SQL优化
MySQL可以通过B+树来减少索引查处时的IO磁盘次数,但是每次查找、新增都去做磁盘IO的话,如果频繁操作还是会遇到瓶颈。因此就有Buffer pool和Change buffer的出现。
Buffer pool
目的:buffer pool是为了减少磁盘IO的读写次数。
假如没有buffer pool,则每次查询都会从磁盘中读取,进行IO操作。
因此会在内存中专门取一大块区域用作Buffer pool用来保存一些已经读过的页和周围的页数据(空间局部性),这样的的话当下次查询数据时会在Buffer pool查询是否存在需要的页,减少读写IO次数。
当修改数据时,同样会先修改buffer pool中的数据,被修改的页称为脏页,一般会采用redo log持久化机制,将脏页统一写入到磁盘中。
buffer pool结构
buffer pool涉及到三个链表:
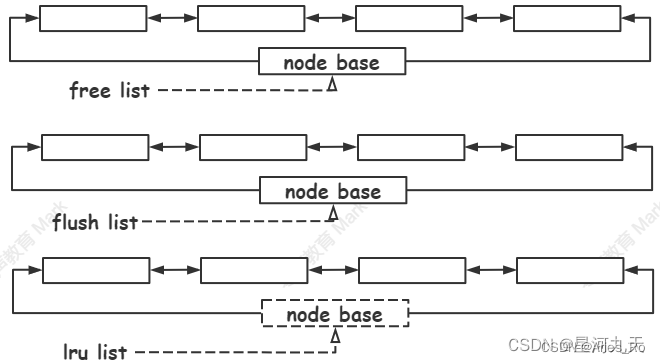
free list 组织 buffer pool 中未使用的缓存页;
flush list 组织buffer pool 中脏页,也就是待刷盘的页;
lru list 组织 buffer pool 中冷热数据,当 buffer pool 没有空闲页,将从 lru list 中最久未使用的数据进行淘汰;
Buffer pool&LRU算法
buffer pool 优化了LRU方法。因为MySQL有预读机制,每次将缓存页加载进Buffer pool时,会将目标缓存页附近的数据页也加进来。就是磁盘读取的空间局部性原理。
这样会导致一个问题,可能被预读加进来的数据页,再之后可能长时间就没访问过了。
优化一、冷热数据

Buffer pool中5/8的区域为new sublist,3/8的区域为old sublist。
- 因此数据加入pool缓冲池时,优先进入old sublist,页被访问时会进入new sublist,在free list
不足时,优先刷入那些old sublist区域的进入磁盘,再清空pool区域。- 所以那些被预读加进来的数据页,如果没被访问,就会一直呆在old区域,等到空间不足时,会被提前清空。这样就能解决预读失效的问题。
优化二、时间阈值
页被访问,且在old sublist停留时间超过配置阈值的,才进入new sublist,以解决批量数据访问,大量热数据淘汰的问题。通常阈值设置为1s。
为什么是1s?
因为预读机制将加载进来的数据页通常是会在1s之内就访问,通常1s之内就会访问这些加载进来的数据页,可能1s之后就不会再被访问了。
因此如果这时将这些访问了的缓存页就加进new区域也不太好,因此通过配置时间阈值。在1s之后在被访问的数据页才进入new区域,并放入new区域的头部,说明后续可能还会被访问到。而1s之前被访问的数据页就不变。
详细内容参考:https://www.jianshu.com/p/7cb6d7d59064
Change buffer
假如一个需要修改的页数据没有在buffer pool中,我们需要怎么操作:
- 将数据页调入到buffer pool中, 一次随机磁盘IO
- 更新buffer pool中的数据 , 一次内存IO
- 将修改写入redo log,一次磁盘顺序写IO
看起来操作还行,但是如果在写多读少的场景下的话,我们有更好的方法,也就是innodb的change buffer。
Change buffer工作原理
Change buffer 缓存非唯一索引的数据变更(DML 操作,只记录操作,不记录结果),当访问这个数据页或者定期时间到达Change buffer 中的数据将会异步 merge 到磁盘当中;
因此对于刚刚的需要修改的页数据没有在buffer pool中,使用change buffer的操作:
- 将修改的操作写入到change buffer中 ,一次内存IO
- 写入日志到redolog中,等待触发merge,一次磁盘顺序写IO
可以看到使用change buffer的话在写多读少的场景下会节省最耗时的磁盘IO读写的次数。
change buffer不适用的场景
- 唯一索引的场景:唯一索引需要判断是否冲突,也就是是否唯一,这个判断需要全局扫描,需要从磁盘读数据,change buffer也就没什么用了。
- 写少读多的场景:因为修改数据页后读取该页会触发merge,而我们的目的就是为了把多次数据页的修改通过一次merge更新到磁盘中,如果读数据的场景多了,那么merge的次数多,也不会减少IO操作次数了。
总结
当数据不在buffer pool中,修改页数据后然后读取数据的步骤,理解一下buffer pool怎么和change buffer工作的:
修改操作:
在buffer poo匹配不到页数据;
在change buffer中记录该数据的修改操作;
查询操作:
在buffer pool 中匹配不到页数据;
change buffer中读取做merge操作,放回buffer pool中;
在磁盘中读取页数据;
