Kafka 是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台。kafka基于发布-订阅(pub-pub)模式,可以处理大量的数据,适用于离线和在线消息消费。
可靠性 - Kafka是分布式,分区,复制和容错的。
可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。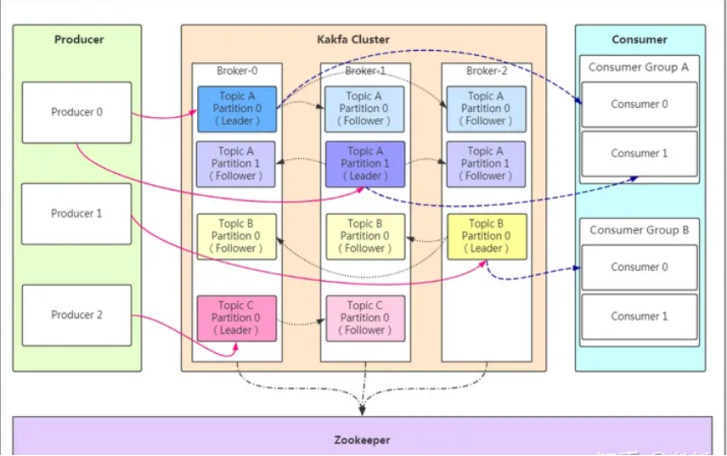
架构图如上,相关概念如下:
- Producer:Producer即生产者,消息的产生者,是消息的入口。
- Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等……一个broker可以容纳多个topic
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当Leader故障时会选择一个Follower成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
发送数据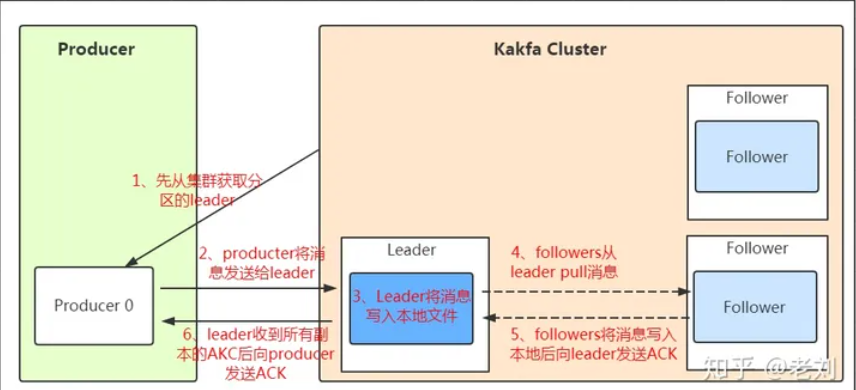
消息写入leader后,follower是主动的去leader进行同步的!producer采用push模式将数据发布到broker,每条消息追加到分区中,顺序写入磁盘,所以保证同一分区内的数据是有序的。
分区的主要目的是:
(1)方便扩展。因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
(2)提高并发。以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
保存数据
kafka将数据保存在磁盘,Kafka初始会单独开辟一块磁盘空间,顺序写入数据(效率比随机写入高)。
Partition在服务器上的表现形式就是一个一个的文件夹,每个partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件(早期版本中没有)三个文件, log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。
存储在log中的message主要包含消息体、消息大小、offset:
(1)offset:offset是一个占8byte的有序id号,它可以唯一确定每条消息在parition内的位置!
(2)消息大小:消息大小占用4byte,用于描述消息的大小。
(3)消息体:消息体存放的是实际的消息数据(被压缩过),占用的空间根据具体的消息而不一样。
消费数据
Kafka 可以同时支持点对点和发布订阅消息模型,具体实现方式如下:
点对点(Point-to-Point):在点对点模型中,一个生产者将消息发送到特定的消费者,消息被严格地传递给一个目标消费者,不会被其他消费者接收。实现点对点消息的关键是使用分区。
(1)Producer:生产者通过指定消息的目标主题和分区将消息发送到 Kafka 集群。消息被写入特定分区,并根据 Kafka 的分区机制进行分发。
(2)Consumer:消费者通过订阅特定的分区来接收消息。每个分区只能被一个消费者组中的一个消费者处理。消费者从指定分区读取消息,并进行消费处理。
(3)分区机制:Kafka 将一个主题划分为多个分区,每个分区都是有序且独立的日志队列。每个分区可以有多个副本,以提供容错和高可用性。消费者可以通过订阅特定分区来实现点对点的消息传递。多个消费者可以独立消费不同的分区,实现消息的并行处理。
发布订阅(Publish-Subscribe): 在发布订阅模型中,一个生产者将消息发送到一个主题,而不关心具体的消费者。多个消费者可以订阅该主题,并独立地接收消息。实现发布订阅消息的关键是使用消费者组和主题。
(1)Producer:生产者将消息发送到特定的主题,不需要关心具体的消费者。消息被写入主题的多个分区中,以实现消息的分发。
(2)Consumer Group:消费者可以组成一个消费者组,共同订阅一个主题。每个消费者组中的消费者可以是动态的,可以根据需要增加或减少。消费者组的目标是实现高吞吐量和负载均衡。Kafka 会将消息均匀地分发给消费者组中的消费者。
(3)主题和分区:主题可以被划分为多个分区,每个分区都有自己的消费者组。Kafka 使用分区机制来实现消息的并行处理和负载均衡。每个分区只能被一个消费者组中的一个消费者处理。