1. 特征向量
近年来,研究者通过词汇学方法,发现约有五种特质可以涵盖人格描述的所有方面,提出了人格的大五模式(Big Five),俗称人格的海洋(OCEAN),包括以下五个维度:
- 开放性(Openness):具有想象、审美、情感丰富、求异、创造、智能等特质。
- 责任心(Conscientiousness):显示胜任、公正、条理、尽职、成就、自律、谨慎、克制等特点。
- 外倾性(Extroversion):表现出热情、社交、果断、活跃、冒险、乐观等特质。
- 宜人性(Agreeableness):具有信任、利他、直率、依从、谦虚、移情等特质。
- 神经质性(Neuroticism):难以平衡焦虑、敌对、压抑、自我意识、冲动、脆弱等情绪的特质,即不具有保持情绪稳定的能力。
通过NEO-PI-R测试可以得出每个维度的打分(1-100),然后将其缩放到[ − 1 , 1 ] [-1,1][−1,1]之间:
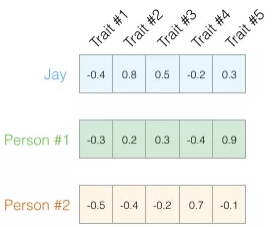
利用余弦相似度可以计算两个人的性格相似度,如图,向量a = [ x 1 , y 1 ] , b = [ x 2 , y 2 ] \boldsymbol a=[x_1,y_1],\boldsymbol b =[x_2,y_2]a=[x1,y1],b=[x2,y2] 
则,s i m ( a , b ) = c o s θ = a b ∣ a ∣ ∣ b ∣ = x 1 x 2 + y 1 y 2 x 1 2 + y 1 2 x 2 2 + y 2 2 sim(a,b) = cos \theta = \frac {ab}{\mid a \mid \mid b \mid} = \frac {x_1x_2+y_1y_2}{\sqrt{x_1^2+y_1^2}\sqrt{x_2^2+y_2^2}}sim(a,b)=cosθ=∣a∣∣b∣ab=x12+y12x22+y22x1x2+y1y2
对于n nn维向量A = [ a 1 , a 2 , . . . a n ] , B = [ b 1 , b 2 , . . . b n ] A=[a_1,a_2,...a_n],B=[b_1,b_2,...b_n]A=[a1,a2,...an],B=[b1,b2,...bn],
s i m ( A , B ) = A B ∣ A ∣ ∣ B ∣ = ∑ i = 1 n A i B i ∑ i = 1 n A i 2 ∑ i = 1 n A i 2 sim(A,B) = \frac {AB}{\mid A \mid \mid B \mid}= \frac {\sum_{i=1}^{n}{A_iB_i}}{\sqrt{\sum_{i=1}^{n}{A_i^2}}\sqrt{\sum_{i=1}^{n}{A_i^2}}}sim(A,B)=∣A∣∣B∣AB=∑i=1nAi2∑i=1nAi2∑i=1nAiBi
余弦相似度的取值范围在-1到1之间。余弦值越接近1,也就是两个向量越相似,完全相同时数值为1;相反反向时为-1;正交或不相关是为0。
np.linalg.norm 操作是求向量的范式,默认是L2范式,等同于求向量的欧式距离。
import numpy as np jay = np.array([-0.4,0.8,0.5,-0.2,0.3]) p1 = np.array([-0.3,0.2,0.3,-0.4,0.9]) p2 = np.array([-0.5,0.4,-0.2,0.7,-0.1]) def cos_sim(a, b): a_norm = np.linalg.norm(a) b_norm = np.linalg.norm(b) cos = np.dot(a,b)/(a_norm * b_norm) return cos print(cos_sim(jay,p1),cos_sim(jay,p2))
输出如下:
0.6582337075311759 0.23612240736068565
可见前两者较为相似。
余弦相似度也常用在文本相似度、图片相似度等应用中,比如金融类新以下词出现的频率高:“股票、债券、黄金、期货、基金、上涨、下跌”,而先这些词出现相对较少:“宇宙、太空、星系、恒星、大气层”。每一篇文章也都有相应的特征,由其主题决定,最简单的可以用其TF-IDF值来表示。
2. 词向量
对于每个人可以抽取特征形成一组向量,对于每个词汇同样可以将其转换为一组向量,并计算相互之间的关系。1986年,Hinton在《Learning Distribution Representation of Concepts》中最早提出使用向量来表示词。
对于词典D \mathcal DD中的任意词w ww,通过一个固定长度的向量v ( w ) ∈ R m \rm v(w) \in \mathcal R^mv(w)∈Rm来表示,则v ( w ) \rm v(w)v(w)就称为w ww的词向量。
2.1 例1:King- Man + Woman = Queen
如,单词King的词向量(通过维基百科语料训练的Glove向量)如下:
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 ,
-0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 ,
0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344
, -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
根据值对单元格进行颜色编码(接近2则为红色,接近0则为白色,接近-2则为蓝色):

将“king”与其它单词进行比较:

可以看出:
- 所有这些单词都有一条直的红色列,它们在这个维度上是相似的(名词属性)
- “woman”和“girl”在很多地方是相似的,“man”和“boy”也是一样(Gender)
- “boy”和“girl”也有彼此相似的地方,但这些地方却与“woman”或“man”不同。(Age)
- “king”和“queen”彼此之间相似,但它们与其它单词都不同。(Royalty)
- 除了最后一个单词“water”,所有单词都是代表人,可以看到蓝色列一直向下并在 “water”的词嵌入之前停下了,显示出类别之间的差异。
词嵌入最经典的例子就是K i n g ⃗ − M a n ⃗ + W o m a n ⃗ ≈ Q u e e n ⃗ \vec {King} - \vec {Man} + \vec {Woman} \approx \vec {Queen}King−Man+Woman≈Queen

2.2 例2:跨语言同义词共现
以下为谷歌Mikolov等人在《Exploiting Similarities among Languages for Machine Translation》提及的一个著名的跨语言同义词共现的案例。该例子通过语义映射技术,实现了机器翻译。通过为两种语言构建不同的语言空间,并在两个空间上建立映射关系。
在向量空间内,不同的语言享有许多共性,只要实现一个向量空间向另一个向量空间的映射和转换,即可实现语言翻译。该技术对英语和西班牙语间的翻译准确率高达90 % 90\%90%。

如对于英语和西班牙语,训练得到对应的词向量空间E(nglish)和S(panish)。
- 从英语中抽取五个词“one,two,three,four,five”,通过PCA降维,得到对应的二维向量V o n e , V t w o , V t h r e e , V f o u r , V f i v e V_{one},V_{two},V_{three},V_{four},V_{five}Vone,Vtwo,Vthree,Vfour,Vfive
- 从西班牙语中抽取对应的五个词“uno,dos,tres,cuatro,cinoco”,通过PCA降维,得到对应的二维向量V u n o , V d o s , V t r e s , V c u a t r o , V c i n o c o V_{uno},V_{dos},V_{tres},V_{cuatro},V_{cinoco}Vuno,Vdos,Vtres,Vcuatro,Vcinoco
可以看出,5个词在两个向量空间中的相对位置差不多,说明两种不同语言对应向量空间的结构之间具有相似性,进一步说明了在词向量空间中利用距离刻画词与词之间相似度的合理性。
此外,对于句子、文档也可以用句子向量及文档向量来表示。
3. NNLM
为了得到每个词的词向量,需要根据大量语料进行训练。2003年,Bengio等人在《A neural probabilistic language model》提出了用神经网络建立统计语言模型的框架(NNLM,Neural Network Language Model),并首次提出了word embedding的概念(虽然没有叫这个名字),奠定了包括word2vec等后续研究word representation learning的基础。
NNLM模型的基本思想可以概括如下:
- 假定词表中的每一个word都对应着一个连续的特征向量;
- 假定一个连续平滑的概率模型,输入一段词向量的序列,可以输出这段序列的联合概率;
- 同时学习词向量的权重和概率模型里的参数。
值得注意的一点是,这里的词向量也是要学习的参数。
该论文采用前向反馈神经网络来拟合一个词序列的条件概率p ( w t ∣ w 1 , w 2 , . . . , w t − 1 ) p(w_t|w_1,w_2,...,w_{t-1})p(wt∣w1,w2,...,wt−1),如下图所示:

该模型分成两部:
- 线性的Embedding层:输入为N − 1 N−1N−1个one-hot词向量,通过一个共享的D × V D \times VD×V的矩阵C CC,映射为N − 1 N−1N−1个分布式的词向量(distributed vector)。其中,V VV是词典的大小,D DD是Embedding向量的维度(一个先验参数)。C CC矩阵里存储了要学习的word vector。
- 前向反馈神经网络:由一个tanh隐层和一个softmax输出层组成。通过将Embedding层输出的N − 1 N−1N−1个词向量映射为一个长度为V VV的概率分布向量,从而对词典中的word在输入context下的条件概率做出预估:
p ( w i ∣ w 1 , w 2 , . . . , w t − 1 ) ≈ f ( w i , w t − 1 , . . . , w t − n + 1 ) = g ( w i , C ( w t − n + 1 ) , . . . , C ( w t − 1 ) ) p(w_i|w_1,w_2,...,w_{t-1}) \approx f(w_i, w_{t-1}, ..., w_{t-n+1}) = g(w_i, C(w_{t-n+1}), ..., C(w_{t-1}))p(wi∣w1,w2,...,wt−1)≈f(wi,wt−1,...,wt−n+1)=g(wi,C(wt−n+1),...,C(wt−1))
通过最小化cross-entropy的正则化损失函数来调整模型参数:L ( θ ) = 1 T ∑ t log f ( w t , w t − 1 , . . . , w t − n + 1 ) + R ( θ ) L(\theta)=\frac{1}{T}\sum_t{\log{f(w_t, w_{t-1}, ..., w_{t-n+1})}}+R(\theta)L(θ)=T1t∑logf(wt,wt−1,...,wt−n+1)+R(θ)
模型参数θ \thetaθ包括了Embedding层矩阵C的元素和前向反馈神经网络模型的权重w t , w t − 1 , . . . , w t − n + 1 w_t, w_{t-1}, ..., w_{t-n+1}wt,wt−1,...,wt−n+1。
该模型同时解决了两个问题:
- 统计语言模型里关注的条件概率p ( w t ∣ c o n t e x t ) p(w_t|context)p(wt∣context)的计算
- 向量空间模型里关注的词向量的表达
这两个问题本质上并不独立。通过引入连续的词向量和平滑的概率模型,可以在一个连续空间里对序列概率进行建模,从根本上缓解数据稀疏性和维度灾难的问题;而且以条件概率p(wt|context)为学习目标去更新词向量的权重,具有更强的导向性,同时也与VSM里的Distributional Hypothesis不谋而合。
缺点:
- 只能处理定长的序列
- 训练速度太慢
4. Word2Vec
2013年,Google团队发表了word2vec工具(参见Mikolov等人发表的《Distributed Representations of Sentences and Documents》、《Efficient estimation of word representations in vector space》等论文),通过将所有的词向量化,来定量的度量词与词之间的关系,挖掘词之间的联系。
主要包含
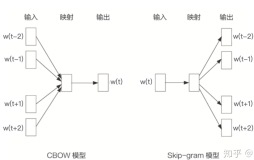
- 两个模型:skip-gram(跳字模型)和CBow,Continuous Bag of Words(连续词袋模型)
- 两种高效训练的方法:Negative Sampling(负采样)和Hierarchical Softmax(层次Softmax)
4.1 SkipGram
(1)基本概念
Skip-gram模型从target word对context的预测中学习到word vector,该名称源于该模型在训练时会对上下文环境里的word进行采样。

如: 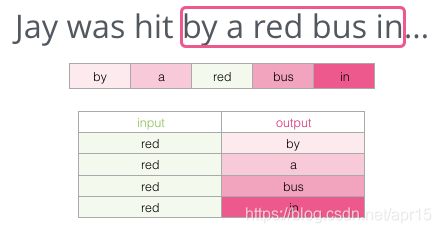
按照上述思路产生的样本如下: 
针对上述模型,将预测相邻单词这一任务,转换为判断两个单词是否为相邻的单词的问题(0表示“不是邻居”,1表示“邻居”):


此时模型如下: 
将模型从神经网络改为逻辑回归模型——更简单,计算速度更快。但是此时所有单词都是相邻单词邻居(target=1),得到的训练模型可能永远返回1。
为了解决该问题,需要在数据集中引入负样本,即非相邻单词样本(target=0):

这个想法的灵感来自噪声对比估计,将实际信号(相邻单词的正例)与噪声(随机选择的不是邻居的单词)进行对比,导致了计算和统计效率的巨大折衷。
word2vec训练过程中的两个关键超参数是窗口大小和负样本的数量,不同的任务适合不同的窗口大小。
(2)数据模型
SkipGram关注是给定中心词w ww生成背景词c cc的条件概率p ( c ∣ w ) p(c \mid w)p(c∣w),假设给定中心词的情况下背景词的生成相互独立,则
max θ ∏ w ∈ W o r d ∏ c ∈ C o n t e x t p ( c ∣ w ; θ ) \max_{\theta} \prod_{w \in Word} \prod_{c \in Context} p(c \mid w; \theta)θmaxw∈Word∏c∈Context∏p(c∣w;θ)
⇒ max θ ∑ w ∈ W o r d ∑ c ∈ C o n t e x t log p ( c ∣ w ; θ ) \Rightarrow \max_{\theta} \sum_{w \in Word} \sum_{c \in Context} \log p(c \mid w; \theta)⇒θmaxw∈Word∑c∈Context∑logp(c∣w;θ)
在跳字模型中,每个词被表示成两个d dd维向量,用来计算条件概率,词典索引集V = { 0 , 1 , … , ∣ V ∣ − 1 } \mathcal{V} = \{0, 1, \ldots, |\mathcal{V}|-1\}V={0,1,…,∣V∣−1}。
假设这个词在词典中索引为i ii,当它为中心词时向量表示为v i ∈ R d \boldsymbol{v}_i\in\mathbb{R}^dvi∈Rd,而为背景词时向量表示为u i ∈ R d \boldsymbol{u}_i\in\mathbb{R}^dui∈Rd。 设中心词w ww在词典中索引为w ww,背景词c cc在词典中索引为c cc,给定中心词生成背景词的条件概率可以通过对向量内积做softmax运算而得到:
P ( c ∣ w ) = exp ( u c ⊤ v w ) ∑ i ∈ V exp ( u i ⊤ v w ) , P(c \mid w) = \frac{\text{exp}(\boldsymbol{u}_c^\top \boldsymbol{v}_w)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_w)},P(c∣w)=∑i∈Vexp(ui⊤vw)exp(uc⊤vw),
因此,Skip-gram模型的本质是计算输入word的input vector v w \boldsymbol{v}_wvw 与目标word的output vector u c \boldsymbol{u}_cuc 之间的余弦相似度,并进行softmax归一化,要学习的模型参数θ \thetaθ正是这两类词向量。
此时log P ( c ∣ w ) = u c ⊤ v w − log ( ∑ i ∈ V exp ( u i ⊤ v w ) ) \log P(c \mid w) = \boldsymbol{u}_c^\top \boldsymbol{v}_w - \log\left(\sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_w)\right)logP(c∣w)=uc⊤vw−log(i∈V∑exp(ui⊤vw))
为了计算最大值,对其求导
∂ log P ( w ∣ c ) ∂ v w = u o − ∑ j ∈ V exp ( u j ⊤ v w ) u j ∑ i ∈ V exp ( u i ⊤ v w ) = u o − ∑ j ∈ V ( exp ( u j ⊤ v c ) ∑ i ∈ V exp ( u i ⊤ v w ) ) u j = u o − ∑ j ∈ V P ( w ∣ c ) u j . \begin{aligned} \frac{\partial \text{log}\, P(w \mid c)}{\partial \boldsymbol{v}_w} &= \boldsymbol{u}_o - \frac{\sum_{j \in \mathcal{V}} \exp(\boldsymbol{u}_j^\top \boldsymbol{v}_w)\boldsymbol{u}_j}{\sum_{i \in \mathcal{V}} \exp(\boldsymbol{u}_i^\top \boldsymbol{v}_w)}\\ &= \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} \left(\frac{\text{exp}(\boldsymbol{u}_j^\top \boldsymbol{v}_c)}{ \sum_{i \in \mathcal{V}} \text{exp}(\boldsymbol{u}_i^\top \boldsymbol{v}_w)}\right) \boldsymbol{u}_j\\ &= \boldsymbol{u}_o - \sum_{j \in \mathcal{V}} P(w \mid c) \boldsymbol{u}_j. \end{aligned}∂vw∂logP(w∣c)=uo−∑i∈Vexp(ui⊤vw)∑j∈Vexp(uj⊤vw)uj=uo−j∈V∑(∑i∈Vexp(ui⊤vw)exp(uj⊤vc))uj=uo−j∈V∑P(w∣c)uj.
它的计算需要词典中所有词以w ww为中心词的条件概率,其他词向量的梯度同理可得。训练结束后,对于词典中的任一索引为i ii的词,均得到该词作为中心词和背景词的两组词向量v i \boldsymbol{v}_ivi和u i \boldsymbol{u}_iui,一般使用跳字模型的中心词向量作为词的表征向量。
上述计算过程极其耗时,为此Mikolov引入了两种优化算法:层次Softmax(Hierarchical Softmax)和负采样(Negative Sampling),核心思想都是降低计算量。
4.2 CBoW
CBoW模型从context对target word的预测中学习到词向量的表达,等价于一个词袋模型的向量乘以一个Embedding矩阵,从而得到一个连续的embedding向量。这也是CBoW模型名称的由来。

如:

使用目标词的前两个词(“by”,“a”)与后两个词(“bus”,“in”),来预测目标词(“red”):

4.3 Negative Sampling
令P ( D = 1 ∣ w , c ) P(D=1 \mid w,c)P(D=1∣w,c)表示中心词w ww与背景词c cc同时出现(正例)的概率,P ( D = 0 ∣ w , w k ) P(D=0 \mid w,w_k)P(D=0∣w,wk)表示中心词w ww与背景词w k w_kwk不同时出现(负例)的概率,
则
P ( D = 1 ∣ w , c ) = σ ( u c ⊤ v w ) P(D=1 \mid w,c)= \sigma (\boldsymbol{u}_c^\top \boldsymbol{v}_w)P(D=1∣w,c)=σ(uc⊤vw)
P ( D = 0 ∣ w , w k ) = 1 − σ ( u k ⊤ v w ) P(D=0 \mid w,w_k)= 1- \sigma (\boldsymbol{u}_k^\top \boldsymbol{v}_w)P(D=0∣w,wk)=1−σ(uk⊤vw)
此时,
p ( c ∣ w ) = P ( D = 1 ∣ w , c ) ∑ k = 1 K P ( D = 0 ∣ w , w k ) = σ ( u c ⊤ v w ) + ∑ k = 1 K [ 1 − σ ( u k ⊤ v w ) ] \begin{aligned}p(c \mid w) & =P(D=1 \mid w,c) \sum_{k=1}^K P(D=0 \mid w,w_k) \\ &= \sigma (\boldsymbol{u}_c^\top \boldsymbol{v}_w) + \sum_{k=1}^K[ 1- \sigma (\boldsymbol{u}_k^\top \boldsymbol{v}_w)] \end{aligned}p(c∣w)=P(D=1∣w,c)k=1∑KP(D=0∣w,wk)=σ(uc⊤vw)+k=1∑K[1−σ(uk⊤vw)]
需要最大化p ( c ∣ w ) p(c \mid w)p(c∣w),由于上式的计算复杂度由K KK个负采样决定,计算量大大降低。
4.4 Hierarchical Softmax
为了避免要计算所有词的softmax概率,word2vec使用Huffman树来代替从隐藏层到输出softmax层的映射,softmax概率计算只需要沿着树形结构进行。
如图,沿着霍夫曼树从根节点一直走到叶子节点的词w 2 w_2w2。

Huffman树的所有内部节点类似神经网络隐藏层的神经元,根节点的词向量对应投影后的词向量,而所有叶子节点就类似于之前神经网络softmax输出层的神经元,叶子节点的个数就是词汇表的大小。Huffman树中,隐藏层到输出层的softmax映射不是一下子完成的,而是沿着霍夫曼树一步步完成,因此这种softmax名为"Hierarchical Softmax"。
word2vec中采用了二元逻辑回归的方法,即规定沿着左子树走,那么就是负类(Huffman树编码1),沿着右子树走,那么就是正类(Huffman树编码0),使用sigmoid函数判别正类和负类。
使用Hierarchical Softmax后,由于Huffman树是二叉树,计算量为由V VV变成了l o g 2 V log2Vlog2V;此外,由于Huffman树是高频的词靠近树根,这样高频词被找到花费时间更短。
5. 使用gensim
gensim是一个很好用的Python NLP的包,封装了google的C语言版的word2vec,不只可以用于word2vec,还有很多其他的API可以用。可以使用
pip install gensim安装。
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中,和算法有关的参数都在类gensim.models.word2vec.Word2Vec中,主要参数如下:
sentences: 要分析的语料,可以是一个列表,或者从文件中遍历读出。size: 词向量的维度,默认值是100。这个维度的取值一般与语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。window:即词向量上下文最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。sg: word2vec两个模型的选择:如果是0(默认), 则是CBOW模型;是1则是Skip-Gram模型。hs: word2vec两个解法的选择:如果是0(默认), 则是Negative Sampling;是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。
以《人民的名义》为语料,分析主要人物的特征:
- 通过词云可以发现,主要有侯亮平、李达康、高育良、祁同伟四位主角
- 使用
model.wv.similarity方法计算相互之间相似度,发现侯亮平、李达康、祁同伟之间相似度较高 - 使用
wv.doesnt_match比较沙瑞金与四位主角相似度,发现沙瑞金更加不同于四位主角
%matplotlib inline import jieba import jieba.analyse filePath = r'data/in_the_name_of_people.txt' stopPath = r'data/stopword_cn.txt' with open(filePath,encoding = 'utf-8') as file: mytext = file.read() #读取到string with open(stopPath,encoding = 'utf-8') as file: word_list = file.read().split() #返回一个字符串,都是小写 person = ['沙瑞金','田国富','高育良','侯亮平','祁同伟', '陈海','钟小艾', '陈岩石','欧阳菁','易学习','程度', '王大路','蔡成功','孙连城','季昌明', '丁义珍', '郑西坡','赵东来', '高小琴','赵瑞龙','田国富', '陆亦可', '刘新建', '刘庆祝','李达康'] for p in person: jieba.suggest_freq(p, True) result = " ".join(jieba.cut(mytext)) #string类型 from wordcloud import WordCloud import matplotlib.pyplot as plt wordcloud = WordCloud(font_path = "simsun.ttf",stopwords=word_list,max_words=30).generate(result) plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off")
输出如下:

from gensim.models import word2vec segPath = r'data/in_the_name_of_people_segment.txt' with open(segPath, 'w',encoding = 'utf-8') as f: f.write(result) sentences = word2vec.LineSentence(segPath) model = word2vec.Word2Vec(sentences, hs=1,min_count=1,window=3,size=100) print(model.wv.similarity('侯亮平', '高育良')) #相似度0.93316543 print(model.wv.similarity('侯亮平', '祁同伟')) #相似度0.9705674 print(model.wv.similarity('侯亮平', '李达康')) #相似度0.96616036 print(model.wv.similarity('李达康', '高育良')) #相似度0.91774 print(model.wv.similarity('李达康', '祁同伟')) #相似度0.9734558 print(model.wv.similarity('高育良', '祁同伟')) #相似度0.9349903 print(model.wv.doesnt_match(u"沙瑞金 侯亮平 高育良 李达康 祁同伟".split()))
输出如下:
0.93316543
0.9705674
0.96616036
0.91774
0.9734558
0.9349903
沙瑞金