简述ArcFace的原理
人脸识别的步骤分为人脸目标检测->特征提取->特征对比
在训练特征提取器的时候,我们要获得一个比较好的特征提取器,要求特征间分离得比较开,这样就不容易认错人了。
所以我们特别需要一个好的损失函数来完成大类间距的任务。
ArcFace其实就是从softmax loss衍生而来的,所以先要明白softmax loss是怎么一回事。
softmax和softmax loss虽然差不多,但这是不同的概念
个人认为比较讲的通俗易懂的softmax损失的链接,点击链接
为了使得特征之间分的更加开,ArcFace选择减少类内距,增加类间距的方式(角度)。
先看一下ArcFace loss的表达式
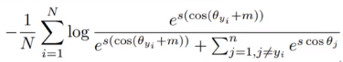
在softmax中,以e为底的指数
w x = ∥ w ∥ ∥ x ∥ cos θ = s × cos θ wx=\lVert w \rVert \lVert x \rVert \cos \theta =s\times \cos \thetawx=∥w∥∥x∥cosθ=s×cosθ
现在让θ \thetaθ变成了θ + m \theta+mθ+m

使得向量x与中心线向量w角度变大,这样设计的目的是为了在损失中增加角度的贡献量,从而使得优化过程中,角度收更小(也就是说w作为一个类别的中心线,w与x的角度变小),那么一个类别的x i x_ixi与其他类别的x j x_jxj之间的角度就增大了,从而实现了,减小类内距,增大类间距的方式。
看了下图应该就明白了,这是最终我们想要达成的目的。w 1 w_1w1与w 2 w_2w2对应两个中心线(也就是两个类),最后它们的类间距是比较大的。
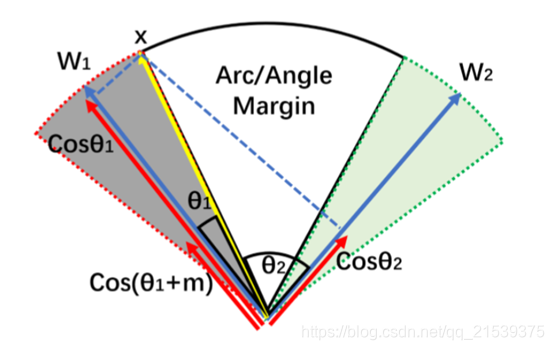
其中中心线w是一个可学习的参数,可以理解为一堆数据的中心线(类似二维平面中的一些点的聚类中心点)
ArcFace代码部分
下面是ArcFace实现的过程,为了方便理解这个损失,并不写过多累赘代码,并用比较小的特征数代替。实际人脸检测中所需要的特征向量的维度还是比较大的,以及Arc函数的还需要完善。
import torch from torch import nn import torch.nn.functional as F class Arc(nn.Module): def __init__(self,feature_dim=2,cls_dim=10): super(Arc, self).__init__() #x是(N,V)结构,那么W是(V,C结构),V是特征的维度,C是代表类别数 self.W = nn.Parameter(torch.randn(feature_dim,cls_dim)) def forward(self,feature,m=1,s=10): x = F.normalize(feature,dim=1) w = F.normalize(self.W,dim=0) cos = torch.matmul(x,w)/10 #(N,C) a = torch.acos(cos) #(N,C) top = torch.exp(s*torch.cos(a+m)) #(N,C) down = torch.sum(torch.exp(s*torch.cos(a)),dim=1,keepdim=True)-torch.exp(s*torch.cos(a)) #第一项(N,1) keepdim=True保持形状不变.这是我们原有的softmax的分布。第二项(N,C),最后结果是(N,C) out = torch.log(top/(top+down)) #(N,C) return out
c o s θ cos\thetacosθ用两个归一化后的x与w的乘积可得,因为c o s θ cos\thetacosθ为x与w的内积并除以它们的模。
x在第一维度归一化,w在第零维度归一化,因为后续作了矩阵相乘,torch.matmul(x,w),x的行乘以w的列。
对cos的结果还要除10,是因为torch.matmul(x,w)的范围不确定,可能会超过1,这样就超过arccos的定义域范围了,就会产生NaN的结果。当然后续也不需要乘回来,因为w是一个可学习参数,它会自己去改变。
至于s(w与x的模的乘积),乘在c o s θ cos\thetacosθ前就相当于一个超参数,和m一样。可以通过改变m(加减)和改变s(缩放),来调节你对最终想要特征间距的结果。
后续使用:
平时使用的交叉熵CrossEntropyLoss()是log+softmax+nn.NLLloss()
ArcFace就是将log+softmax替换成了Arc(),在角度上加了一个值,使得特征间的角度更加小(有点类似于正则化前的系数)。
现在需要一个特征提取器:比如desnet、resnet、mobileNetV2等等都行,它们的输出形状为(N,feature_dim)
将特征输入ArcFace层,得到输出形状(N,cls)
下面的net就是特征提取器+ArcFace层
提前定义一下损失
loss_fn = nn.NLLLoss()
训练过程中把损失这样写就行了
cls = net(xs) loss = loss_fn(cls, ys)
数据集载入,写一个特征提取器或者使用预训练模型,训练过程,这些常规流程就不再赘述了。