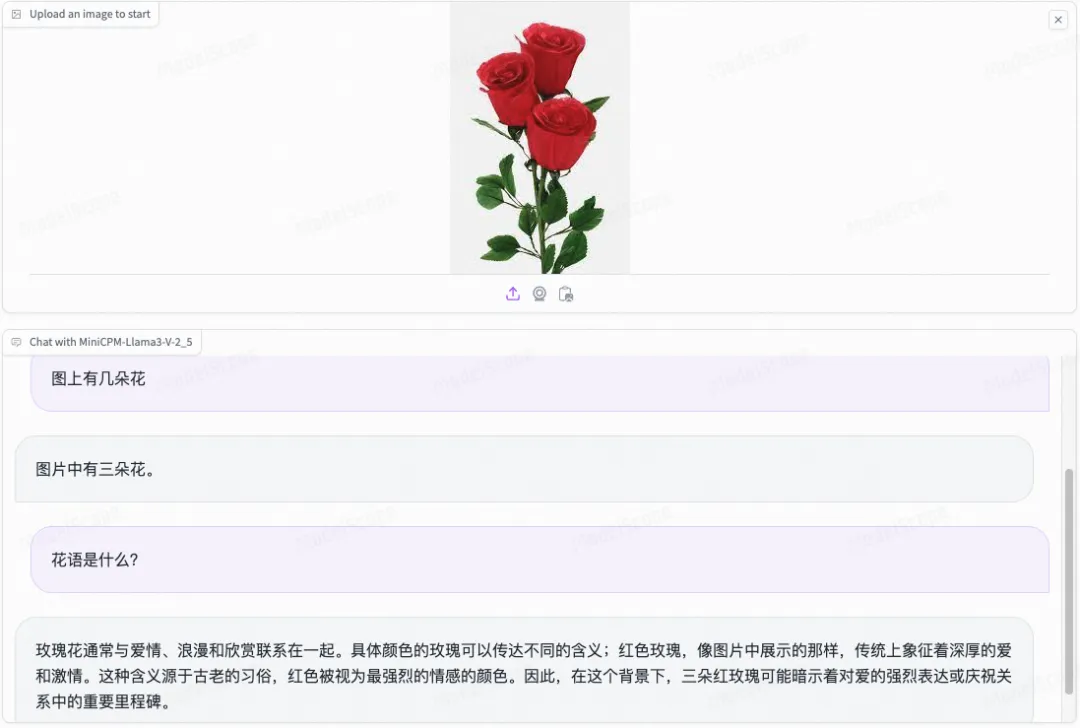
数数和图片理解:
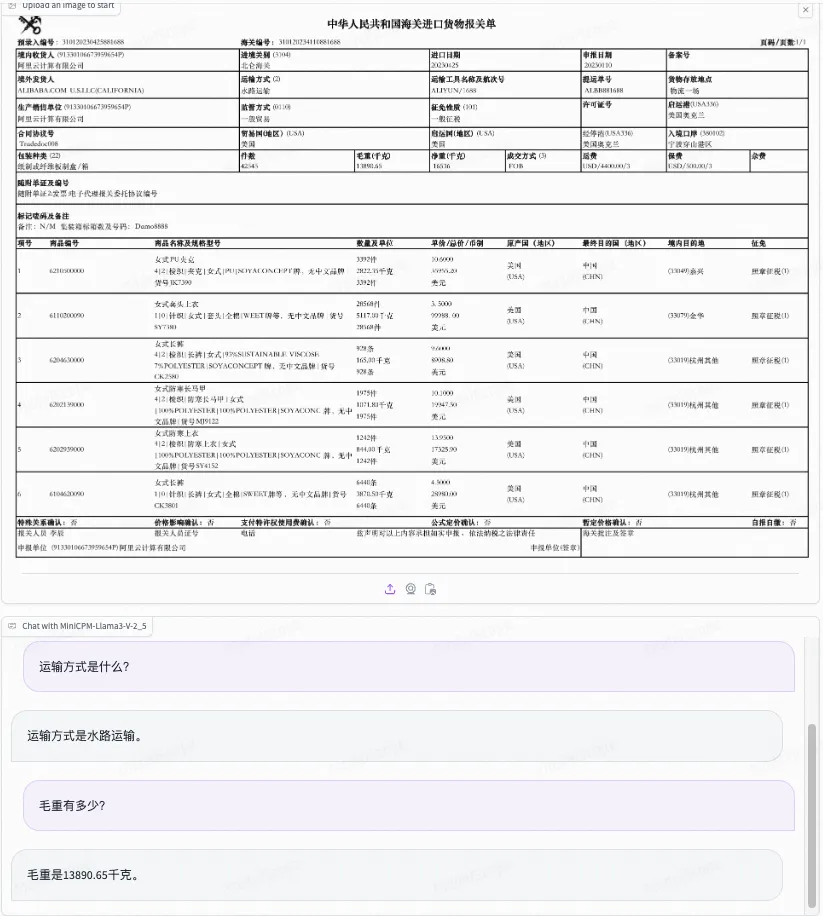
海关报关单识别和实体抽取:
模型下载
模型链接:
MiniCPM-Llama3-V-2_5 [端侧可用]:https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5
MiniCPM-Llama3-V-2_5-int4:https://modelscope.cn/models/OpenBMB/MiniCPM-Llama3-V-2_5-int4
模型下载:
from modelscope import snapshot_download model_dir = snapshot_download("OpenBMB/MiniCPM-Llama3-V-2_5-int4")
模型推理
环境配置和安装:
- python 3.10及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上
本文在魔搭社区免费提供的GPU免费算力上体验:
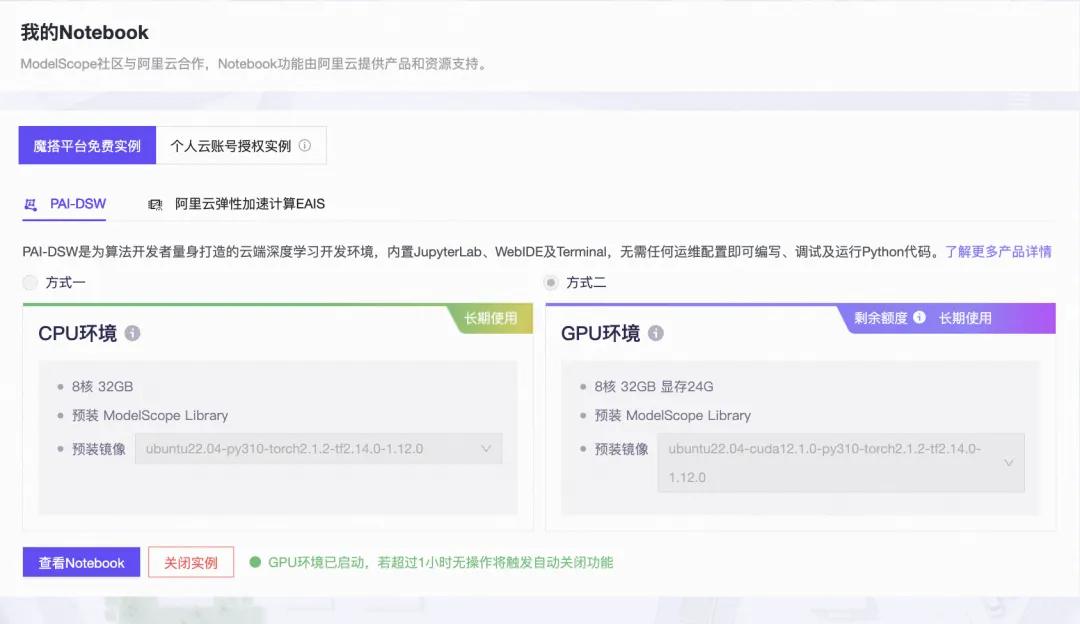
仅需8G显存,推理MiniCPM-Llama3-V-2_5-int4
环境依赖:
!pip install transformers -U
推理代码:
# test.py import torch from PIL import Image from modelscope import AutoModel, AutoTokenizer model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5-int4', trust_remote_code=True) tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5-int4', trust_remote_code=True) model.eval() image = Image.open('/mnt/workspace/玫瑰.jpeg').convert('RGB') question = 'how many flowers in the image?' msgs = [{'role': 'user', 'content': question}] res = model.chat( image=image, msgs=msgs, tokenizer=tokenizer, sampling=True, temperature=0.7 ) print(res)
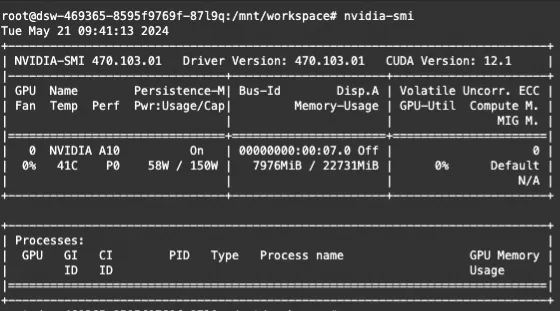
显存占用:
模型微调
我们将使用swift来对MiniCPM-Llama3-V-2_5进行微调。swift是魔搭社区官方提供的大模型与多模态大模型微调推理框架。swift开源地址:https://github.com/modelscope/swift
swift对MiniCPM-Llama3-V-2_5推理与微调的最佳实践可以查看:https://github.com/modelscope/swift/blob/main/docs/source/Multi-Modal/minicpm-v-2.5%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5.md
通常,多模态大模型微调会使用 自定义数据集 进行微调。在这里,我们将展示可直接运行的demo。我们使用 coco-mini-en-2 数据集进行微调,该数据集的任务是对图片内容进行描述。您可以在 modelscope 上找到该数据集:https://modelscope.cn/datasets/modelscope/coco_2014_caption/summary
在开始微调之前,请确保您的环境已准备妥当。
git clone https://github.com/modelscope/swift.git cd swift pip install -e .[llm]
LoRA微调脚本如下所示。该脚本将只对LLM部分的qkv进行lora微调,如果你想对所有linear含vision模型部分都进行微调,可以指定--lora_target_modules ALL。该模型支持全参数微调。
# Experimental environment: A100 # 32GB GPU memory CUDA_VISIBLE_DEVICES=0 swift sft \ --model_id_or_path OpenBMB/MiniCPM-Llama3-V-2_5 \ --dataset coco-en-2-mini \
如果要使用自定义数据集,只需按以下方式进行指定:
# val_dataset可选,如果不指定,则会从dataset中切出一部分数据集作为验证集 --dataset train.jsonl \ --val_dataset val.jsonl \
自定义数据集支持json和jsonl样式。MiniCPM-Llama3-V-2_5支持多轮对话,但总的对话轮次中需包含一张图片, 支持传入本地路径或URL。以下是自定义数据集的示例:
{"query": "55555", "response": "66666", "images": ["image_path"]} {"query": "eeeee", "response": "fffff", "history": [], "images": ["image_path"]} {"query": "EEEEE", "response": "FFFFF", "history": [["AAAAA", "BBBBB"], ["CCCCC", "DDDDD"]], "images": ["image_path"]}
微调后推理脚本如下,这里的ckpt_dir需要修改为训练生成的checkpoint文件夹:
# Experimental environment: A10, 3090, V100, ... # 20GB GPU memory CUDA_VISIBLE_DEVICES=0 swift infer \ --ckpt_dir output/minicpm-v-v2_5-chat/vx-xxx/checkpoint-xxx \ --load_dataset_config true \
你也可以选择merge lora并进行推理:
CUDA_VISIBLE_DEVICES=0 swift export \ --ckpt_dir output/minicpm-v-v2_5-chat/vx-xxx/checkpoint-xxx \ --merge_lora true CUDA_VISIBLE_DEVICES=0 swift infer \ --ckpt_dir output/minicpm-v-v2_5-chat/vx-xxx/checkpoint-xxx-merged \ --load_dataset_config true
微调过程的loss可视化:(由于时间原因,这里只微调了400个steps)
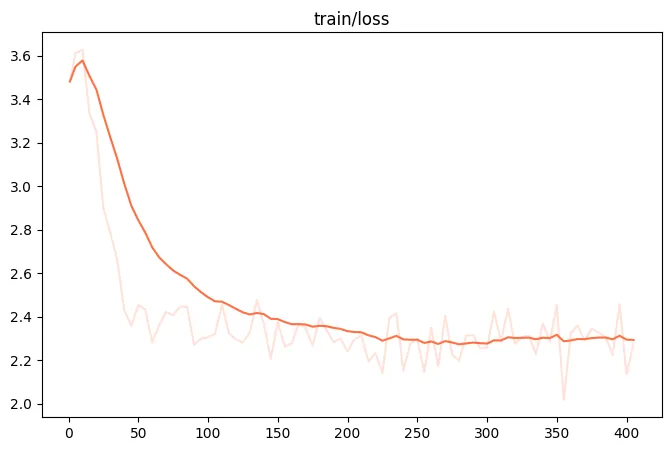
微调后模型对验证集进行推理的示例:

[PROMPT]<|begin_of_text|><|start_header_id|>user<|end_header_id|> <image>[128002 * 96]</image><slice><image>[128002 * 96]</image><image>[128002 * 96]</image></slice> please describe the image.<|eot_id|><|start_header_id|>assistant<|end_header_id|> [OUTPUT]A green plate topped with two sandwiches and a fork.<|eot_id|> [LABELS]A green white with a sandwich on top of it. [IMAGES]['https://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/coco/2014/val2014/COCO_val2014_000000026676.jpg']

[PROMPT]<|begin_of_text|><|start_header_id|>user<|end_header_id|> <image>[128002 * 96]</image><slice><image>[128002 * 96]</image><image>[128002 * 96]</image></slice> please describe the image.<|eot_id|><|start_header_id|>assistant<|end_header_id|> [OUTPUT]A man riding a wave on top of a surfboard.<|eot_id|> [LABELS]A person riding a beautiful wave very smooth [IMAGES]['https://xingchen-data.oss-cn-zhangjiakou.aliyuncs.com/coco/2014/val2014/COCO_val2014_000000567011.jpg']
点击链接⚡️直达原文
https://modelscope.cn/studios/OpenBMB/MiniCPM-Llama3-V-2_5-int4-demo/summary



