承接上一篇,这次跟大家分享一些与SQL优化相关的经验,希望能够帮助大家了解如果更有效率的使用ADBPG数据库。
所有你需要了解的基础知识
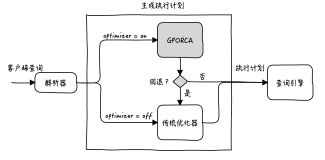
ADBPG数据库使用基于成本(cost-based)的优化器,像其他的数据库一样,在生成计划时会考虑联接表行数、索引、相关字段基数等因素,除此之外,优化器还会考虑数据所在的segment节点位置,争取能够尽可能的减少segment节点之间的数据传输,让尽可能多的工作都在segment上独立完成,来提升查询的效率。
当查询运行速度比预期慢时,一个重要的优化手段就是查看执行计划,通过分析每个步骤的计算成本,来帮助我们定位资源消耗最多的环节,从而展开优化。通常,我们使用EXPLAIN语句来查看查询的执行计划,执行计划是根据查询相关表的统计信息生成的,因此统计信息的准确与否会影响到执行计划的好坏,这个我们在后面的章节会详细介绍。
生成执行计划
使用EXPLAIN和EXPLAIN ANALYZE语句可以查看查询的执行计划。
EXPLAIN语句会显示查询的执行计划和估计成本,但不执行查询。
EXPLAIN ANALYZE语句除了显示执行计划之外,还会实际执行查询。
为了方便查看,EXPLAIN ANALYZE语句会丢弃所有查询结果输出,但是,语句中的DML操作 (例如,INSERT,UPDATE,或DELETE)会被实际执行,因此需要格外注意。想要在不影响数据的情况下,对DML语句使用EXPLAIN ANALYZE命令,也是有办法的,可以将EXPLAIN ANALYZE语句嵌套在事务中执行,如:
BEGIN;
EXPLAIN ANALYZE ...;
ROLLBACK;EXPLAIN ANALYZE 除了显示执行计划之外,还有以下附加信息:
运行查询的总时间,以及生成执行计划消耗的时间 (以毫秒为单位)
计划节点(motion相关)操作中涉及的计算节点 (segment) 的数量
为操作生成最多行的段 (及其段ID) 返回的最大行数
运行查询消耗的内存
从产生最多行数据的segment中取回第一行数据所消耗的时间 (以毫秒为单位),以及从该segment中取会所有行数据所消耗的总时间。
阅读执行计划
执行计划是一份数据库优化器生成的报告,它详细描述了执行查询应该遵循的步骤,优化器类似于高德地图,执行计划类似于推荐路线。执行计划的表现方式是一棵由节点构成的树,从下向上阅读,每一个节点都会将其执行结果传递给相邻的上层节点。每个节点表示计划中的一个步骤,步骤中标识了需要执行的操作——例如 scan、join、aggregation或者sort。同时,节点还标识了用于执行该操作的方法。例如,scan的方法可能是sequential scan(全表扫)或者index scan。而join操作可以执行 hash join 或者 nested loop join。
以下是一个简单查询的执行计划,相关查询会获取每个segment上的contributions表的行数。
adbpgadmin=# explain select gp_segment_id,count(*) from test group by gp_segment_id;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Gather Motion 88:1 (slice2; segments: 88) (cost=36984.43..36985.31 rows=88 width=12)
-> HashAggregate (cost=36984.43..36985.31 rows=1 width=12)
Group Key: test.gp_segment_id
-> Redistribute Motion 88:88 (slice1; segments: 88) (cost=36981.35..36983.11 rows=1 width=12)
Hash Key: test.gp_segment_id
-> HashAggregate (cost=36981.35..36981.35 rows=1 width=12)
Group Key: test.gp_segment_id
-> Seq Scan on test (cost=0.00..29974.90 rows=15924 width=4)
Optimizer: Postgres query optimizer
(9 rows)这个执行计划有5个节点 - Seq Scan,HashAggregate,Redistribute Motion, HashAggregate,Gather Motion。每个节点包含了3个统计指标,且皆为估计值:
Cost - 这个指标的单位是读取的 disk page(32K)的个数,举个例子,1.0就代表读取一个disk page。显示结果中的第一个数值代表获取第一行数据的cost,第二个数值代表获取所有数据的cost,这也正是为什么cost的大小会随着LIMIT语句的使用而改变。
Rows - 当前计划节点输出的总行数,受where语句选择性的影响。
Width - 当前计划节点输出所有行的平均行宽,以bytes为单位。
每个计划节点的cost会包含其所有子节点的cost,所以最上方的计划节点(通常为Gather Motion)的cost为整个执行计划的cost,这个数值越小代表当前执行计划效率越高。
Scan算子会扫描表中的行来寻找一个特定的行集合,对于不同种类的存储方式有不同的扫描操作符。它们包括:
Seq Scan — 扫描表中的所有行。
Index Scan — 遍历一个B-树索引来从表中取得行记录。
Bitmap Heap Scan — 从索引中收集表中行的指针并且按照磁盘上的位置进行排序。
Dynamic Seq Scan — 使用一个分区选择函数来选择分区进行扫描,后面会在“动态分区消除”部分消息介绍。
Join算子包括以下这些:
Hash Join – 使用较小的表构建一个哈希表(这一步骤在执行计划中通过hash算子体现),用关联列作为哈希键。然后扫描较大的表,为关联列计算哈希键并且探索哈希表寻找具有相同哈希键的行。通常Hash Join是ADBPG数据库中最快的连接方式,执行计划中的Hash Cond标识着被连接的列。
Nested Loop – 在较大表的行记录上进行遍历,用每个遍历到的值去扫描较小表中的行。Nested Loop会广播关联表中的其中一张表,这样一个表中的所有行才能与其他表中的所有行进行比较,这种关联方式适用于在小表或者有索引的表上执行。它还被用于笛卡尔积或者范围连接,在使用Nested Loop关联大表时会有性能衰退。设置配置参数enable_nestloop为OFF(默认)能够让优化器更倾向于使用Hash Join。
Merge Join – 排序两个数据集并且将它们合并起来。归并连接对预排序好的数据很快,但是在现实世界中很少见。为了更偏爱Merge Join,可把系统配置参数enable_mergejoin设置为ON。
计划节点中可能会出现motion操作,在必要的场景下,motion操作会在Segment节点之间进行行迁移。Motion算子包括以下这些:
Broadcast motion - 每个Segment节点都将自己的行记录发送给所有其他的Segment节点,这样每个Segment节点上都有表的完整数据。Broadcast motion的成本比Redistribute motion要高,因此优化器通常只为小表选择Broadcast motion,对大表来说,Broadcast motion是不可接受的。
Redistribute motion - 每个Segment节点对所保存的数据进行重新哈希,并按照哈希键把行发送到对应的Segment节点上。
Gather motion - 汇聚所有Segment节点的结果数据到一起,对大部分执行计划来说这是最后的步骤。
动态分区消除(Dynamic Partition Elimination,DPE),ORCA优化器的一种特性,用于消除与查询结果无关的分区,从而减少需要处理的数据的数量,进而提升效率。与常见的静态分区消除不同,DPE可以识别并消除只有在查询实际执行时才能排除的分区。为了实现这种能力,ORCA引入了三个新的算子,他们以生产者/消费者的模式协同工作:
Partition Selector - 基于给定的分区选择条件,计算出所有满足条件的分区的OID。
Dynamic Seq Scan - 负责获取Partition Selector指定的分区的数据。
Sequence - 负责执行子算子(Partition Selector和Dynamic Seq Scan),以及汇总查询结果并输出给上一级。
为了便于理解这三个算子,我们以下这个例子详细解释一下,其他catalog_sales(date_id)和date_dim(data_dim)都是分区表。
select year
from catalog_sales join date_dim on date_id = date_dim.id
where date_dim.month = 12
group by year;
QUERY PLAN
------------------------------------------------------------------------------
Gather Motion 2:1 (slice2; segments: 2) (cost=... rows=10 width=32
-> Hash Join (cost=... rows=5 width=32)
Hash Cond: catalog_sales.date_id = data_dim.id
-> Dynamic Table Scan on catalog_sales (dynamic scan id: 1) (cost... rows=5000 width=16)
-> Hash (cost=100.00..100.00 rows=50 width=4)
-> Partition Selector for catalog_sales (dynamic scan id: 1) (cost=... rows=50 width=4)
Filter: catalog_sales.date_id = date_dim.id
-> Broadcast Motion 2:2 (slice1; segments: 2) (cost=... rows=1 width=16)
-> Sequence (cost=... rows=1 width=16)
-> Partition Selector for date_dim (dynamic scan id: 2) (cost=....)
Partitions selected: 12 (out of 12)
-> Dynamic Table Scan on date_dim (dynamic scan id: 2) (cost=...)
Filter: month = 12 自下而上阅读执行计划,首先第一组Sequence、Partition Selector、Dynamic Table Scan三个算子的组合完成了对date_dim的分区扫描,这个很好理解。
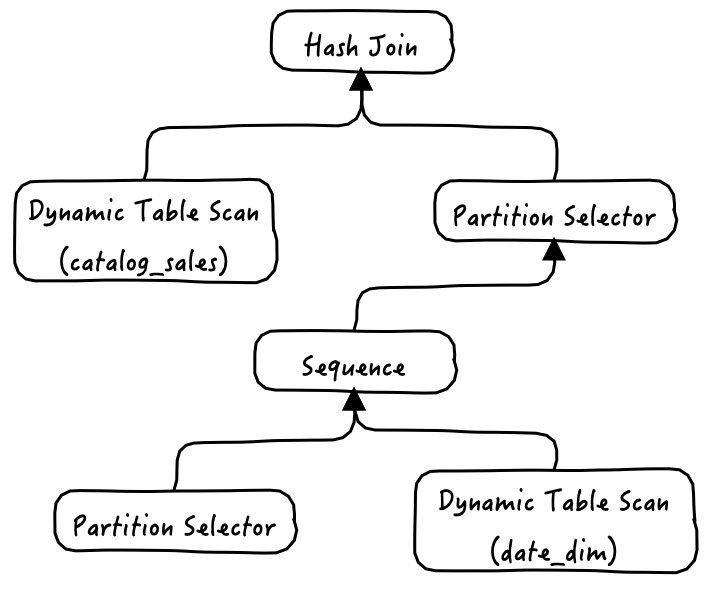
然后date_dim表的查询结果被流式的传递给了第二组的Partition Selector,这个Partition Selector在接收到数据(date_dim.id)后,根据关联条件date_id=date_dim.id对catalog_sales分区进行筛选,然后提供给第二组的Dynamic Table Scan进行数据获取,这里Hash join算子会替代第二组的Sequence算子做数据整合。
其他
执行计划中还可能会出现的其他算子:
Materialize - 优化器将子查询进行物化,这样就不用针对所有外部行记录重复执行子查询。
InitPlan - 预查询,被用于动态分区消除(dynamic partition elimination)中,当执行查询时还不知道优化器需要扫描分区的值时,会执行这个预查询。
Sort - 为其他要求排序数据的操作(例如Aggregation或者Merge Join)准备排序数据。
Group By - 针对一列或者多列进行分组。
Group/Hash Aggregate - 使用哈希算法对行进行聚合。
Append - 串接数据集,例如在整合分区表中各个分区的行记录时或者使用union all时会用到。
Filter - 使用WHERE子句的条件对行进行选择。
Limit - 限制返回的行数。
Result - 结果集操作或者where子句与数据无关的结果返回(如 select * from t1 where 1<>1)。
MOTIONS/SLICES/GANG
之前讲到了关于Motion的算子,这里再详细的说一下motion/slice/gang是什么,ADBPG中的执行计划是分布式计划,因此引入了Motion计划节点来实现分布式算法的数据通信。每个Motion计划节点都将计划分割成若分片:下面的分片将在motion中发送数据,上面的分片将从motion中接收数据,这些分片在ADBPG中被称为Slice。每个slice由一个Gang(一组分布式进程)执行。gang之间通过网络进行交流。
Motion:除了常见的数据库操作(例如表扫描,联接等)之外,ADBPG数据库还有一种名为motion的算子,motion用于数据库查询过程中在segment之间移动元组,也就是数据通信。注意并不是每个数据库查询都需要执行motion,例如对系统catalog表进行查询时,只会访问master,从而不需要通过网络在segment间传输数据。
Slice:每个Motion算子都会在现有执行计划的基础上将其进一步分割成上下两个分片:下方的分片在motion中发送数据,上方的分片从motion中接收数据。这些分片在ADBPG中被称为Slice,slice是计划中可以独立进行处理的部分。
Gang:每个slice包含一个Gang(一组分布式进程),gang之间通过网络进行交流。属于同一个slice但是运行在不同的segment上的进程。
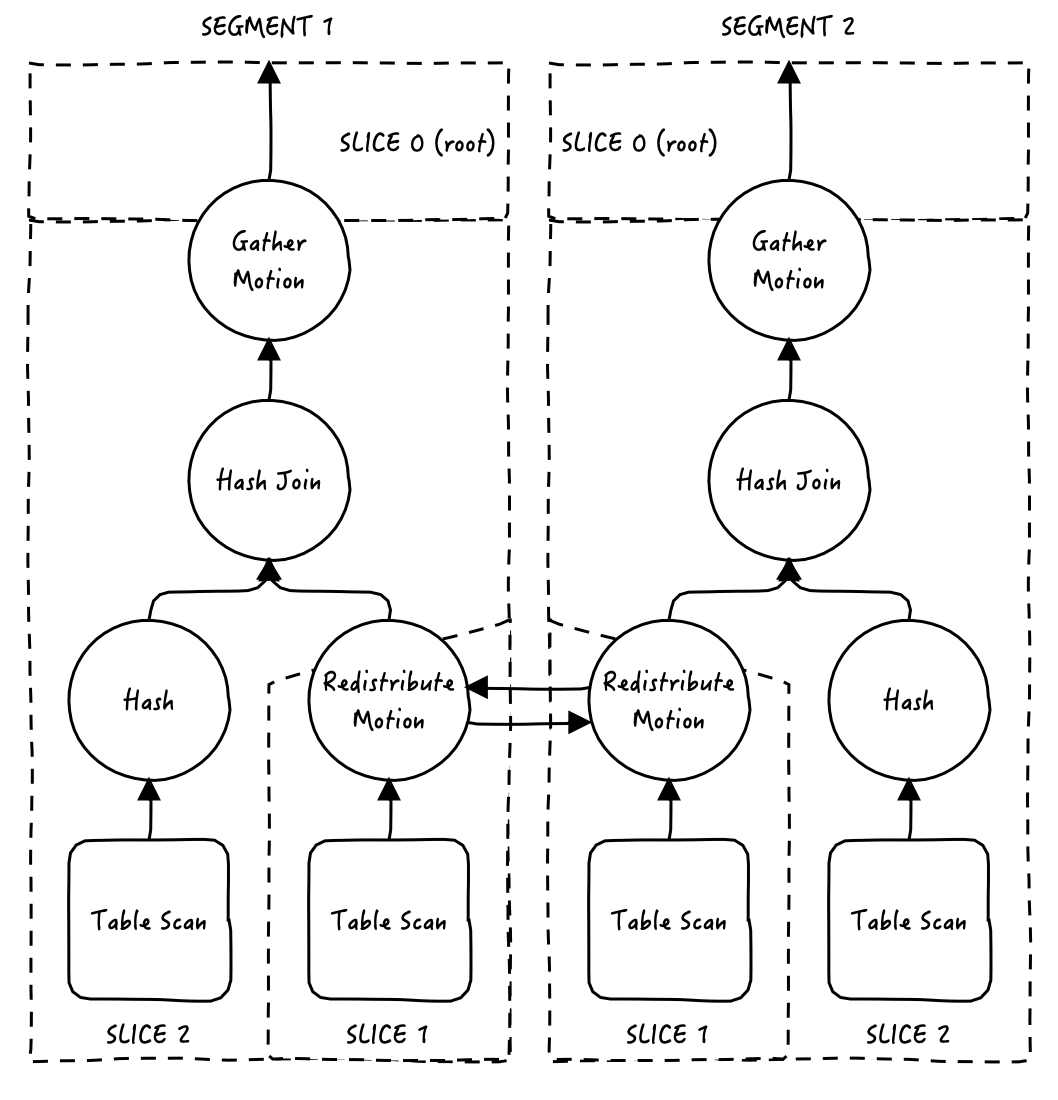
我们通过一个例子来介绍一下,上图是查询语句select * from t1, t2 where t1.a = t2.a的执行计划树,虚线围起来的区域是一个slice,注意每个segment都会获取相同的执行计划,然后并行工作。
在这个计划中,首先看redistribute motion,它会并行地在segment间传输来自t1 table scan的数据,借此来在本地实现数据关联,可以看到redistribute motion对执行计划进行了切片,两端分别是slice1和slice2。
然后上方还有一个gather motion,gather motion会汇聚所有segment返回的结果,并呈现给客户端,我们之前说到会将执行计划切片,所以在整个计划的最上面会有一个隐藏的切片slice0(root slice),之所以说是隐藏的是因为在执行计划里是看不到这个slice的,gather motion是非常常见的算子,几乎所有执行计划里都会有,但是有时候也不是必须的,如CREATE TABLE x AS SELECT... 语句就不会出现gather motion,因为结果数据会被直接发送给新创建的表,而不是master节点。
SQL优化过程
SQL优化的基础知识普及完成后,我们通过某客户的例子来介绍一下实际SQL优化过程。
优化目标
客户反馈部分关键节点任务运行缓慢,导致依赖此任务的下游任务均出现延时的情况,需要进行一次全面的SQL性能优化,因此提取了12000多个SQL脚本的运行情况,以下是TOP15的运行情况,最慢的SQL脚本需要执行1小时41分钟,所有12766的SQL脚本运行完成,运行时间之和为60小时。
目标:
1)针对执行时间排在top前几位的SQL脚本进行针对性优化,避免出现个别效率短板的情况,影响整体运行效果。
2)数仓运行效率进行整体提升,整体效率提升20%,缩短到50个小时以内。
整个优化周期为一个月,由于横跨春节假期,所以实际的优化时间也就是两周多一点,以下是大部分的优化内容点。
ANALYZE
当分析执行计划时,首先需要做的是找出成本非常高或者异常底的计划节点,并基于数据量等信息判断估计的行数、成本以及查询计划树的执行顺序是否合理。如果分析发现执行顺序不是最优的或者行数、成本与实际情况相差较大,应确保数据库统计信息是最新的。运行ANALYZE将能更新数据库统计信息,进而产生一个最优的查询计划。
ANALYZE是ADBPG中收集统计信息的命令,支持列,表,库三种粒度:
ANALYZE table1(column1); 只采集column1列的统计信息
ANALYZE table1; 搜集table1表的统计信息
ANALYZE; 搜集当前库所有表的统计信息 官方建议在以下三个场景下执行ANALYZE:
加载数据后
CREATE INDEX 操作后
INSERT, UPDATE 和 DELETE 大量数据后
ANALYZE会给目标表加SHARE UPDATE EXCLUSIVE锁,以便于实现并行访问表,但是与当前表相关INSERT,UPDATE,DELETE,还有DDL语句冲突。ANALYZE是一种采样统计算法,通常不会扫描表中所有的数据,但是对于大表,也仍会消耗一定的时间和计算资源。
介绍一个客户现场比较常见的统计信息问题,执行性能不佳的SQL出现如下的计划节点:
-> Broadcast Motion 132:132 (slice1; segments: 132) (cost=0.00..6.13 rows=1 width=16) 有个比较明显的特点是rows=1,通常这是一个统计信息不准确的信号,优化器会误认为表里只有一行数据,然后进而使用了Broadcast Motion来广播数据,实际上表里的数据可能够几百万或者上千万,广播的性能损耗太巨大了,此时只需要analyze重新采集统计信息就可以解决问题,当然最好能将motion操作去掉。
数据倾斜
当数据在segment上分布不均匀时,最直接的影响就是整体数据容量出现短板,由于数据会集中存储在个别节点上,这些节点的容量如果耗尽,那整个集群都会被影响。其次在查询执行期间会发生计算倾斜,也就是说某些segment节点使用了更多的CPU和内存,导致执行效果不佳。同时,数据倾斜往往意味着分布键选择不佳,在查询执行过程需要额外的motion操作来进行数据的重新分布,带来额外的性能损耗。
在决定分布键时,需要考虑以下这些最佳实践:
为所有的表指定分布键或随机分布,不要使用默认值,ADBPG会使用第一列作为默认值。
最好的情况下,分布键涉及的字段数据可以均匀的分布在各个segment上。
不要使用WHERE子句中的列作为分布键,而是应该作为分区键。
不要使用日期或时间戳作为分布键。
分布键列上的数据应该是唯一的或拥有非常高的基数。
如果单列无法实现均匀分布,可以使用最多两列作为分布键。额外的列通常不会产生更均匀的分布,但是在hash过程中需要消耗额外的时间。
如果两列分布键无法实现数据的均匀分布,建议使用随机分布。过多列作为分布键在大多数情况下都需要motion操作来实现表连接,因此它们与随机分布相比没有优势。
客户实际情况是基本上都违反了最佳实践中的:
不要使用日期或时间戳作为分布键。
导致数据严重倾斜,进而导致计算倾斜,削弱了数据库整体的计算能力。以上情况需要具体整改,但是好在ADBPG数据库中修改分布键是在线进行的,对生产环境影响是有限的。
数据分布相关的内容,我们会在“ADBPG优化基础”后面用一个单独章节进行更加详细介绍。
postgres fdw外部表
postgres_fdw模块提供外部数据封装器的功能,ADBPG通过它可以访问存储在外部的其他ADBPG或者PostgreSQL数据库中的数据。
postgres_fdw会尝试优化远程查询,以减少从外部数据库的数据传输量。通常是将 WHERE查询条件语句传到远程服务器上执行,不取回与查询结果不相关的列来减少传输数据链。为了减少查询未被执行的风险,WHERE从句必须要是固定的值或者函数,否则无法被下推到远端。
EXPLAIN VERBOSE可以用来查询发送到远端数据库的实际语句,帮助判断查询是否得到了优化。
注意:当前版本中,如果查询中涉及同一外部数据库的多张外部表的关联查询,是无法将多张表连同关联条件一起推到远端数据库的,而会分别将多张表拉回本地,然后再做关联,这可能导致大量的数据传输量,这个功能在Postgresql 9.6版本才得到实现,当前ADBPG是基于9.4版本,所以还不具备此功能。
When postgres_fdw encounters a join between foreign tables on the same foreign server, it sends the entire join to the foreign server, unless for some reason it believes that it will be more efficient to fetch rows from each table individually, or unless the table references involved are subject to different user mappings. While sending the JOIN clauses, it takes the same precautions as mentioned above for the WHERE clauses.
当postgres_fdw碰到同一个外部服务器上的外部表之间的连接时,它会把整个连接发送给外部服务器,除非由于某些原因它认为逐个从每一个表取得行的效率更高或者涉及的表引用属于不同的用户映射。在发送JOIN子句时,它也会采取和上述WHERE子句相同的预防措施。
针对这个问题有两个解决方式:
如果其中一张关联表的结果很少,可以转化成字符串变量,然后通过明文的方式放到where字句中,下推到远端服务器,如果结果很多就不适用了。
可以在远端服务器上针对需要关联的多张外部表创建试图,然后在本地针对该试图创建外部表,这种方式的改造成本会比较高。
其他案例汇总
NOT IN + NESTED LOOP JOIN性能优化
执行查询时,使用not in语句且右边为一个子查询时,可能会出现Nested Loop的执行计划,这种执行计划在ADBPG中性能不优,是需要极力避免的。
create table t1 (c1 varchar, c2 varchar);
create table t2 (c1 varchar, c2 varchar);
explain select * from t1
where (c1,c2)
not in( select c1,c2 from t2);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Gather Motion 88:1 (slice2; segments: 88) (cost=100000000000000000000.00..100000000001601650688.00 rows=26100 width=64)
-> Nested Loop Left Anti Semi (Not-In) Join (cost=100000000000000000000.00..100000000001601650688.00 rows=297 width=64)
Join Filter: (((t1.c1)::text = (t2.c1)::text) AND ((t1.c2)::text = (t2.c2)::text))
-> Seq Scan on t1 (cost=0.00..448.00 rows=396 width=64)
-> Materialize (cost=0.00..46732.00 rows=34800 width=64)
-> Broadcast Motion 88:88 (slice1; segments: 88) (cost=0.00..31420.00 rows=34800 width=64)
-> Seq Scan on t2 (cost=0.00..448.00 rows=396 width=64)
Optimizer: Postgres query optimizer
(8 rows)类似的问题的优化方法比较简单,就是将not in右边的相关列添加COALESCE函数,确保其返回的值不为Null,这样优化器就可以使用Hash Join,提升执行效率。
explain select * from t1
where (c1,c2)
not in( select coalesce(c1,''),coalesce(c2,'') from t2);
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather Motion 88:1 (slice2; segments: 88) (cost=1666.00..305309.00 rows=26100 width=64)
-> Hash Left Anti Semi (Not-In) Join (cost=1666.00..305309.00 rows=297 width=64)
Hash Cond: (((t1.c1)::text = (COALESCE(t2.c1, ''::character varying))::text) AND ((t1.c2)::text = (COALESCE(t2.c2, ''::character varying))::text))
-> Seq Scan on t1 (cost=0.00..448.00 rows=396 width=64)
-> Hash (cost=1144.00..1144.00 rows=396 width=64)
-> Redistribute Motion 88:88 (slice1; segments: 88) (cost=0.00..1144.00 rows=396 width=64)
Hash Key: COALESCE(t2.c1, ''::character varying)
-> Seq Scan on t2 (cost=0.00..448.00 rows=396 width=64)
Optimizer: Postgres query optimizer
(9 rows)NOT IN + UNION性能问题
在执行查询时,如果在not in的右边是一个使用union的子查询,会出现Filter: (SubPlan 1)算子,对左表的数据逐行过滤,效率十分缓慢。
explain select * from t1,t2 where t1.c1=t2.c1 and t1.c2 = '123' and coalesce(t2.c2, '') not in (
select coalesce(t20.c2, '') from t10, t20 where t10.c1=t20.c1
and t10.c2 != '123'
union
select coalesce(t10.c2, '') from t10, t20 where t10.c1=t20.c1
and t20.c2 != '321'
);
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------
Gather Motion 88:1 (slice3; segments: 88) (cost=720.62..37689179116.76 rows=1231 width=72)
-> Hash Join (cost=720.62..37689179116.76 rows=14 width=72)
Hash Cond: (t2.c1 = t1.c1)
-> Seq Scan on t2 (cost=0.00..37689178168.08 rows=282 width=36)
Filter: (SubPlan 1)
SubPlan 1 (slice3; segments: 88)
-> Materialize (cost=729141.20..802872.19 rows=55857 width=32)
-> Broadcast Motion 88:88 (slice2; segments: 88) (cost=729141.20..778295.19 rows=55857 width=32)
-> HashAggregate (cost=729141.20..778295.19 rows=55857 width=32)
Group Key: (COALESCE(t20.c2, ''::character varying))
-> Redistribute Motion 88:88 (slice1; segments: 88) (cost=1216.00..716852.71 rows=55857 width=32)
Hash Key: (COALESCE(t20.c2, ''::character varying))
-> Append (cost=1216.00..716852.71 rows=55857 width=32)
-> Hash Join (cost=1216.00..333849.35 rows=27929 width=32)
Hash Cond: (t10.c1 = t20.c1)
-> Seq Scan on t10 (cost=0.00..720.00 rows=564 width=4)
Filter: ((c2)::text <> '123'::text)
-> Hash (cost=596.00..596.00 rows=564 width=36)
-> Seq Scan on t20 (cost=0.00..596.00 rows=564 width=36)
-> Hash Join (cost=1216.00..333849.35 rows=27929 width=32)
Hash Cond: (t20_1.c1 = t10_1.c1)
-> Seq Scan on t20 t20_1 (cost=0.00..720.00 rows=564 width=4)
Filter: ((c2)::text <> '321'::text)
-> Hash (cost=596.00..596.00 rows=564 width=36)
-> Seq Scan on t10 t10_1 (cost=0.00..596.00 rows=564 width=36)
-> Hash (cost=720.00..720.00 rows=1 width=36)
-> Seq Scan on t1 (cost=0.00..720.00 rows=1 width=36)
Filter: ((c2)::text = '123'::text)
Optimizer: Postgres query optimizer但是如果在not in右边,用select * from ()将union子查询套起来,就会使用hash join,效率大幅提升。
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------
Gather Motion 88:1 (slice3; segments: 88) (cost=0.00..2586.00 rows=1 width=24)
-> Hash Left Anti Semi (Not-In) Join (cost=0.00..2586.00 rows=1 width=24)
Hash Cond: ((COALESCE(t2.c2, ''::character varying))::text = ((COALESCE(t20.c2, ''::character varying)))::text)
-> Hash Join (cost=0.00..862.00 rows=1 width=24)
Hash Cond: (t2.c1 = t1.c1)
-> Seq Scan on t2 (cost=0.00..431.00 rows=1 width=12)
-> Hash (cost=431.00..431.00 rows=1 width=12)
-> Seq Scan on t1 (cost=0.00..431.00 rows=1 width=12)
Filter: ((c2)::text = '123'::text)
-> Hash (cost=1724.00..1724.00 rows=1 width=8)
-> Broadcast Motion 88:88 (slice2; segments: 88) (cost=0.00..1724.00 rows=1 width=8)
-> GroupAggregate (cost=0.00..1724.00 rows=1 width=8)
Group Key: (COALESCE(t20.c2, ''::character varying))
-> Sort (cost=0.00..1724.00 rows=1 width=8)
Sort Key: (COALESCE(t20.c2, ''::character varying))
-> Redistribute Motion 88:88 (slice1; segments: 88) (cost=0.00..1724.00 rows=1 width=8)
Hash Key: (COALESCE(t20.c2, ''::character varying))
-> Append (cost=0.00..1724.00 rows=1 width=8)
-> Result (cost=0.00..862.00 rows=1 width=8)
-> Hash Join (cost=0.00..862.00 rows=1 width=8)
Hash Cond: (t20.c1 = t10.c1)
-> Seq Scan on t20 (cost=0.00..431.00 rows=1 width=12)
-> Hash (cost=431.00..431.00 rows=1 width=4)
-> Seq Scan on t10 (cost=0.00..431.00 rows=1 width=4)
Filter: ((c2)::text <> '123'::text)
-> Result (cost=0.00..862.00 rows=1 width=8)
-> Hash Join (cost=0.00..862.00 rows=1 width=8)
Hash Cond: (t10_1.c1 = t20_1.c1)
-> Seq Scan on t10 t10_1 (cost=0.00..431.00 rows=1 width=12)
-> Hash (cost=431.00..431.00 rows=1 width=4)
-> Seq Scan on t20 t20_1 (cost=0.00..431.00 rows=1 width=4)
Filter: ((c2)::text <> '321'::text)
Optimizer: Pivotal Optimizer (GPORCA) version 3.86.0NOT IN + TO_DATE性能问题
在执行查询时,如果在not in的右边对date类型字段使用coalesce(c2, to_date('00010101', 'yyyymmdd')),会出现(Nested Loop Left Anti Semi (Not-In) Join)算子,在数据量很大的情况下,执行效率十分缓慢。
如果将其改造为coalesce(c2, cast('00010101' as date)),则会使用(Hash Left Anti Semi (Not-In) Join)算子,执行效率会有大幅度提升。
不过,如果not in的右边有且只有一个date类型的字段,并使用了coalesce(c,to_date),则也会使用hash join,优化器使用GPORCA。
create table t1 (c1 varchar, c2 date);
create table t2 (c2 varchar, c2 date);
select * from t1
where (coalesce(c1, ''), coalesce(c2, to_date('00010101', 'yyyymmdd'))) not in (
select coalesce(c1, ''), coalesce(c2, to_date('00010101', 'yyyymmdd'))
from t2
);
Gather Motion 88:1 (slice2; segments: 88) (cost=100000000000000000000.00..100000000003253633024.00 rows=16 width=36)
-> Nested Loop Left Anti Semi (Not-In) Join (cost=100000000000000000000.00..100000000003253633024.00 rows=1 width=36)
Join Filter: (((COALESCE(t1.c1, ''::character varying))::text = (COALESCE(t2.c1, ''::character varying))::text) AND (COALESCE(t1.c2, '00010101'::date) = COALESCE(t2.c2, '00010101'::date)))
-> Seq Scan on t1 (cost=0.00..596.00 rows=564 width=36)
-> Materialize (cost=0.00..66564.00 rows=49600 width=36)
-> Broadcast Motion 88:88 (slice1; segments: 88) (cost=0.00..44740.00 rows=49600 width=36)
-> Seq Scan on t2 (cost=0.00..596.00 rows=564 width=36)
Optimizer: Postgres query optimizer
select * from t1
where (coalesce(c1, ''), coalesce(c2, cast('00010101' as date))) not in (
select coalesce(c1, ''), coalesce(c2, cast('00010101' as date))
from t2
);
Gather Motion 88:1 (slice3; segments: 88) (cost=2332.00..619208.16 rows=16 width=36)
-> Hash Left Anti Semi (Not-In) Join (cost=2332.00..619208.16 rows=1 width=36)
Hash Cond: (((COALESCE(t1.c1, ''::character varying))::text = (COALESCE(t2.c1, ''::character varying))::text) AND (COALESCE(t1.c2, '00010101'::date) = COALESCE(t2.c2, '
00010101'::date)))
-> Redistribute Motion 88:88 (slice1; segments: 88) (cost=0.00..1588.00 rows=564 width=36)
Hash Key: COALESCE(t1.c1, ''::character varying), COALESCE(t1.c2, '00010101'::date)
-> Seq Scan on t1 (cost=0.00..596.00 rows=564 width=36)
-> Hash (cost=1588.00..1588.00 rows=564 width=36)
-> Redistribute Motion 88:88 (slice2; segments: 88) (cost=0.00..1588.00 rows=564 width=36)
Hash Key: COALESCE(t2.c1, ''::character varying), COALESCE(t2.c2, '00010101'::date)
-> Seq Scan on t2 (cost=0.00..596.00 rows=564 width=36)
Optimizer: Postgres query optimizer
select * from t1
where coalesce(c2, to_date('00010101', 'yyyymmdd')) not in (
select coalesce(c2, to_date('00010101', 'yyyymmdd'))
from t2
);
Gather Motion 88:1 (slice2; segments: 88) (cost=0.00..862.00 rows=1 width=12)
-> Hash Left Anti Semi (Not-In) Join (cost=0.00..862.00 rows=1 width=12)
Hash Cond: (COALESCE(t1.c2, to_date('00010101'::text, 'yyyymmdd'::text)) = (COALESCE(t2.c2, '00010101'::date)))
-> Seq Scan on t1 (cost=0.00..431.00 rows=1 width=12)
-> Hash (cost=431.00..431.00 rows=1 width=4)
-> Broadcast Motion 88:88 (slice1; segments: 88) (cost=0.00..431.00 rows=1 width=4)
-> Result (cost=0.00..431.00 rows=1 width=4)
-> Seq Scan on t2 (cost=0.00..431.00 rows=1 width=4)
Optimizer: Pivotal Optimizer (GPORCA) version 3.86.0此问题的临时优化手段则是使用cast代替to_date函数,可以有效的提升相关SQL的运行效率。
UPDATE语句出现笛卡尔积
UPDATE语句执行时间为时间:821567.605 ms (13:41.568)远远高于传统数仓的执行时间,而通过数据量判断,这个执行时间是异常的。继续分析执行计划。
从执行计划中可以发现如下算子
-> Seq Scan on vt_cust_acct_oper_evt_detail vt_cust_acct_oper_evt_detail_1 (cost=0.00..431.49 rows=3045 width=273) (actual time=0.026..26.712 rows=6310 loops=1)
也就是vt_cust_acct_oper_evt_detail自己与自己做了一次笛卡尔积,这个效率肯定是不好的,同时也违背了SQL语句的语意。
经过分析发现,传统数仓和ADB在执行UPDATE语句时,对SQL语句的写法有差异,传统数仓和ADBPG环境规范写法可以参考以下内容。
在不关联其他表,传统数仓与ADB PG的语法相同,无须转换;
关联表进行更新时,传统数仓的FROM子句在前,而SET子句在后, 而ADB PG刚好相反;传统数仓需要在FROM子句声明更新表及被关联表,ADB PG在UPDATE后面申明更新表,在FROM子句后面申明被关联表,转换语法对照如下:
传统数仓 |
ADB PG |
||
UPDATE t1 [FROM table t1, table t2] SET column = expression, ,... ,column = expression [WHERE condition]; |
UPDATE [ONLY] table [[AS] alias] SET {column={expression | DEFAULT} | (column [,...]) = ({expression | DEFAULT} [,...])}[,...] [FROM fromlist] [WHERE condition]; |
||
示例参考 |
|||
UPDATE a FROM wanto_update a , source_data b SET a.c1 = b.c1, a.c2 = b.c2 WHERE a.bsm = b.bsm; |
UPDATE wanto_update a SET a.c1 = b.c1, a.c2 = b.c2 FROM source_data b WHERE a.bsm = b.bsm; |
||
优化成果
经过两周多的SQL优化工作,在额外增加694(12766-13460)个SQL脚本的情况下:
客户数仓整体SQL运行性能较一个月前提升25%,总体运行时间缩短15小时;
TOP15的SQL脚本的总共运行时间从10小时34分缩短到4小时55分;
单SQL脚本最长执行时间从1小时41分,缩短到42分。
下一章计划分享一些MPP数据库数据分布相关的内容。
参考文档:
https://gpdb.docs.pivotal.io/6-20/best_practices/tuning_queries.html