需要源码请点赞关注收藏后评论区留言私信~~~
Dataset和DataLoader都是用来帮助我们加载数据集的两个重要工具类。Dataset用来构造支持索引的数据集
在训练时需要在全部样本中拿出小批量数据参与每次的训练,因此我们需要使用DataLoader,即DataLoader是用来在Dataset里取出一组数据(mini-batch)供训练时快速使用的
1:Dataset简介及用法
Dataset本质上就是一个抽象类,可以把数据封装成Python可以识别的数据结构。
Dataset类不能实例化,所以在使用Dataset的时候,我们需要定义自己的数据集类,也是Dataset的子类,来继承Dataset类的属性和方法。
Dataset可作为DataLoader的参数传入DataLoader,实现基于张量的数据预处理。
Dataset主要有两种类型,分别为Map-style datasets和Iterable-style datasets
Map-style datasets类型
实现了__getitem__()和__len__()方法,它代表数据的索引到真正数据样本的映射。
读取的数据并非直接把所有数据读取出来,而是读取的数据的索引或者键值 这种类型是使用最多的类型,采用这种访问数据的方式可以大大节约训练时需要的内存数量,提高模型的训练效率
Iterable-style datasets类型
实现了__iter__()方法,与上述类型不同之处在于,他会将真实的数据全部载入,然后在整个数据集上进行迭代 这种读取数据的方式比较适合处理流数据
自己定义子类
上面我们提到,Dataset作为一个抽象类,需要定义其子类来实例化。所以我们需要自己定义其子类或者使用已经定义好的子类
必须要继承已经内置的抽象类dataset 必须要重写其中的__init__()方法、__getitem__()方法和__len__()方法 其中__getitem__()方法实现通过给定的索引遍历数据样本,__len__()方法实现返回数据的条数
已经定义好的内置子类
TensorDataset(对应Map-style datasets类型)
对于给定的tensor数据,TensorDataset是一个包装了Tensor的Dataset子类,传入的参数就是张量,每个样本都可以通过Tensor第一个维度的索引获取,所以传入张量的第一个维度必须一致
IterableDataset(对应Iterable-style datasets类型)
部分代码如下
import torch from torch.utils.data import Dataset class MyDataset(Dataset): def __init__(self): pass def __getitem__(self, index): pass def __len__(self): pass import torch from torch.utils.data import Dataset class GetTrainTestData(Dataset): def __init__(self, input_len, output_len, train_rate, is_train=True): super().__init__() # 使用sin函数返回10000个时间序列,如果不自己构造数据,就使用numpy,pandas等读取自己的数据为x即可。 # 以下数据组织这块既可以放在init方法里,也可以放在getitem方法里 self.x = torch.sin(torch.arange(0, 1000, 0.1)) self.sample_num = len(self.x) self.input_len = input_len self.output_len = output_len self.train_rate = train_rate self.src, self.trg = [], [] if is_train: for i in range(int(self.sample_num*train_rate)-self.input_len-self.output_len): self.src.append(self.x[i:(i+input_len)]) self.trg.a def __len__(self): return len(self.src) # 或者return len(self.trg), src和trg长度一样 data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True) data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False) import torch from torch.utils.data import TensorDataset src = torch.sin(torch.arange(1, 1000, 0.1)) trg = torch.cos(torch.arange(1, 1000, 0.1))
二、DataLoader简介及用法
Dataset和DataLoader是一起使用的,在模型训练的过程中不断为模型提供数据,同时,使用Dataset加载出来的数据集也是DataLoader的第一个参数。所以,DataLoader本质上就是用来将已经加载好的数据以模型能够接收的方式输入到即将训练的模型中去
数据的输入过程
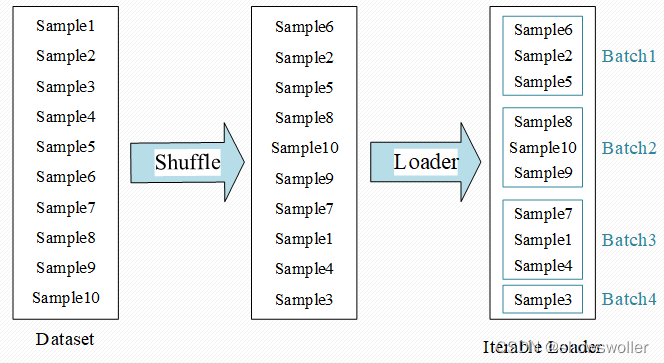
Data_size=10,Batch_size=3,一次Epoch需要四次Iteration,第一列为所有样本,第二列为打乱之后的所有样本,由于Batch_size=3,所以通过DataLoader输入了4个batch,包括最后一个数量已经不够3个的Batch4,里边只包含sample3
DataLoader函数参数
Dataset:通过上一节Dataset加载出来的数据集
batch_size:每个batch加载多少个样本
shuffle:是否打乱输入数据的顺序
import torch from torch import nn from torch.utils.data import Dataset, DataLoader class GetTrainTestData(Dataset): def __init__(self, input_len, output_len, train_rate, is_train=True): super().__init__() # 使用sin函数返回10000个时间序列,如果不自己构造数据,就使用numpy,pandas等读取自己的数据为x即可。 # 以下数据组织这块既可以放在init方法里,也可以放在getitem方法里 self.x = torch.sin(torch.arange(1, 1000, 0.1)) self.sample_num = len(self.x) self.input_len = input_len seoutput_len = output_len sf.train_rate = train_rate self.src, self.trg = [], [] if self.src.append(self.x[i:(i+input_len)]) self.trg.append(self.x[(i+input_len):(i+input_len+output_len)]) else: for i in range(int(self.sample_num*train_rate), self.sample_num-self.input_len-self.output_len): self.src.append(self.x[i:(i+input_len)]) self.trg.append(self.x[(i+input_len):(i+input_len+output_len)]) print(len(self.src), len(self.trg)) def __getself.src) # 或者return len(self.trg), src和trg长度一样 data_train = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=True) data_test = GetTrainTestData(input_len=3, output_len=1, train_rate=0.8, is_train=False) data_loader_train = DataLoader(data_train, batch_size=5, shuffle=False) data_loader_test = DataLoader(data_test, batch_size=5, shuffle=False) for idx, train in enumerate(data_loader_train): print(idx, train) break
创作不易 觉得有帮助请点赞关注收藏~~~
