一、数据集
1、定义
在计算机中,数据集指的是任何数据集合。它可以是从数组到完整数据库的任何内容。
二、数据类型
1、数值
数值数据是数字,可以分为两种数值类别:离散数据和连续数据。其中离散数据指的是限制为整数的数字。连续数据指的是具有无限值的数字。
2、分类
分类数据是无法相互度量的值。eg:颜色值或者是任何yes/no值。
3、序数
序数数据类似于分类数据,但是可以相互度量
三、平均中位数模式
1、均值(NumPy模块)
平均值,NumPy模块拥有用于此目的的方法。
import numpy speed=[99,86,87,88,111,86,103,87,94,78,77,85,86] x=numpy.mean(speed) print(x) #89.76923076923077
2、中值(NumPy模块)
中点值,又称中位数。是对所有值进行排序后的中间值
import numpy speed = [99,86,87,88,111,86,103,87,94,78,77,85,86] x = numpy.median(speed) print(x) #87.0
如果中间有两个数字,则将这两个数字相加除以2
3、众数(SciPy模块)
最常见的值。指的是出现次数最多的值
from scipy import stats speed = [99,86,87,88,111,86,103,87,94,78,77,85,86] x = stats.mode(speed) print(x) #ModeResult(mode=array([86]), count=array([3]))
四、标准差(NumPy模块)
是一个数字,描述值的离散程度
1、低标准偏差
表示大多数数字接近均值
2、高标准偏差
表示这些值分布在更宽的范围内
import numpy speed = [86,87,88,86,87,85,86] x = numpy.std(speed) print(x) #0.9035079029052513
五、方差(NumPy模块)
方差指示值的分散程度。
标准差实际上就是方差的平方根。
求方差的步骤如下:
1、求均值
2、找到每个值和平均值的差
3、计算每个差值的平方值
4、方差是这些平方差的平均值
import numpy speed = [32,111,138,28,59,77,97] x = numpy.var(speed) print(x) #1432.2448979591834
六、百分位数(NumPy模块)
百分位数提供一个数字,该数字描述了给定百分比值小于的值。
eg:75百分位数是43,意味着75%的人是43岁或者以下。
import numpy ages = [5,31,43,48,50,41,7,11,15,39,80,82,32,2,8,6,25,36,27,61,31] x = numpy.percentile(ages, 75) print(x) #43.0
七、数据分布
1、如何获得大数据集?
为了创建用于测试的大数据集,使用python中NumPy模块,该模块附带了很多创建任意大小的随机数据集的方法。
import numpy x = numpy.random.uniform(0.0, 5.0, 250) print(x)
2、直方图
为了可视化数据集,可以对收集的数据绘制直方图
使用Python模块的Matplotlib进行绘制直方图
import numpy import matplotlib.pyplot as plt x = numpy.random.uniform(0.0, 5.0, 250) plt.hist(x, 5) plt.show()

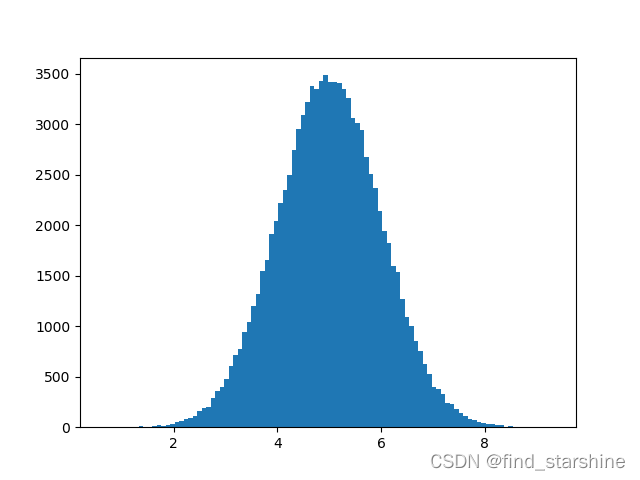
八、正态数据分布
创建一个将值集中在给定值周围的数组。又称为高斯数据分布。
import numpy import matplotlib.pyplot as plt x = numpy.random.normal(5.0, 1.0, 100000) plt.hist(x, 100) plt.show()
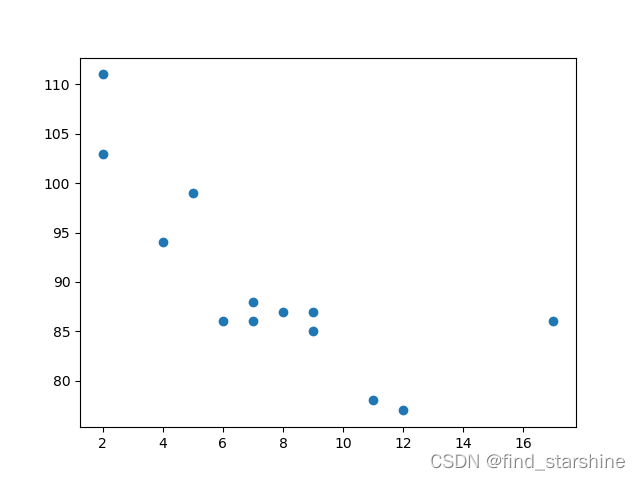
九、散点图(Matplotlib模块)
散点图是数据集中的每个值都由点表示的图。matplotlib模块有一种绘制散点图的方法,需要两个长度相同的数组,一个数组用于x轴的值,另一个数组用于y轴的值。
import matplotlib.pyplot as plt x = [5,7,8,7,2,17,2,9,4,11,12,9,6] y = [99,86,87,88,111,86,103,87,94,78,77,85,86] plt.scatter(x, y) plt.show()
十、线性回归
- 这种关系用于预测未来事件的结果。
- 线性回归使用数据点之间的关系在所有数据点之间画一条直线。这条线可以用来预测未来的值。
#导入所需模块: import matplotlib.pyplot as plt from scipy import stats #创建表示x轴和y轴值的数组 x = [5,7,8,7,2,17,2,9,4,11,12,9,6] y = [99,86,87,88,111,86,103,87,94,78,77,85,86] #执行一个方法,该方法返回线性回归的一些重要键值 slope, intercept, r, p, std_err = stats.linregress(x, y) #创建一个使用slope和intercept值的函数返回新值。这个新值表示相应的x值将在y轴上放置的位置 def myfunc(x): return slope * x + intercept #通过函数运行x数组的每个值。这将产生一个新的数组,其中的y轴具有新值。 mymodel = list(map(myfunc, x)) #绘制原始散点图 plt.scatter(x, y) #绘制线性回归线 plt.plot(x, mymodel) #显示图 plt.show()

1、R-Squared
- x轴的值和y轴的值之间的关系用一个称为r平方(r-squared)的值来度量。
- r平方值的范围是0-1,其中0表示不相关,而1表示100%相关。
- python和scipy模块将计算该值。
from scipy import stats x = [5,7,8,7,2,17,2,9,4,11,12,9,6] y = [99,86,87,88,111,86,103,87,94,78,77,85,86] slope, intercept, r, p, std_err = stats.linregress(x, y) print(r) #-0.758591524376155
from scipy import stats x = [5,7,8,7,2,17,2,9,4,11,12,9,6] y = [99,86,87,88,111,86,103,87,94,78,77,85,86] slope, intercept, r, p, std_err = stats.linregress(x, y) def myfunc(x): return slope * x + intercept speed = myfunc(10) print(speed) #85.59308314937454
2、糟糕的拟合度
import matplotlib.pyplot as plt from scipy import stats x = [89,43,36,36,95,10,66,34,38,20,26,29,48,64,6,5,36,66,72,40] y = [21,46,3,35,67,95,53,72,58,10,26,34,90,33,38,20,56,2,47,15] slope, intercept, r, p, std_err = stats.linregress(x, y) def myfunc(x): return slope * x + intercept mymodel = list(map(myfunc, x)) plt.scatter(x, y) plt.plot(x, mymodel) plt.show()

import numpy from scipy import stats x = [89,43,36,36,95,10,66,34,38,20,26,29,48,64,6,5,36,66,72,40] y = [21,46,3,35,67,95,53,72,58,10,26,34,90,33,38,20,56,2,47,15] slope, intercept, r, p, std_err = stats.linregress(x, y) print(r) #0.01331814154297491 表示关系很差,表明该数据集不适合线性回归
