
前言
大家好,我是yma16,本文分享python_将包含汉字的字典数据写入json(将datav的全省数据中的贵州区域数据取出来)
学习json库——写入json文件中
Python中的JSON库是一个内置的标准库,可以用于解析和编码JSON数据。下面是JSON库的使用方法:
解码JSON
首先,我们将一个JSON字符串转换成Python对象。
import json # 定义一个JSON字符串 json_str = '{"name": "John", "age": 30, "city": "New York"}' # 使用 json.loads() 函数将 JSON 字符串转换为 Python 对象 data = json.loads(json_str) # 输出 Python 对象 print(data) # {'name': 'John', 'age': 30, 'city': 'New York'}
编码JSON
接下来,我们将Python对象转换成JSON字符串。
import json # 定义一个Python字典 data = {"name": "John", "age": 30, "city": "New York"} # 使用 json.dumps() 函数将 Python 对象转换为 JSON 字符串 json_str = json.dumps(data) # 输出 JSON 字符串 print(json_str) # {"name": "John", "age": 30, "city": "New York"}
读取JSON文件
读取JSON文件非常简单。我们只需要使用 json.load() 函数即可。
import json # 打开一个JSON文件 with open('data.json', 'r') as f: # 使用 json.load() 函数读取 JSON 数据并转换为 Python 对象 data = json.load(f) # 输出 Python 对象 print(data)
写入JSON文件
写入JSON文件也很简单。我们只需要使用 json.dump() 函数即可。
import json # 定义一个 Python 字典 data = {"name": "John", "age": 30, "city": "New York"} # 打开一个文件并将 Python 对象写入文件中 with open('data.json', 'w') as f: # 使用 json.dump() 函数将 Python 对象转换为 JSON 字符串并写入文件 json.dump(data, f) # 读取 JSON 文件并转换为 Python 对象 with open('data.json', 'r') as f: data = json.load(f) # 输出 Python 对象 print(data)
dumps函数
json.dumps函数查看用法
import json help(json)

发现可以把数组及字符等数据变为字符,查看处理json的indent参数
indent参数
可以添加缩进

ensure_ascii参数
调整ensure_ascii=false就可正常显示汉字
关闭转化为ASCII码字符
练习将贵州区域数据取出来
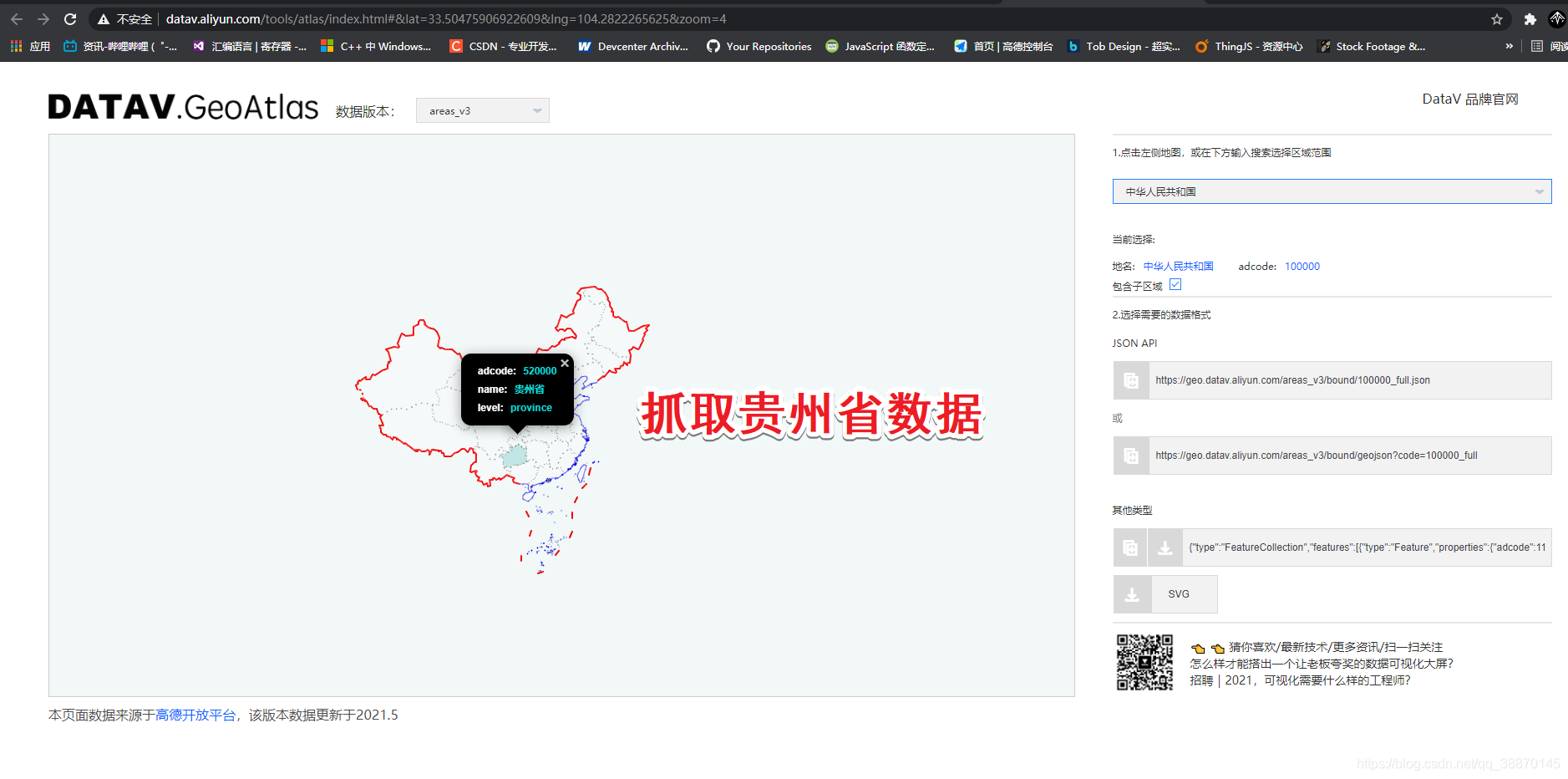
只需要贵州省的svg

import json with open("china.json", 'r',encoding='utf-8') as f: result = json.load(f) temp=result['features'] print(len(temp)) loc=0 result={ "type": "FeatureCollection", "features":[] } for i in temp: loc+=1 province=i['properties'] name=str(province['name']) if name in ['贵州省']: print(name) result["features"].append(i) print(len(result),result) json_str = json.dumps(result, indent=4,ensure_ascii=False) # ensure_ascii=False 取消转换ascii码 with open('guizhou_gis.json', 'a+',encoding='UTF-8') as json_file: json_file.write(json_str)
提取成功!

ps拉框助手验证json地图格式
使用ps拉框助手验证是否提取出贵州省区域,验证正确

结束
本文分享到这结束,如有错误或者不足之处欢迎指出,感谢大家的阅读!
