一、认识Storm
Apache Storm是个实时数据处理的“大能”,它可以实时接收、处理并转发大量数据流,就像一个高速运转的物流中心,确保数据及时、准确地到达目的地。我们要做的,就是把这个物流中心搭建起来,并且根据我们的业务需求进行个性化设置。
二、准备工作
- 环境要求
确保你的机器满足以下条件:
• 操作系统:Linux(推荐CentOS或Ubuntu)或macOS
• Java环境:Java 8或以上版本(因为Storm是用Java编写的)
• ZooKeeper:Storm依赖ZooKeeper进行集群协调,所以需要先安装并运行ZooKeeper
- 下载Storm
访问Apache Storm的官方网站(https://storm.apache.org/),找到最新稳定版的Storm发行包(通常是apache-storm-*.tar.gz格式),下载到本地。
三、安装与配置
- 解压Storm
将下载好的压缩包解压到你喜欢的位置,比如 /usr/local/storm。打开终端,执行类似命令:
- 设置环境变量
为了让系统能找到Storm的相关命令,我们需要将Storm的bin目录添加到系统的PATH环境变量中。编辑你的shell配置文件(如.bashrc或.bash_profile),添加以下行:
保存文件后,运行 source ~/.bashrc 或 source ~/.bash_profile 使改动生效。
- 配置Storm
Storm的主要配置文件位于 $STORM_HOME/conf/storm.yaml。打开它,根据实际情况修改以下关键配置项:
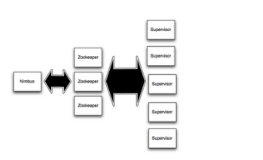
• nimbus.host: 设置Nimbus节点(相当于主控节点)的IP地址或主机名,如果你只在本地测试,可以保持默认的 localhost。
• storm.zookeeper.servers: 列出ZooKeeper服务器的IP地址和端口,例如:
storm.zookeeper.servers:
- "zookeeper1.example.com"
- "zookeeper2.example.com"
• storm.local.dir: 指定Storm在本地存储临时数据的目录,确保该目录存在且有足够权限。
• supervisor.slots.ports: 设置每个Supervisor节点(工作节点)上可用的worker端口列表,例如:
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
根据你的硬件资源和需求调整其他配置项,但初次接触的话,大部分默认设置已经够用了。
四、启动与验证
- 启动ZooKeeper
确保你的ZooKeeper服务已经启动并运行正常。如果没有,可以按照ZooKeeper的官方文档进行安装和启动。
- 启动Storm集群
回到终端,依次启动Storm的三个核心服务:
- 验证安装
打开浏览器,访问 http://localhost:8080/(如果Storm UI不在本地,替换为相应主机的IP和端口),你应该能看到Storm的管理界面,显示集群状态、拓扑等信息。这就说明你的Storm集群已经成功搭建并运行起来了