运行大数据服务对服务器的配置要求是比较高的,相应的经济成本也不会低。本人做数据分析相关工作,一直在寻找高性能低成本的开源OLAP引擎,但是并没有找到,既然这样,那就自己搞一个。
EuclidOLAP
EuclidOLAP是我搞的一个开源OLAP多维数据库,它目前具有以下的几个特点:
- 针对百亿级别数据量查询时可以达到毫秒级响应;
- 能够支持非常复杂的查询,包括跨模型的关联查询;
- 支持实时的增删改查;
- 可以部署为集群模式,也能以单机模式运行在低配置服务器上。
在将来EuclidOLAP将会演化成基于云原生、容器、弹性资源的存算分离的架构模式。
EuclidOLAP的Github地址:https://github.com/EuclidOLAP/EuclidOLAP
剩下的内容分为两部分,首先简要介绍一下EuclidOLAP的数据模型与存储结构,然后在一台3G内存的低配服务器上运行一个EuclidOLAP示例并对一个一亿数据量的模型进行分析。
数据模型与存储结构
EuclidOLAP采用了立方体(Cube)和维度(Dimension)作为数据模型,如下所示:

维度就相当于坐标轴,你可以将一个关联个N个维度的Cube想象成一个N维立方体,同时把所有度量值想象成是存储于一个多维数组中。多维数组结构会带来一个严重的问题——内存容量爆炸,为了解决这个问题,像Cogons、Essbase这些传统多维数据库的解决办法是采用稀疏维和密集维结构:稀疏的几个维度被构建为索引,密集的维度则被构建为数据块——相对密集的更小的多维数组。
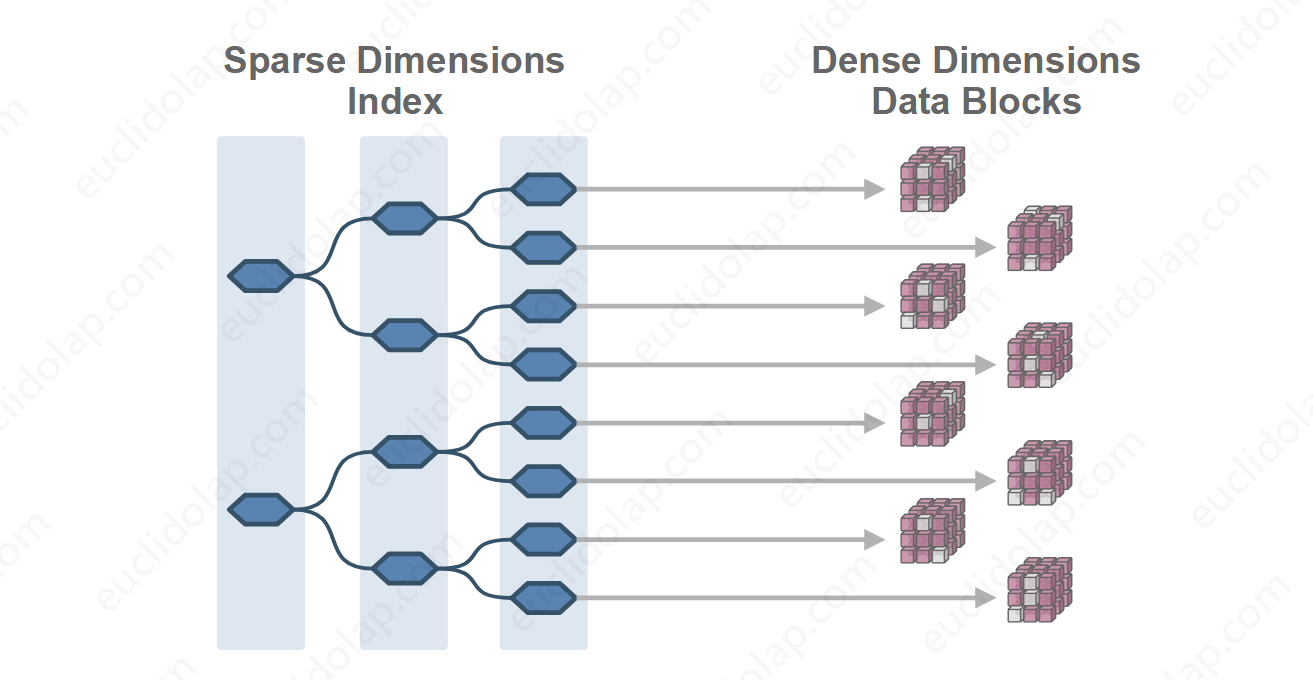
由于根据密集维构成的数据块也会存在数据空洞,所以上述的这种数据结构也会浪费掉一些内存。
EuclidOLAP的解决办法是在多维数组元素前面添加坐标偏移量,然后进行完全压缩,这样虽然也需要额外的内存来存储偏移量数据,但其消耗的内存相对于前面那两种结构来说是可以忽略不计的。
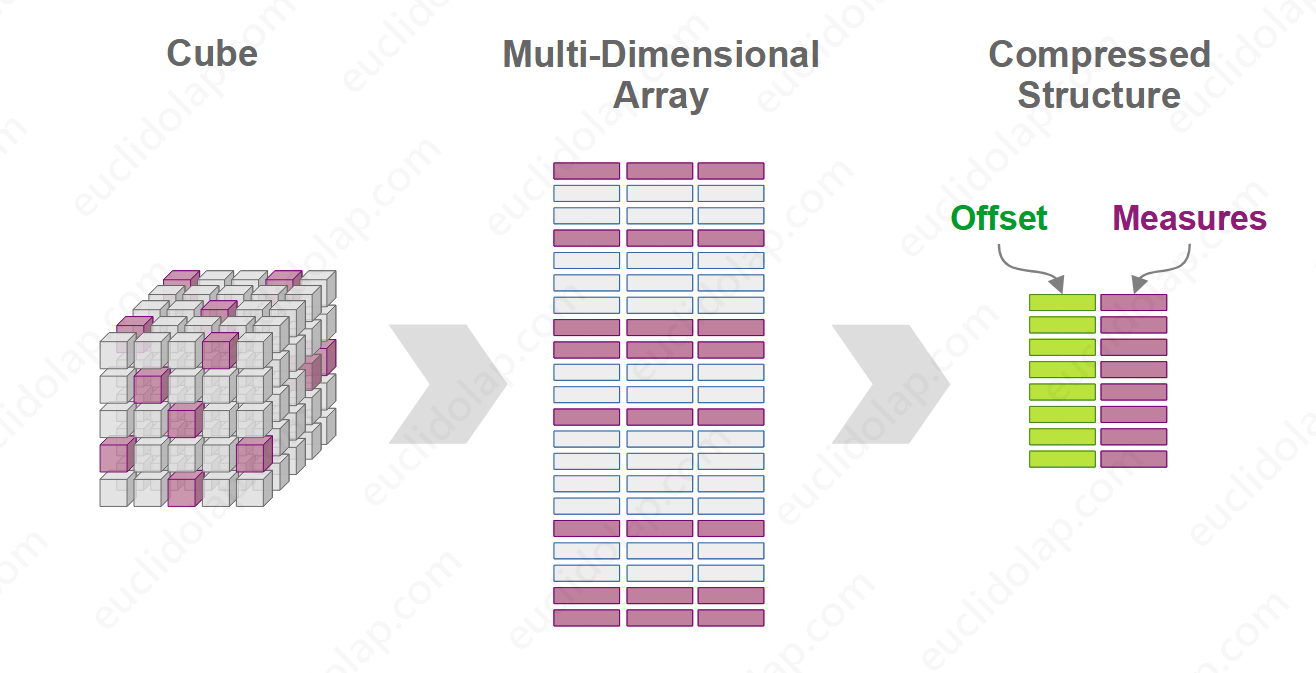
EuclidOLAP会同时构建一个索引结构,它会根据数据偏移量进行快速定位,以确定度量数据的坐标和聚合查询时的数据范围。
在逻辑层面,EuclidOLAP的这个索引结构很像图-2中稀疏维索引,但不同之处在于EuclidOLAP的这个索引结构可以表示从全部稀疏维到全部密集维的各种情况,我给它起了个名字——弹性索引结构。
在一个关联个N个维度的Cube中,弹性索引可以表示N+1种索引结构:
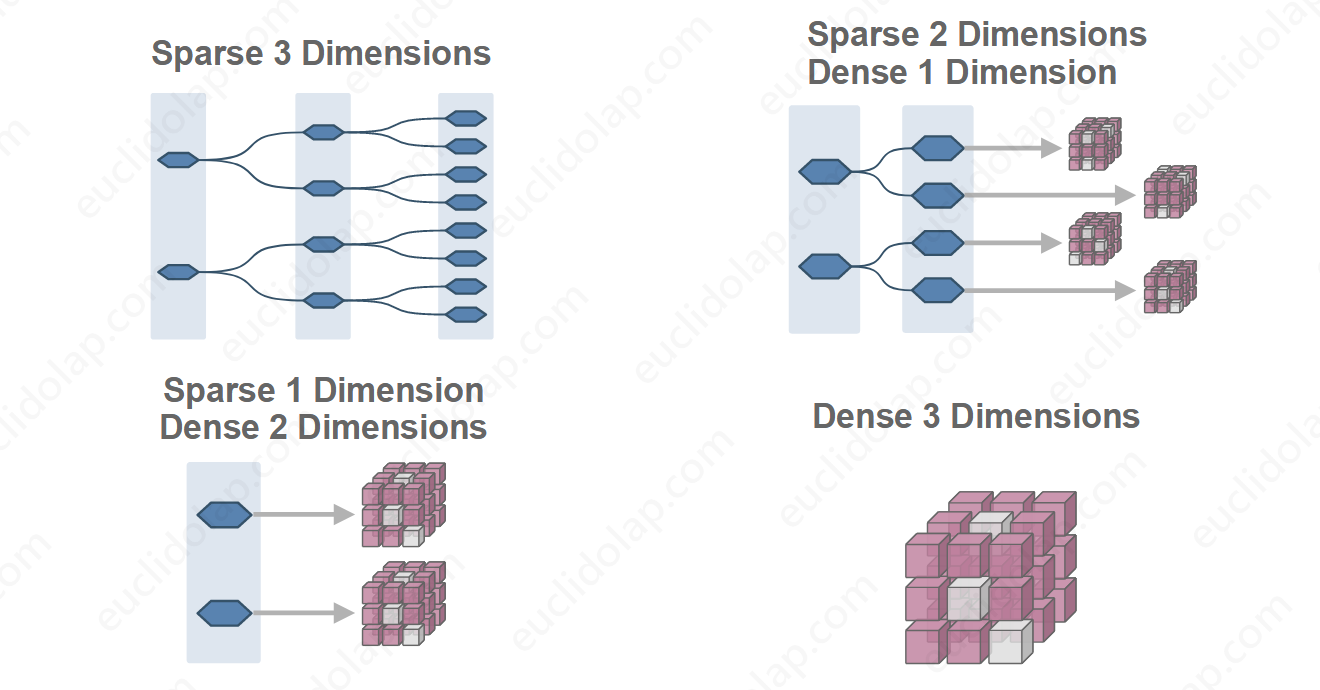
在逻辑模型层面,你还是可以将EuclidOLAP Cube中的度量数据想象成是存储于一个有着大量数据空洞的巨大的多维数组之中。
这种弹性索引结构同样存在问题,在新增数据时会导致整个数据结构的变化,我会在以后的文章中专门来介绍针对这个问题的解决办法。
接下来进入实践环节。
运行EuclidOLAP服务实例
EuclidOLAP中自带了一个一亿数据量的Cube,它需要占用不到2G内存,我在一台2400M内存的机器上运行过,你需要准备一台CentOS、Redhat、Ubuntu或Debian服务器,内存最好不低于3G。
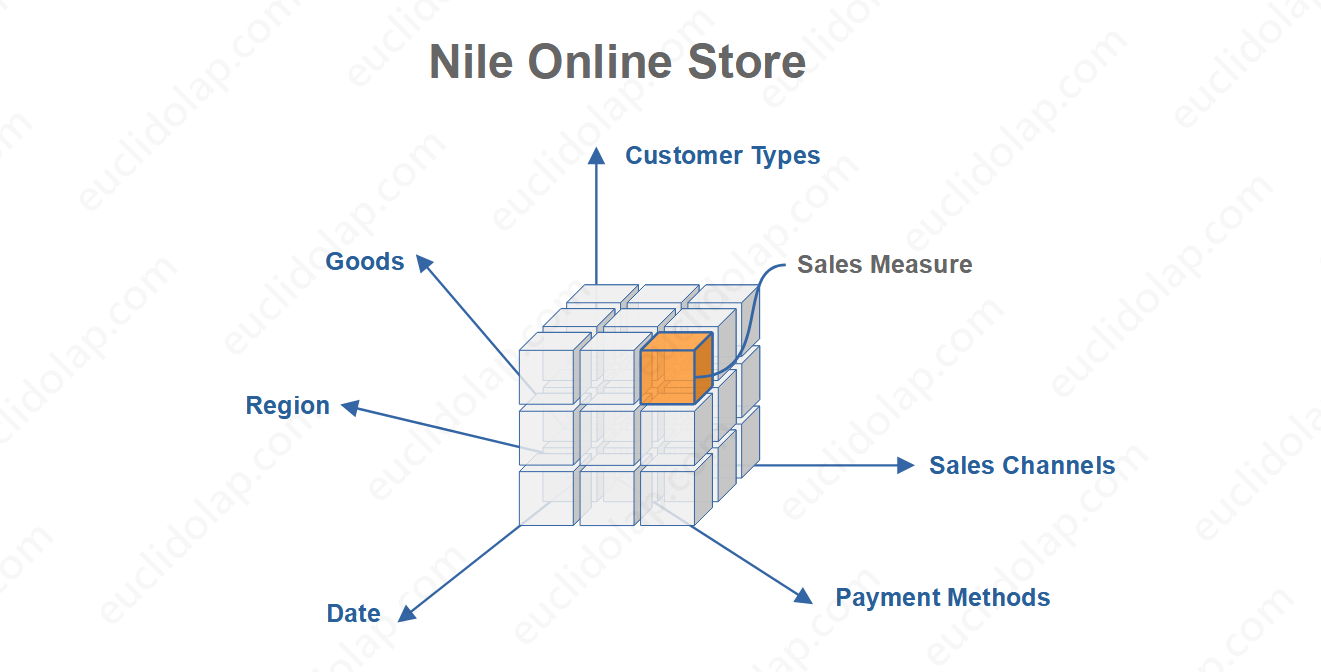
EuclidOLAP自带了一个名为Nile Online Store的Cube,它关联了六个维度:日期(Date )、地区(Region )、商品(Goods )、支付方式(Payment Methods )、客户类型(Customer Types )、销售渠道(Sales Channels )。
点击这个链接查看这6个维度的详细结构:http://www.euclidolap.com/attachments/nos.html
这个Cube有一个度量值:Sales,为了演示方便,所有的明细度量值都是1。
EuclidOLAP支持多维数据库的标准语言——MDX(Multi-Dimensional Expressions ),它在语法结构上类似于SQL,不同之处在于MDX在语义层面直接描述多维结构,它对于复杂分析的支持能力要强于SQL。
按下面的步骤下载并运行EuclidOLAP服务:
wget https://sysbase.oss-cn-beijing.aliyuncs.com/EuclidOLAP-v0.1.6.1.tar.gz
tar zxvf EuclidOLAP-v0.1.6.1.tar.gz
cd EuclidOLAP
./bin/start.sh &
查看日志:
tail -n 5 log/euclid.log

当日志中显示了Net service startup on port 8760内容时表示EuclidOLAP已经成功运行。
第一个MDX是一个执行全汇总的查询
select
[Measures].Sales on 0,
Date.[ALL] on 1
from [Nile Online Store];
在EuclidOLAP目录中运行olap客户端工具:
./bin/olap-cli
执行MDX查询:
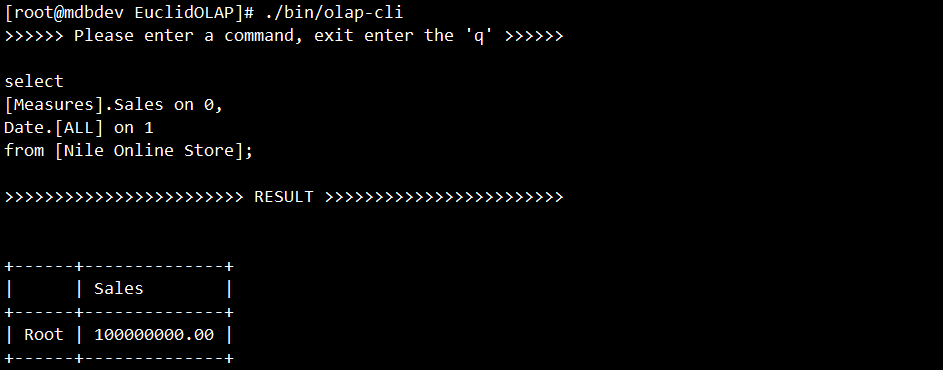
这个查询将全部明细数据汇总查出,结果是100000000。
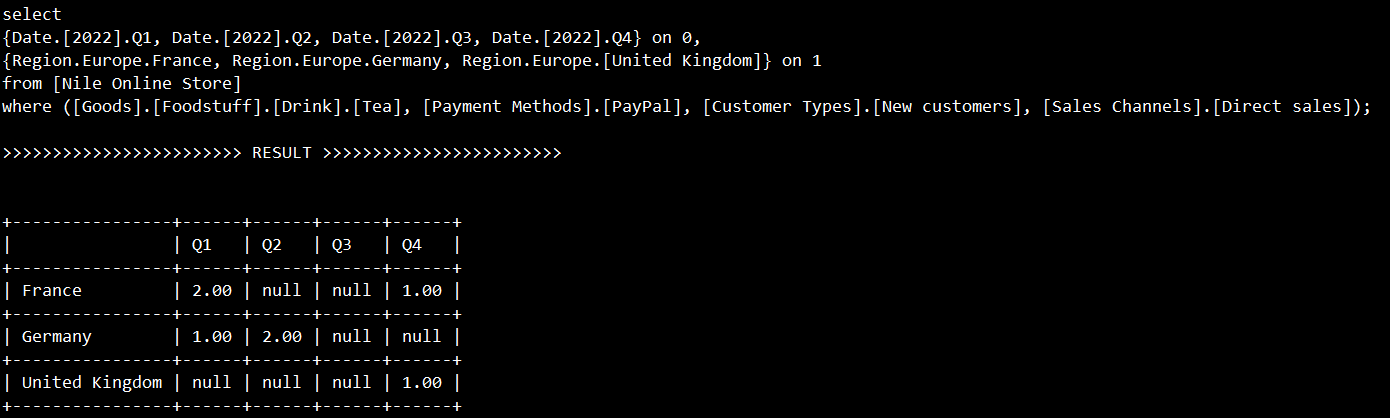
第二个MDX对明细数据进行查询
它在商品维度(Goods )、支付方式维度(Payment Methods )、客户类型维度(Customer Types )和销售渠道维度(Sales Channels )上进行了限定,然后按日期维度(Date )和地区维度(Region )查看Sales度量值:
select
{Date.[2022].Q1, Date.[2022].Q2, Date.[2022].Q3, Date.[2022].Q4} on 0,
{Region.Europe.France, Region.Europe.Germany, Region.Europe.[United Kingdom]} on 1
from [Nile Online Store]
where
([Goods].[Foodstuff].[Drink].[Tea], [Payment Methods].[PayPal], [Customer Types].[New customers], [Sales Channels].[Direct sales]);
执行这个MDX将立即返回结果。
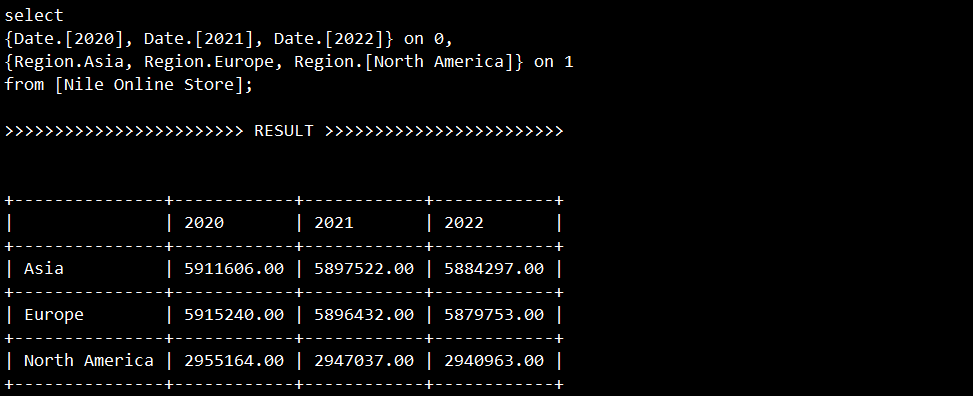
第三个MDX与第二个类似
它没有在日期和地区之外的其他维度进行限定,该查询将在其他四个维度上进行汇总。日期和地区维度分别指定了年份和洲级别的维度成员,这要比第二个MDX具有更高的汇总粒度。
select
{Date.[2020], Date.[2021], Date.[2022]} on 0,
{Region.Asia, Region.Europe, Region.[North America]} on 1
from [Nile Online Store];
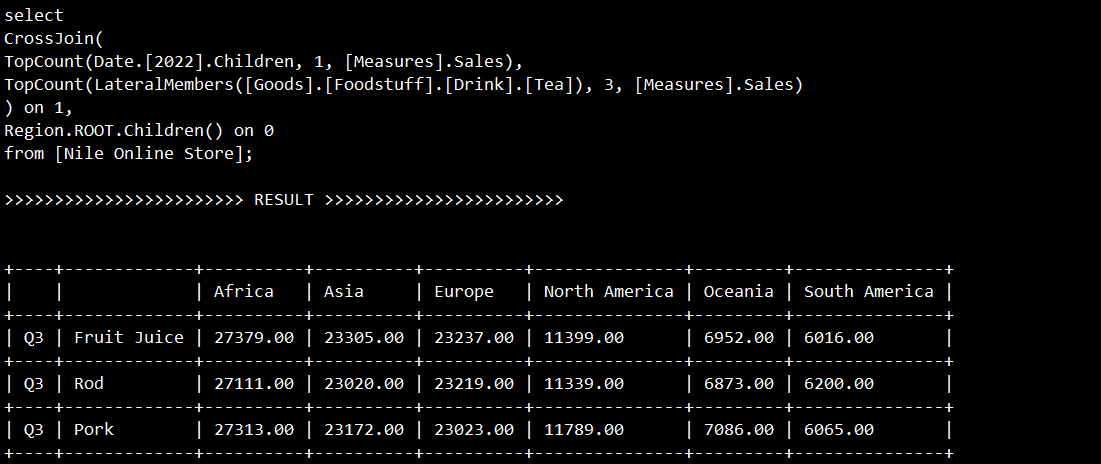
第四个MDX是一个复杂逻辑的查询
它将按地区查询2022年总体销售额最高的那个季度的前三种畅销商品的销售数据:
select
CrossJoin(
TopCount(Date.[2022].Children, 1, [Measures].Sales),
TopCount(LateralMembers([Goods].[Foodstuff].[Drink].[Tea]), 3, [Measures].Sales)) on 1,
Region.ROOT.Children() on 0
from [Nile Online Store];
最后说一下MDX这个东西。MDX 与SQL 语法相似,如同SQL 查询一样,每个MDX 查询都要求有SELECT、FROM 和可选的WHERE部分。SQL的语义模型描述Table结构,MDX的语义模型描述Cube结构,相同的一套业务模型可以放在SQL星型表结构中,也可以放在MDX Cube模型中,但是基于Cube使用MDX能更好的支持复杂且比SQL更加直观。关于MDX的详细介绍我也会发布在以后的文章中。
