问题一:Flink CDC中flinksql 中没找到对应的并行度配置, datastream 中倒是有?
Flink CDC中flinksql 中没找到对应的并行度配置, datastream 中倒是有?
参考回答:
是的,Flink SQL和DataStream API在处理并行度问题时方式是不同的。
在Flink SQL中,并行度是由Flink任务自动管理的,你不需要显式地设置。Flink会根据你的数据源和目标表的分区信息,以及Flink任务的并行度,自动地将数据分发到不同的并行执行线程进行处理。
而在DataStream API中,你需要显式地设置并行度。你可以通过调用setParallelism()方法来设置Flink任务的并行度。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570687
问题二:flink-cdc-oracle 可以并行读取吗?
flink-cdc-oracle 可以并行读取吗, 同步1000万数据,我这边半天没同步完, 这个有什么优化策略吗?这个怎么设置先全量并行读,然后增量 是flink sql跑的?
参考回答:
全量是并行的,增量并行会出问题的,全量可以考虑按照主键或rowid做切分,增量不好并行
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570686
问题三:Flink CDC中阿里云的flinksql,没办法指定时间戳读数据?
Flink CDC中阿里云的flinksql,没办法指定时间戳读数据?
参考回答:
没必要删,无状态启动下补数据
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570685
问题四:用flink cdc同步rds上的mysql数据到kafka里,请问这是什么情况?
用flink cdc同步rds上的mysql数据到kafka里,但是每次update的时候会被拆成一个create和一个delete事件。请问这是什么情况,我如果需要update时输出update事件该怎么处理?
参考回答:
自建的喔,不是一个before一个after嘛
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570682
问题五:Flink CDC如果源表没有主键,flink主键随便指定一个字段么?
Flink CDC如果源表没有主键,flink主键随便指定一个字段么? 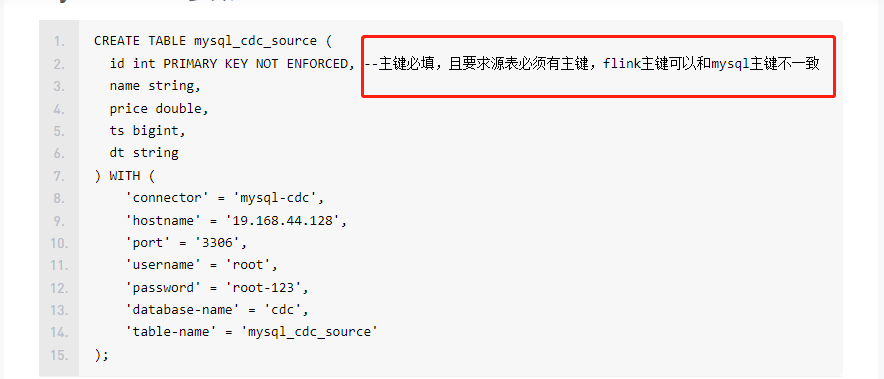
参考回答:
在Flink CDC中,如果源表没有主键,您可以选择任意一个字段作为主键来使用。这个主键是在flink建立和sink表的关联时指定的,主要是为了满足flink实时同步程序的需要。然而,尽管可以选择任意字段作为主键,最好选择一个具有唯一性和稳定性的字段,以避免在同步过程中出现重复或错误的数据。同时,您也需要确保所选择的字段在源表中确实存在且值能唯一标识每一条记录。
关于本问题的更多回答可点击原文查看:https://developer.aliyun.com/ask/570681

