向量检索服务 DashVector 免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector
聊聊词向量
词向量(Word Vectors),也称为词嵌入(Word Embeddings),是自然语言处理(NLP)中一种表示词语语义信息的技术。词向量可以将每个单词转换成一个固定维度的数值型向量,通过这种方式,计算机能够理解和处理词语,并在向量空间中为每个单词提供了一种定量的表示。且一定高维度向量(100-400维度)的数据能表征几近无数的词汇。
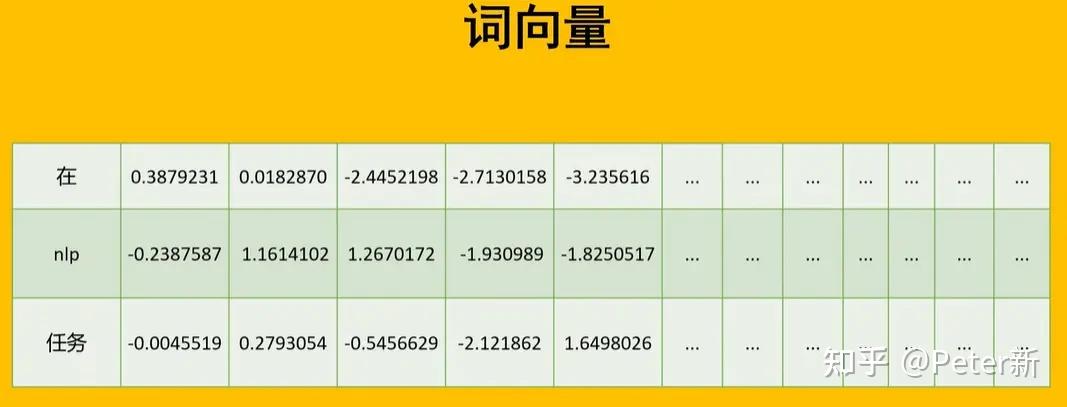
词向量的产生方法
1. 计数方法(Count-based Methods)
这类方法依赖于单词的共现统计信息,即单词在文本中出现的频率。最经典的例子是词频率(ibe-hot),词-文档矩阵(Term-Document Matrix)和词-词共现矩阵(Word-Word Co-occurrence Matrix)。传统的词表示方法,如one-hot编码,存在维度灾难、词之间缺乏语义关联等问题。例如,假设我们有一个大小为10,000的词汇表(词库),每个单词会被转换成一个10,000维的向量,其中只有一个元素是1,其余都是0。这种表示方法不仅占用大量内存,而且无法体现出单词间的语义相似性。比如,“猫”和“狗”虽然语义上较为接近,但它们的one-hot向量间的相似度却为零。为了克服这些问题,研究者们开发了基于上下文的词表示方法,这些方法可以基于大量文本数据学习到单词的语义信息,生成能够表达词之间相似性和关联性的密集型词向量。
单词共现矩阵(Word-Word Co-occurrence): 这种方法考虑单词上下文中的单词共现频率。具体来说,共现矩阵是一种方阵,行和列都表示词汇表中的单词,而每个元素的值则表示对应行单词与列单词在特定窗口大小的上下文中出现在一起的次数。例如,如果我们有以下简单的句子:“The cat sat on the mat”,并选择窗口大小为1(即只考虑一个单词的左右邻居),那么对于单词“the”和“cat”,因为它们是相邻的,所以它们的共现计数会增加。
这种方法的好处在于它能够捕捉到哪些单词经常一起出现,从而可以间接反映这些单词之间的语义关系。但是,共现矩阵的一个缺点是维度很高(等于词汇表的大小),且通常很稀疏,因为大多数单词对并不会一起出现。
潜在语义分析(Latent Semantic Analysis, LSA): 使用矩阵分解技术(如奇异值分解SVD)对大型共现矩阵进行降维,从而捕捉单词间的隐含语义关系。它通常使用奇异值分解(SVD)对词-文档矩阵或词-词共现矩阵进行降维。通过这种降维,LSA 能够找出单词和文档之间隐含的关系,并且以较低维度的向量空间表示单词和文档,这有助于减轻维度灾难和稀疏性的问题。

2. 预测方法(Predictive Methods)
这类方法通过学习任务来直接预测词向量,通常是使用神经网络模型。相比于计数方法,预测方法通常生成低维且密集的词向量。代表性技术有:
- Word2Vec: 由Google的Mikolov等人提出。Word2Vec是最流行的词嵌入技术之一。它有两种架构,CBOW(Continuous Bag of Words)和Skip-gram。CBOW预测目标单词基于上下文,而Skip-gram预测上下文基于目标单词。Word2Vec能够捕获词与词之间的多种关系,例如语义和句法关系。
- GloVe(Global Vectors for Word Representation): 是另一种在共现矩阵上训练词向量的方法,结合了计数方法和预测方法的优点。斯坦福大学的研究人员于2014年提出,GloVe是通过矩阵分解方法对单词共现矩阵进行分析,得到每个单词的向量表示。GloVe在某些任务中表现得比Word2Vec更好,能更好地捕捉全局统计信息。
3. 深度学习方法(Deep Learning Methods)
随着深度学习的发展,出现了基于深度神经网络生成词向量的方法,例如:
- FastText: 由Facebook的研究团队开发,它与Word2Vec类似,但不同之处在于FastText将单词视为n-gram字符序列的组合,从而为每个子词生成词向量。
- ELMo(Embeddings from Language Models): 通过训练深度的双向语言模型,生成的词向量能够捕捉不同上下文中的词义变化。
- BERT(Bidirectional Encoder Representations from Transformers): 利用了Transformer架构,通过预训练深度双向表示,得到能在多种NLP任务中迁移使用的词向量。
静态词向量和动态词向量
在词向量的领域中,我们可以根据词汇表达的灵活性和上下文敏感性将其分为静态词向量(也称为传统词向量)和动态词向量(也称为上下文相关的词向量)。
静态词向量
静态词向量是最早的词嵌入形式,它为词汇表中的每个单词分配一个固定的向量。无论单词出现在什么上下文中,其向量表示都保持不变。常见的静态词向量生成算法包括Word2Vec、GloVe和FastText等。
这种静态的词嵌入有一个重要的局限性:它无法捕捉一个词在不同上下文中可能具有的不同含义(也就是多义词)。例如,这种方法中,“apple”这个词的词向量不会区分它是表示“苹果”这种水果还是指代“苹果公司”。
动态词向量
动态词向量,又称为上下文相关的词嵌入,是一种更高级的技术,可以生成依赖于给定上下文的单词表示。动态词向量可以捕获多义词在不同语境中的语义差异,并提供更加精细和灵活的语言理解。这是通过使用复杂的神经网络模型来实现的,这些模型通常预先在大量文本上进行训练,掌握了丰富的语言知识。两个非常流行的动态词向量生成模型是:
- ELMo(Embeddings from Language Models):它利用深层双向LSTM(长短期记忆)网络,通过在大量文本上预训练语言模型来生成词向量。在这种模型中,每个单词的嵌入是它所有层的LSTM隐状态的函数,这意味着相同的单词在不同的上下文中会有不同的向量表示。
- BERT(Bidirectional Encoder Representations from Transformers):BERT使用了一个叫做Transformer的神经网络架构,特别是它的编码器部分,以双向的方式从上下文中捕获单词的含义。BERT 是一种预训练语言理解模型,可以使用其生成的词向量在各种下游任务(比如问答、情感分析等)中表现出色。
总而言之,动态词向量相比于静态向量,更能反映单词在不同上下文中的复杂语义信息,因此在多义词和上下文敏感度方面表现得更好。不过,静态词向量仍然因其计算效率和在某些任务中的足够性能而被广泛使用。
Word2Vec算法
Word2Vec is a widely used algorithm based on neural networks, commonly referred to as “deep learning” (though word2vec itself is rather shallow). Using large amounts of unannotated plain text, word2vec learns relationships between words automatically. The output are vectors, one vector per word, with remarkable linear relationships that allow us to do things like:
vec(“king”) - vec(“man”) + vec(“woman”) =~ vec(“queen”)
vec(“Montreal Canadiens”) – vec(“Montreal”) + vec(“Toronto”) =~ vec(“Toronto Maple Leafs”).
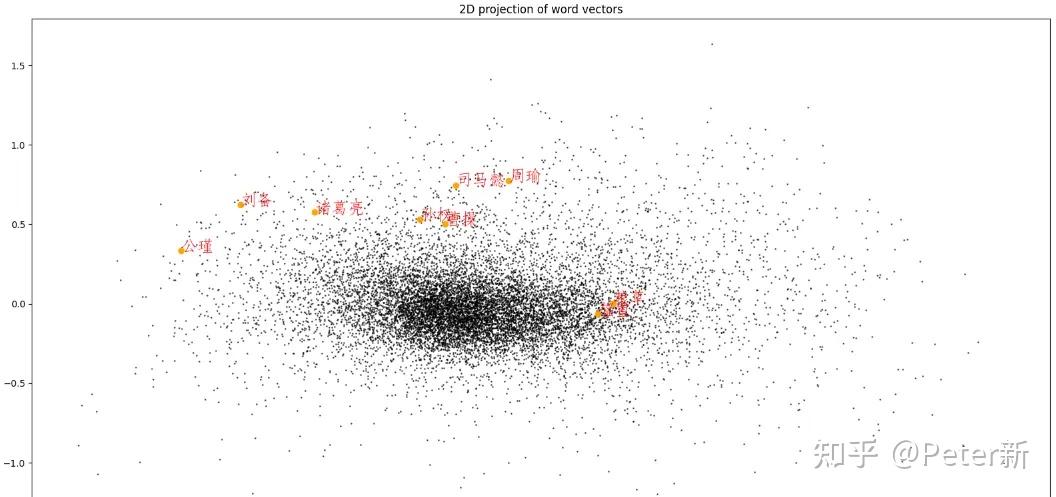
Word2Vec是一种流行的生成静态词向量的模型,它主要有两种训练架构:连续词袋模型(CBOW,Continuous Bag of Words)和Skip-gram模型。它们都是使用神经网络来学习词向量,只是目标任务的设计略有不同。

- 连续词袋模型(CBOW): CBOW模型通过上下文的词来预测目标词。给定一个特定的上下文,模型的目标是准确地预测这个上下文中间的目标词。简单来说,构造的训练样本是(上下文词,目标词)对。
CBOW的实现步骤大概如下:
准备训练数据:
从文本中生成上下文和目标词对。
为每个词随机初始化一个向量作为词的初始表示。
创建网络结构:
输入层:对应上下文中的词向量,通常为上下文词向量的平均(或者求和)。
隐藏层:不使用激活函数的全连接层。
输出层:使用softmax函数将隐藏层的输出转换成一个概率分布。
训练模型:
将上下文词的向量输入网络。
通过网络计算目标词的预测概率分布。
使用目标词的实际分布(通常是one-hot表示)和预测分布来计算损失(如交叉熵损失)。
通过梯度下降等算法更新词向量以最小化损失。
重复上述过程直到模型收敛或达到预定的训练轮次。
使用词向量:提取隐藏层的权重作为最终的词向量。
- Skip-gram模型: Skip-gram模型的原理与CBOW相反,其目标是通过目标词来预测其上下文。Skip-gram更适合处理大量数据,对于低频词效果较好。Skip-gram的实现步骤为:
准备训练数据:
从文本中生成目标词和上下文词对。
为每个词随机初始化一个向量作为词的初始表示。
创建网络结构:
输入层:对应目标词的词向量。
隐藏层:同CBOW。不使用激活函数的全连接层。
输出层:同CBOW,使用softmax函数将隐藏层的输出转换成一个概率分布。但要为每个上下文位置分别预测。
训练模型:
将目标词的向量输入网络。
通过网络计算上下文词的预测概率分布。
根据实际上下文词计算损失,并更新词向量。
重复上述过程直到模型收敛。
使用词向量:与CBOW类似,提取权重作为词向量。
Word2Vec实际实现时,为了提升性能和效率,会使用一些优化技术,比如:负采样(Negative Sampling)、层次softmax(Hierarchical Softmax)、子采样频繁词(Subsampling of Frequent Words)等。这些技术的目的旨在简化损失函数的计算和减小梯度更新的计算量,从而加速训练过程并提高最终模型的质量。
Word2Vec是一个基于预测的模型,用于高效地学习单词的向量表示。它目的都是通过训练将单词转换为稠密向量(嵌入),这些嵌入捕获了语言中的语义信息与单词的上下文关系。以下是Word2Vec中一些重要参数及其含义:
training algorithm(训练算法):
- sg:定义使用的训练算法,sg=0 表示使用CBOW,sg=1 表示使用Skip-gram。
- vector size(向量大小):
- size:词向量的维度大小,一般在100到300之间。向量的维度反映了向量可以捕捉的语言特征的数量,维数越大可以捕捉的信息越多,但计算量也越大。
- window(窗口大小):
- window:训练时考虑的上下文窗口大小。对于CBOW,窗口会包括目标词前后的几个词;对于Skip-gram,窗口决定了我们预测上下文单词时考虑的最大距离。
- min_count(最小计数):
- min_count:词汇表构建时单词出现的最小次数,低于此值的单词会被忽略。
- workers(线程数量):
- workers:训练模型时使用的处理器核心数,多线程可以加速训练。
- alpha(学习率):
- alpha:训练模型的初始学习率,随着训练进行会线性下降到min_alpha。
- iter(迭代次数):
- iter:对语料库的迭代次数,也就是训练的epochs数。
- batch_words(批处理单词数):
- batch_words:用于每个线程的词批处理的大小。
- 除了上述基本参数,还有几个用于优化训练的重要参数:
- negative(负采样):
- negative:使用负采样时,负样本(即不是目标词的词)的数量。用于在优化过程中逼近目标函数,通常设置为5到20。
- hs(层次softmax):
- hs:是否使用层次softmax训练模型,hs=1表示使用,hs=0表示不使用。层次softmax适用于处理大词汇表,可以加快训练速度并提高效率。
- sample(下采样):
- sample:高频词给予更少的权重,设置阈值来进行词频下采样,有助于去除某些高频无信息词并加快训练速度。
这些参数在合理的范围内进行调整,可以帮助Word2Vec模型更好地适应不同的数据集和需求。在使用gensim库中的Word2Vec实现时,这些参数往往通过类的构造器传递。例如:
from gensim.models import Word2Vec
model = Word2Vec(sentences, size=100, window=5, min_count=5, workers=4)
在这个示例中,sentences 是我们的训练数据,它可以是一个词列表的列表,其中的每个列表表示一个文档。其他参数如size, window, min_count, workers 等代表模型的超参数。
GloVe算法
GloVe(Global Vectors for Word Representation)是由Stanford University的研究人员提出的一种用于获取单词嵌入的无监督学习算法。它结合了传统的共现矩阵和预测模型的优点,可以在全局词汇使用的统计信息和局部上下文信息之间找到平衡。
GloVe算法的共现矩阵构建
在GloVe算法中,首先要从语料库中构建一个词-词共现矩阵。这个矩阵用于记录各个单词对(单词及其上下文)在整个语料库中的共现频率。具体步骤如下:
- 选择上下文窗口大小:需要决定在给定目标单词周围考虑多远的“上下文”单词。例如,上下文窗口大小可以是5个单词,这意味着对每个目标单词,其前后各2个单词被认为是其上下文。
- 遍历语料库:然后,对于语料库中的每个单词,将其与它在上下文窗口内的其他单词配对,并更新共现矩阵中的计数。例如,如果窗口大小为10(即目标单词前后各5个单词),那么每个单词将和窗口中的其余9个单词形成配对,相应的矩阵元素值增加。
- 应用权重函数:为了平衡窗口较远处的单词与较近处单词的影响,GloVe提出了一种加权方案,使得距离目标单词更近的上下文单词对共现计数贡献更大,远离目标词的则贡献更小。这通常通过距离或其他衰减函数实现。
- 构建共现矩阵:遍历整个语料库,根据上述步骤构建完整的共现矩阵。矩阵中每一个元素Xij表示单词i与单词j在某个上下文窗口内共同出现的次数。


GloVe算法单词对之间的比例关系:

算法理解:

GloVe的优点:
结合全局统计信息:利用整个语料库信息,可以更好地捕捉不同单词间的语义关联。可以捕捉到单词间复杂的比例关系,如类比关系"man" is to "woman" as "king" is to "queen"。训练过程稳定,结果更可预期。
GloVe的局限:
尽管GloVe使用了全局信息,但每个单词的向量依然是静态的,不考虑特定上下文,因此可能不适合处理多义词,最终的词向量维度以及共现矩阵的窗口大小需要事先确定,并且对结果有较大影响,在处理非常大型词汇时,共现矩阵仍可能非常庞大并且稀疏。
Glove在词向量表征上相较于Word2Vec的全局统计优势,在某些任务上展现了更好的性能,尤其是在语义类比任务上。然而,随着深度学习和上下文相关的词嵌入模型(如ELMo、BERT和GPT)的发展,单词的静态表示方式正在被动态、以上下文为依据的表示方法所取代。上下文相关的词向量模型能够为具有多重语义的单词生成不同的嵌入向量,更好地处理了词义歧义、一词多义等NLP核心挑战。因此,虽然GloVe依然对研究和某些应用场景有重要价值,但在技术发展的最前沿,以Transformer为基础的预训练语言模型已经占据了主导地位。
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector 




![论文赏析[TACL18]隐式句法树模型真的能学到句子中有意义的结构吗?(一)](https://ucc.alicdn.com/pic/developer-ecology/ec03a40b15764e63b627e05584a073a1.png?x-oss-process=image/resize,h_160,m_lfit)
![论文赏析[TACL18]隐式句法树模型真的能学到句子中有意义的结构吗?(二)](https://ucc.alicdn.com/pic/developer-ecology/d00c52d0f1c746cdb30a23928abd8500.png?x-oss-process=image/resize,h_160,m_lfit)
![论文赏析[NAACL19]一个更好更快更强的序列标注成分句法分析器(一)](https://ucc.alicdn.com/pic/developer-ecology/90592b20e515499fba929c5054c4a334.png?x-oss-process=image/resize,h_160,m_lfit)
![论文赏析[NAACL19]一个更好更快更强的序列标注成分句法分析器(二)](https://ucc.alicdn.com/pic/developer-ecology/7653d8d4267f4293ae79078bdcd4d341.png?x-oss-process=image/resize,h_160,m_lfit)