Datatphin V3.11版本全新上线补数据任务功能,支持将单次补数据保存为补数据任务,保存补数据节点范围及运行规则;支持补数据任务定时调度,自动定期回刷历史数据;支持手动运行补数据任务。满足企业复杂多样的回刷历史数据的需求,减少人工操作成本。
背景
小月是某企业的数据分析人员,在她的日常工作中经常面临一些问题:
小月需要处理收入分摊数据,数据隔几天会不定期下发一次,为保证数据准确性和及时性,每次下发数据后,小月需要手动更新最近两个月的数据。这个过程非常繁琐和重复,每次都需要手动执行相同的操作。这样一来,小月需要花费大量的时间和精力来完成这个任务。
每个月初,小月需要根据最新的数据统计口径更新上个月整月的数据以进行统计和计算指标,保证及时准确地输出数据报表和进行数据分析。小月需要每个月月初手动执行相同的补数据操作,而涉及到的节点较多,上下游依赖复杂,在选择节点时容易出错,小月需要对照历史的补数据记录进行重复配置。
此外,小月每个月需要手动上传数据表,并且需要在上传数据后手动刷新该表以及相关的上下游数据。这个过程需要根据数据依赖关系依次点击运行一组手动任务,等一个任务运行成功后再手动运行下游的任务。这个过程非常繁琐和容易出错,需要小月花费大量的时间和精力。
小月的日常工作充斥着繁琐的重复操作,Dataphin新功能上线后,小月使用了补数据任务的功能,通过一次简单的配置轻松地解决了上述的各种问题。
小月创建了一个补数据任务,自动保存了节点选择和运行规则的配置。每次下发收入分摊数据后,她只需要点击一次运行,就能帮助实现数据的更新,省去了她重复配置补数据的繁琐过程。
她还创建了一个每月1号回刷最近两个自然月数据的补数据任务。每月1号,补数据任务会自动执行,帮助小月更新上个月整月的数据,快速生成数据报表和计算指标,无需再进行重复操作。
对于每个月手动上传数据表后依次运行手动任务刷新数据的操作,小月将该组手动任务配置为空跑调度的周期任务,并配置好上下游的依赖关系。然后,她再配置了一个手动运行的补数据任务,将节点范围保存起来。当她每次上传数据表后,只需要手动运行一次补数据任务,无需再进行繁琐的手动任务运行操作,节省了大量的时间和精力。
借助补数据任务的功能,小月实现了通过一次简单的配置,轻松解决以上问题,满足她在类似场景中的各种需求。这个功能大大简化了繁琐的手动操作过程,提高了小月的工作效率和准确性。现在,小月可以更专注于数据分析的工作,而不用再花费大量的时间和精力在重复性的操作上了。
功能介绍
补数据任务支持将单次补数据保存为补数据任务,保存补数据节点范围及运行规则;支持补数据任务定时调度,自动定期回刷历史数据;支持手动运行补数据任务。
以场景二为例,实现每月3号自动回刷上个月整月数据,具体操作步骤如下:
- 进入 Dataphin > 研发 > 运维 > 补数据任务
- 填写基本信息
- 选择补数据范围,需要先选择一个起始节点,选择起始节点的下游任务作为补数据范围
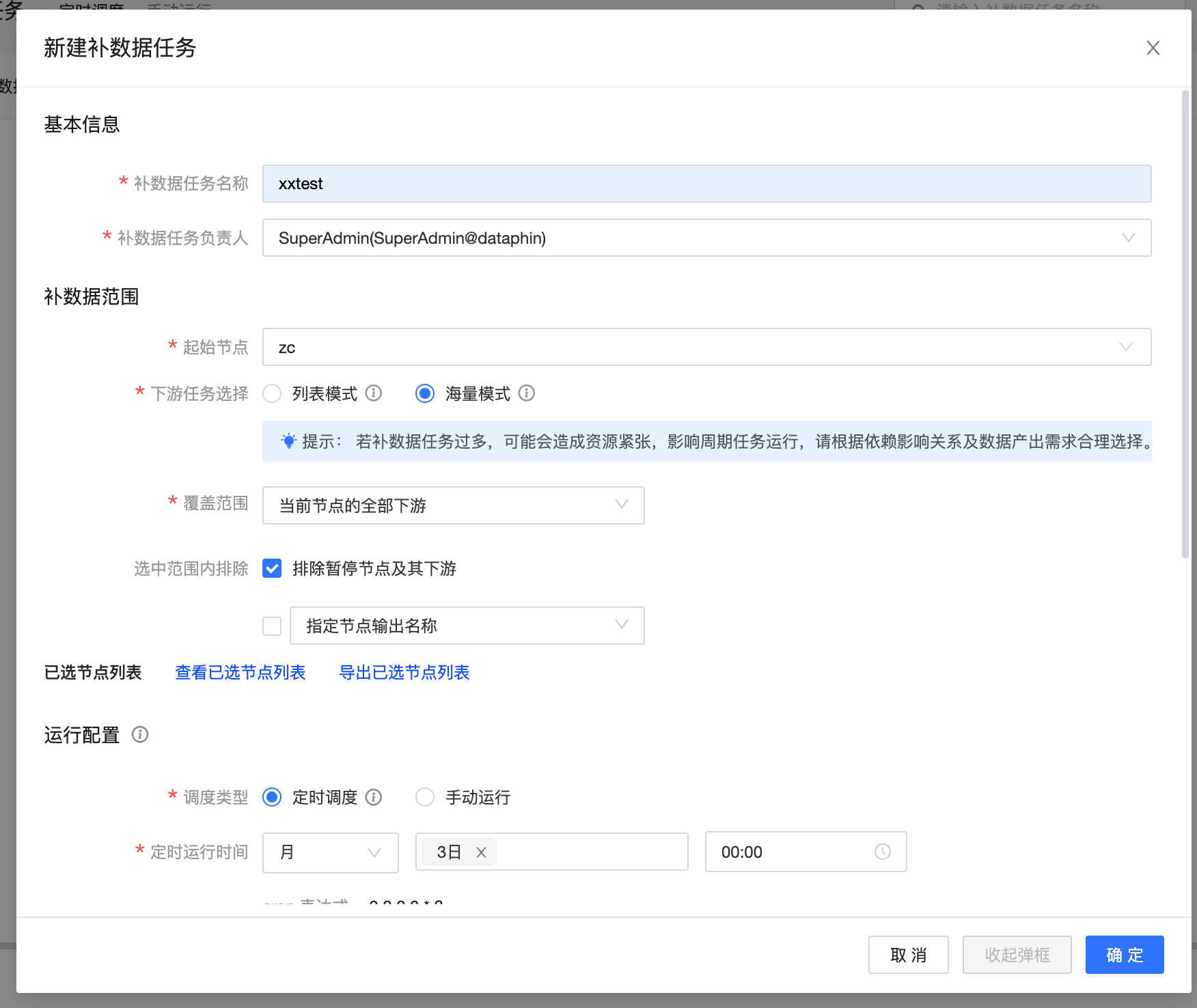
- 进行运行配置
a. 调度类型:选择定时调度
b. 定时运行时间:选择 月 3日 00:00
c. 补数据业务日期:选择最近N个自然月 1月自然月
d. 预览最近运行时间及补数据业务日期:通过预览可以查看补数据任务的最近五个执行计划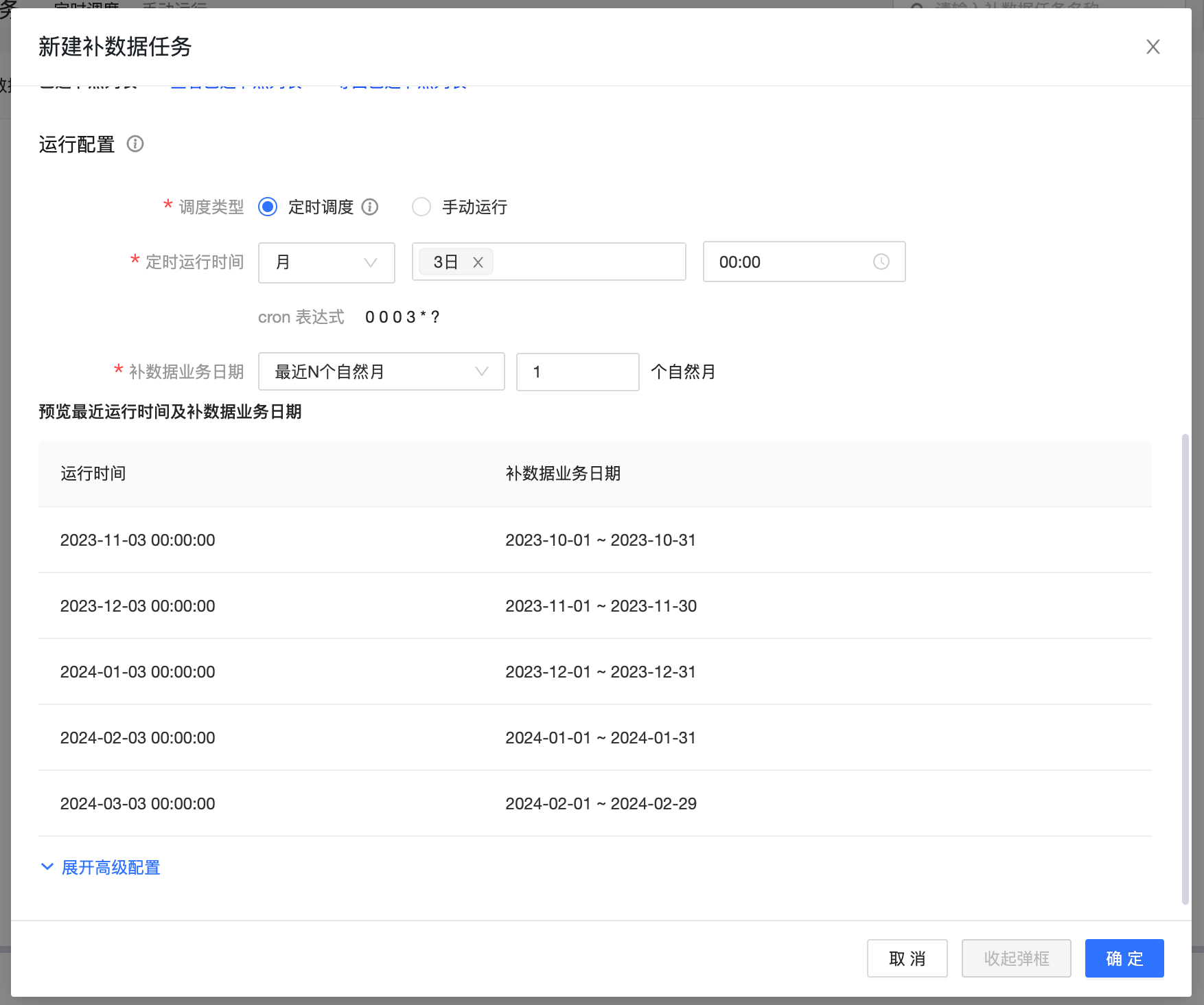
- 点击 确定,可以在补数据任务列表中查看和操作该任务,包括设置生效状态,手动运行,编辑,修改负责人,删除等
手动运行该补数据任务相当于复用该任务所选的补数据节点范围及运行规则进行一次临时补数据,需要手动重新设定本次临时补数据的运行时间和业务日期 - 在定时运行时间的前一天的23点将会生成待提交实例,可以在 运维 > 补数据实例 > 待提交实例中查看,在定时运行时间前可以对该实例进行暂停操作;到达定时运行时间后,系统将会自动提交执行该补数据实例,可以在 运维 > 补数据实例 > 已提交实例中查看。
总结
类似的场景可以通过以上操作解决,场景三中提出的希望给手动任务添加依赖的需求也可以通过补数据任务解决,具体操作为:将该组手动任务配置为空跑调度的周期任务并为配置好上下游依赖关系,再配置一个手动运行的补数据任务将节点范围保存起来,设置空跑调度的任务补数据时正常跑,每次只需要手动运行一次补数据任务即可。补数据任务的功能能够很好的满足各种定时回刷历史数据的需求,大大降低人工操作和运维成本,为您带来更好的使用体验,欢迎体验!
