基本概念的理解
k8s是一种编排工具,类似于docker-compose,但是应用比后者广泛。
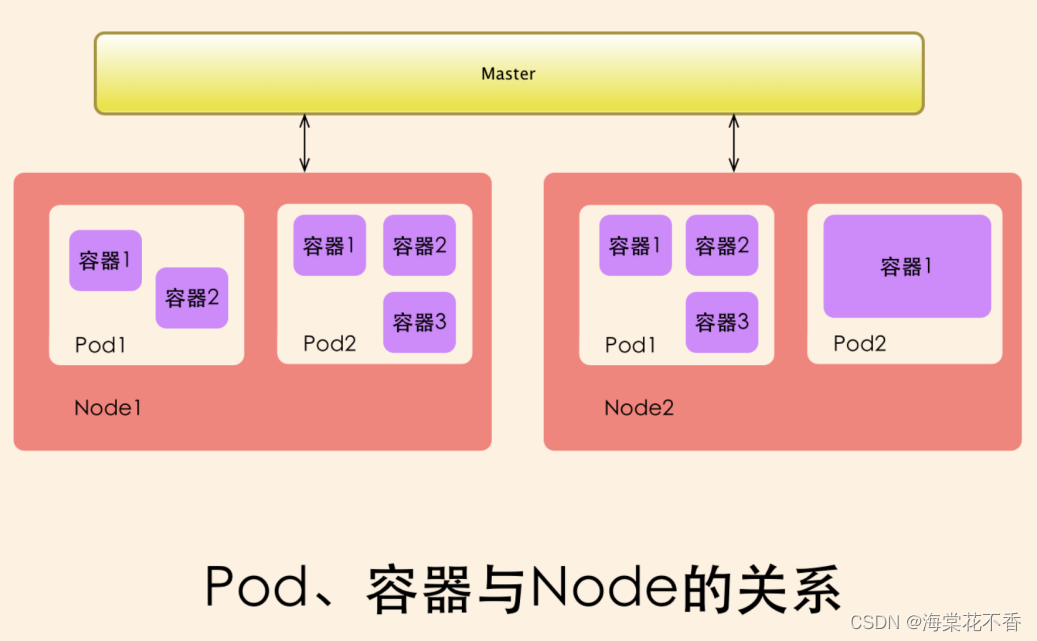
k8s水平扩展访问,本质上是增加pod,且新增的pod均匀分布在不同的机器上。
概念的层级关系k8s–node(对应一台物理机器)–pod。
容器有docker,rocket。k8s与docker的组合最常用。
pod是k8s最小调度单元。每个pod有自己独立的ip。一个pod里面多个docker container的ip都是一样的。pod里面可以开多个docker container。一般情况下一个pod只开一个container,当同一个pod开多个container的时候,多个容器的协作关系采用localhost的方式通信。
节点中的kubelet相当于node server的作用,会上报节点中不同pod的信息。
kublet-pod-docker-container三者之间的关系,类似操作系统中的调度器-进程-线程之间的关系。
所有的数据交互都是通过server-api组件来完成。
etcd默认在master节点上。
service是用来统一管理pod的组件,怎样将pod分发到不同的node。对外表现为一个访问入口,可以认为是一个用来做负载均衡的网管。
参考书:《k8s权威指南》
实操
准备工作
1. 禁用swap
sudo swapoff -a #无输出
注释掉/etc/fstab中关于swap语句
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UmKR3G1L-1664502154890)(D:\Documents\fiberhome\MarkDown\Images\0voice\2022-09-19 194506.png)]
2. 关闭防火墙
master@ubuntu:~$ sudo systemctl stop firewalld #提示防火墙服务没有导入 Failed to stop firewalld.service: Unit firewalld.service not loaded. master@ubuntu:~$ sudo systemctl disable firewalld Failed to disable unit: Unit file firewalld.service does not exist.
3. 禁用selinux
更新ubuntu源
sudo apt install selinux-utils #安装不成功,跟mysql有关系 E: dpkg was interrupted, you must manually run 'sudo dpkg --configure -a' to correct the problem.
这里属于历史遗留问题,参考另一篇解决方法。解决后,更新软件源,用来更快安装selinux。
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
更新文件内容,用阿里源替换
sudo gedit /etc/apt/sources.list # 阿里源 deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
selinux安装完成后,执行
master@ubuntu:~$ sudo setenforce 0 setenforce: SELinux is disabled
4. 修改主机名
master@ubuntu:~$ sudo vim /etc/hosts master@ubuntu:~$ sudo /etc/init.d/networking restart [ ok ] Restarting networking (via systemctl): networking.service.

设置主机名
sudo hostnamectl set-hostname qiu-k8s-m
键入hostnamectl显示主机名已修改成功
master@ubuntu:~$ hostnamectl Static hostname: qiu-k8s-m Icon name: computer-vm Chassis: vm ... ...
经过重启后,终端中会显示改过后的主机名
master@qiu-k8s-m:~$
5. 安装docker
已经安装,输入docker -v可显示版本
master@qiu-k8s-m:~$ docker -v Docker version 20.10.17, build 100c701
将当前用户加入docker组,避免每次docker命令都用sudo。但是要使修改后的/etc/group生效得重启机器。
sudo groupadd docker #打开/etc/group最后一行会有docker:x:GID: sudo usermod -aG docker $USER #将当前用户加入到GID:后面
测试docker能否正常拉取镜像
master@qiu-k8s-m:~$ docker run -it ubuntu bash Unable to find image 'ubuntu:latest' locally latest: Pulling from library/ubuntu 2b55860d4c66: Pull complete Digest: sha256:20fa2d7bb4de7723f542be5923b06c4d704370f0390e4ae9e1c833c8785644c1 Status: Downloaded newer image for ubuntu:latest root@32cfec738c47:/#
能正常显示以上信息,则表示docker安装成功。
如果拉取速度太慢,是因为要从Docker Hub上下载,可修改相关文件
sudo vim /etc/docker/daemon.json #添加 { "registry-mirrors": ["https://alzgoonw.mirror.aliyuncs.com"], "live-restore": true }
并且执行
sudo systemctl daemon-reload sudo systemctl restart docker
来重启docker服务。更新后再拉取镜像就快很多了。
如果启动docker服务出现问题,可能是/etc/docker/daemon.json改的有问题,使用dockerd --debug排查
master@qiu-k8s-m:~$ sudo dockerd --debug unable to configure the Docker daemon with file /etc/docker/daemon.json: the following directives don't match any configuration option: __registry-mirrors
准备安装kubectl,kubelet,kubeadm
添加秘钥
master@qiu-k8s-m:~$ curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add - % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 2537 100 2537 0 0 898 0 0:00:02 0:00:02 --:--:-- 898 OK
添加Kubernetes软件源,采用ustc源
sudo vim /etc/apt/source.list.d/kubernetes.list
添加内容
deb http://mirrors.ustc.edu.cn/kubernetes/apt kubernetes-xenial main
由于xenial是ubuntu16.04的代号,而实验的机器是18.04,理应将xenial替换成bionic,但换过之后反而找不到源,于是再换回来。
安装kubelet,kubelet,kubeadm
更新源,然后使用apt-get install的方式安装
sudo apt-get update sudo apt-get install -y kubelet kubeadm kubectl sudo systemctl enable kubelet
查看节点试试
master@qiu-k8s-m:~$ kubectl get nodes The connection to the server localhost:8080 was refused - did you specify the right host or port?
或者报这个错误
master@qiu-k8s-m:~$ sudo kubectl get nodes Unable to connect to the server: dial tcp 192.168.230.246:6443: connect: no route to host
因为还没有布置节点,所以无节点显示。
将其他两个节点按同样的步骤过一遍。
配置master
配置环境变量
sudo vim /etc/profile
末尾加入
export KUBECONFIG=/etc/kubernetes/admin.conf
立即生效
source /etc/profile
重启kubelet
sudo systemctl daemon-reload sudo systemctl restart kubelet
初始化kubeadm
sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.230.246 --ignore-preflight-errors=NumCPU
报错
W0921 11:13:33.282440 3157 version.go:104] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://dl.k8s.io/release/stable-1.txt": context deadline exceeded (Client.Timeout exceeded while awaiting headers) W0921 11:13:33.282636 3157 version.go:105] falling back to the local client version: v1.25.1 [init] Using Kubernetes version: v1.25.1 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR CRI]: container runtime is not running: output: E0921 11:13:33.473505 3198 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" time="2022-09-21T11:13:33+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
解决办法,删掉/etc/containerd/config.toml文件,重启容器服务
sudo rm -rf /etc/containerd/config.toml systemctl restart containerd
可以跑起来,但是很慢,不过提示可以先执行sudo kubeadm config images pull这个命令
master@qiu-k8s-m:~$ sudo kubeadm init --image-repository registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.230.246 --ignore-preflight-errors=NumCPU [sudo] password for master: [init] Using Kubernetes version: v1.25.1 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' ^C
于是先拉镜像,同样很慢,不过还是熬结束了
master@qiu-k8s-m:~$ sudo kubeadm config images pull --image-repository registry.aliyuncs.com/google_containers [config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.25.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.25.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.25.1 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.25.1 [config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.8 [config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.4-0 [config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.9.3
再回来执行init那条语句,但是遇到错误
... [kubelet-check] Initial timeout of 40s passed. Unfortunately, an error has occurred: timed out waiting for the condition This error is likely caused by: - The kubelet is not running - The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled) If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands: - 'systemctl status kubelet' - 'journalctl -xeu kubelet' ...
说是kubelet没有跑起来?那就再执行下reload
error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists [ERROR Port-10250]: Port 10250 is in use
仍然报错,显示端口已在使用。键入kubeadm reset,会删掉一些东西。重新执行init语句,会在
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed
等好一会,然后重新出现
Unfortunately, an error has occurred: timed out waiting for the condition ...
查来查去,可能是之前删除/etc/containerd/config.toml文件导致,因此再新建,加入一些信息
先在当前目录生成这个文件
containerd config default > config.toml
打开文件,将k8s.gcr.io替换为registry.cn-hangzhou.aliyuncs.com/google_containers
60 restrict_oom_score_adj = false 61 sandbox_image = "k8s.gcr.io/pause:3.6" 62 selinux_category_range = 1024
改完后
60 restrict_oom_score_adj = false 61 sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.6" 62 selinux_category_range = 1024
将改完后的config.toml文件移动到/etc/containerd/下(当然也可以直接在/etc/containerd/目录下建文件,再修改)
再次执行init那句,仍然报错
.... This error is likely caused by: - The kubelet is not running - The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled) If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands: - 'systemctl status kubelet' - 'journalctl -xeu kubelet' ....
于是决定按照提示在init这句后加上–v=6来获取更详细的信息,可以看到
... I0926 22:36:31.414225 86362 round_trippers.go:553] GET https://192.168.230.246:6443/healthz?timeout=10s in 2720 milliseconds I0926 22:36:34.485995 86362 round_trippers.go:553] GET https://192.168.230.246:6443/healthz?timeout=10s in 2792 milliseconds I0926 22:36:37.557797 86362 round_trippers.go:553] GET https://192.168.230.246:6443/healthz?timeout=10s in 2863 milliseconds [kubelet-check] Initial timeout of 40s passed. I0926 22:36:40.630317 86362 round_trippers.go:553] GET https://192.168.230.246:6443/healthz?timeout=10s in 2935 milliseconds I0926 22:36:43.701762 86362 round_trippers.go:553] GET https://192.168.230.246:6443/healthz?timeout=10s in 3007 milliseconds ...
一直重复出现这几句,显然是健康检查时,连接主机地址超时了。通过ifconfig查看自己的ip已经改变,输入了一个不可用的ip,更改后,sudo kubeadm reset,再次init,终于出现了想要的输出
... [addons] Applied essential addon: kube-proxy I0926 22:45:05.364595 88564 loader.go:374] Config loaded from file: /etc/kubernetes/admin.conf I0926 22:45:05.366180 88564 loader.go:374] Config loaded from file: /etc/kubernetes/admin.conf Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.230.130:6443 --token 65rht0.rs2weic09flv5o8s \ --discovery-token-ca-cert-hash sha256:193cc3031acdde64264aba3b186e25462a2c8707b6d9bc27ba92393962d5eece
如果忘记保存join节点的token值,可输入命令
sudo kubeadm token create --print-join-command
根据以上提示需要输入
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
接着安装flannel网络组件
sudo kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
稍等一会执行可以看到ready的状态
master@qiu-k8s-m:~$ sudo kubectl get node NAME STATUS ROLES AGE VERSION qiu-k8s-m Ready control-plane 20m v1.25.1
执行init的过程中,由于旧的命令导致端口在使用,可以reset重设
[init] Using Kubernetes version: v1.25.2 [preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR Port-6443]: Port 6443 is in use [ERROR Port-10259]: Port 10259 is in use [ERROR Port-10257]: Port 10257 is in use [ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists [ERROR Port-10250]: Port 10250 is in use [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
端口被占用,重置试试
sudo kubeadm reset
重启kubeadm可以解决这个问题。
从节点配置
执行join那句报错
[preflight] Running pre-flight checks error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR CRI]: container runtime is not running: output: E0927 21:58:31.253378 27048 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" time="2022-09-27T21:58:31+08:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
初步判断是container有关的错误,查到这个资料,解决办法为
rm -rf /etc/containerd/config.toml systemctl restart containerd
后再执行join那句,最后能看到这个提示
... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. ...
表示把当前node加入到集群了,但是输入get nodes这句,仍然有报错
The connection to the server localhost:8080 was refused - did you specify the right host or port?
参考这篇,将主节点/etc/kubenetes/admin.conf拷贝到从节点的指定目录
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
再次执行,可看到节点信息列表
NAME STATUS ROLES AGE VERSION qiu-k8s-m Ready control-plane 82m v1.25.1 qiu-k8s-n2 NotReady <none> 10m v1.25.1
最后安装flannel网络组件
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
可能是网络连接错误
The connection to the server raw.githubusercontent.com was refused - did you specify the right host or port?
那么换种方式,将主节点的/etc/cni拷贝到从节点下的相同目录
cp -r /etc/cni /mnt/ sudo mv /mnt/cni /etc/
告一段落。
yaml文件里kind有四种类型,Pod,ReolicationController,Deployment,Service。
yaml文件tab和空格不能混用,不支持tab缩进。NodePort是对外提供的端口。
重新配置master节点和从节点,有错误如下
Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of "crypto/rsa: verification error" while trying to verify candidate authority certificate "kubernetes")
这是由于在sudo kubeadm reset时没有删除~/.kube/config文件所致(因为这个文件是手动拷过去的),解决办法重新拷一份
sudo cp /etc/kubernetes/admin.conf ~/.kube/config
从节点~/.kube/config也需要从主节点拷过去。
为什么配的从节点没有内部的ip?

通过查看pod详情
sudo kubectl describe pod httpd
错误细节

坑太多。。。未完待续
