一、算法原理
KNN算法属于监视类算法,即需要人类自己进行将数据分类,然后根据已知的数据类型来预测未知的数据类型
KNN算法
第一步:先在数据库里面引入数据
第二步:先预先设定不同的类别,我设为 0 类于1类
第三步:再在数据库中引入数据与已预先设定的个类别进行欧式计算
第四步:对计算得到的数据进行排序,然后取计算得到的最小的n个数据
#第五步:对这n个数据统计,计算出各个类别的频数并排序,最后打印出类别频数最多的类别
二、源代码
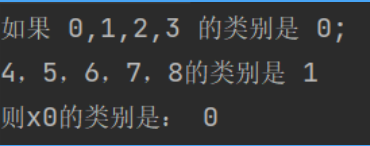
# 基本数据 x=[0,1,2,3,4,5,6,7,8] # 样本距离 y=[0,0,0,0,1,1,1,1,1] # 类别 x0=3.1 # 根据到各个样本距离来判断类型 # 算出x0到其他所有值的距离,并将0,1表示的类别与之对应 data=[] for i in range(len(x)): dis=(x[i]-x0)**2 data.append((y[i],dis)) # 元组有两个数据并入列表中 ,第一个数据为类型,第二个数据为距离 #根据第二个值来排序 data_one=sorted(data, key=lambda x: x[1]) # 按元组第二个数据进行排序 #只取距离最近的前三个来比较,选最优的类别 k = 5 # 超参数 data_two=data_one[:k] c={} for i in data_two: # data_two 为列表,该列表包括元组,一个元组里面包含了两个数据 if i[0] in c.keys(): # i[0] 为元组的第零个元素,即类别 c[i[0]]=c[i[0]]+1 # c[i[0]]为字典对应的值,即类别出现的频次 else: c[i[0]]=1 #再根据上一步的结果,再进行排序(不排序则是按出现什么情况,进行将什么情况并入字典中,是无序排列的) type_max=sorted(c.items(), key=lambda x:x[1]) # #返回列表,里面包含元组 print("如果 0,1,2,3 的类别是 0;\n4,5,6,7,8的类别是 1") print("则x0的类别是:",type_max[-1][-2])
三、实验结果及总结
由图片可知,分类符合我们的预期。