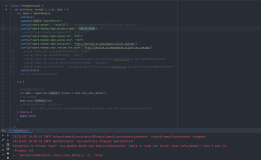
在MaxCompute中,如果你想让Spark的行为更接近Hive,你可以设置odps.sql.hive.compatible为TRUE。然后,你可以使用CONCAT_WS函数来连接字符串,其中null值将被忽略。
你的查询应该修改为:
SET odps.sql.hive.compatible=TRUE;
SELECT CONCAT_WS(':', '123', NULL, '456') AS test;
这将返回一个结果,其中包含三个字段的值,即'123:NULL:456'。注意,NULL值被忽略了,而不是被视为空白。