1.简介
近年来,汽车行业发生了重大变革,车辆从机械系统转向高度软件驱动的系统。如今,软件已成为汽车制造商最重要的因素[1],车辆中约80%的功能都是通过软件实现的[2]。现代生产车辆通常有100多个电子控制单元(ECU),具有数百万条代码线[3,4]。随着软件在车内和外部设备之间的互联程度越来越高,以及自动驾驶功能具有更广泛的功能和更严格的法规,这种已经很高的复杂性预计将呈指数级增长[1]。
随着汽车软件的复杂性不断增加,ECU内部的底层控制算法的重要性也在增加,ECU通过将传感器信息转换为执行器的控制命令来操作车辆的机电子系统。因此,控制功能最终负责车辆的安全和环保操作,并对整体性能产生重大影响。在V模型[5]规定的传统汽车软件开发过程中,控制功能开发发生在过程的早期阶段,通常涉及模型在环(Mi L)模拟。然后,将产生的控制功能转换为目标硬件的机器代码,并部署在ECU上,通常首先在硬件在环(Hi-L)环境中,随后开始微调控制参数的校准过程[6]。尽管开发过程的某些步骤,特别是代码生成和测试[7],是部分自动化的,但大多数功能开发和校准过程仍然高度依赖于人类专家。然而,这些任务的工作量不断增加,这主要是由于几个因素导致功能开发[1]的复杂性增加所致。对可持续交通的迫切需求以及相关的更严格的法规,如预期的欧7排放标准,正在提高性能要求[8]。此外,ECU传感器和执行器的数量不断增加,不仅导致需要实现额外的功能,而且由于彼此之间的复杂交互,其开发也变得更加困难。与此同时,车辆变体的数量以及对特定、单独软件的需求正在增加[9]。最后,由于传感器信息和场景的数量以及高安全要求,自动驾驶功能的引入导致复杂性急剧增加[1]。因此,功能开发是一个耗时、成本高昂的过程,即使对高技能的专业人员来说也是一个挑战。结合不断缩短的产品周期和普遍的成本压力,该过程容易产生次优解决方案,无法充分利用现有潜力。因此,为了将工作保持在可行的水平并仍然获得高性能的控制功能,对过程自动化的需求正在增加。
强化学习(RL)构成了一种机器学习范式,旨在学习最优控制策略[10]。在RL中,代理从其环境中观察状态,并以奖励或惩罚的形式接收对其行为的反馈。通过试错的交互,代理仅从训练过程中收集的经验中得出其策略。这种适应环境并在没有人为指导的情况下发展端到端控制策略的能力使RL对功能开发过程中的自动化特别感兴趣。由于缺乏导出控制函数的可调参数,它结合了函数开发和校准,从而导致校准过程的前置。通过利用深度神经网络,RL特别适用于具有复杂、非线性环境和高维状态和动作空间的汽车嵌入式系统。
RL的上述潜力已导致在汽车控制领域的各种应用。表1显示了按用例分类的常见车辆RL应用程序,并且由于所有代理都是在纯虚拟环境中训练的,因此按所使用的模拟软件进行了分类。该表并不是对所有现有文献的全面综述,而是对常见用例的概述和分类。
表1。RL在汽车控制领域的应用。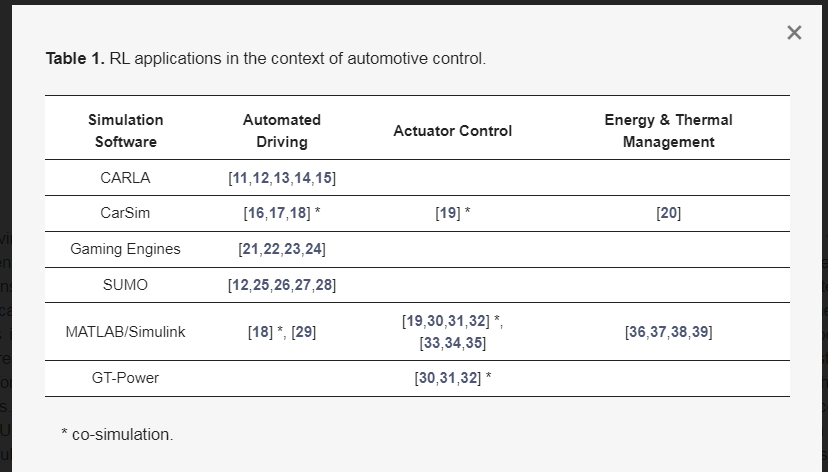
基于RL的自动驾驶是一个非常活跃的研究领域,有许多出版物。表1中本栏中总结的文章描述了RL代理直接影响车辆纵向或横向运动的方法,例如通过控制期望的纵向加速度或转向角。该领域的出版物涵盖了广泛的应用,例如变道[15]、匝道合并[27]或自动停车[18]。此外,这些出版物在研究的场景方面有所不同,如市中心[29]或高速公路[23]驾驶,以及它们的主要优化目标,如提高安全性[14]或能源效率[28]。模拟工具的选择取决于研究的具体目的。自动驾驶在很大程度上依赖于准确的感知,因此逼真的3D场景和准确的传感器模拟对于具有逼真传感器视觉的研究至关重要。因此,3D模拟CARLA或Car Sim是流行的工具,但游戏引擎也经常使用,因为它们通常具有复杂的图形。另一方面,更侧重于战略决策的研究通常采用微观交通模拟和城市交通模拟(SUMO),因为它真实地描述了整体交通动态。它可以单独使用,例如在交通流优化[25]中,也可以在联合模拟中使用,负责模拟周围的交通。MATLAB/Simulink是汽车领域应用最广泛的工具之一,由于其高度的灵活性和定制能力,在这一研究领域的使用频率较低。
表1中的转向柱致动器控制是指RL代理直接控制车辆的至少一个主动部件的研究。这些用例的特征通常是在外部边界条件下优化控制轨迹,例如需要产生的特定扭矩。文献提供了动力系内部各种致动器的控制,例如内燃机的主动涡轮增压器或废气再循环(EGR)阀[30,31,33]或电动机的逆变器[34]。此外,动力系之外的应用,如主动转向系统[19]或半主动悬架[35]控制,可以在文献中找到。这里,使用专门的模拟来对包含受控组件的特定系统进行建模。这通常涉及在MATLAB/Simulink中开发自定义模型,或使用GT Power等专用工具进行内燃机建模。
第三列介绍了具有更具战略性控制任务的汽车RL应用,操作整个系统而不是某些组件。其中包括用于混合动力系统管理的基于RL的控制策略([36,37,38]),以及电动汽车的扭矩分配[20]和热管理[39]。与执行器控制类似,这里的工具和模拟模型更适合特定的用例。
尽管RL具有不可否认的潜力,许多有前景的概念验证研究(见表1)表明了RL代理解决复杂车辆控制问题的能力,但仍存在一些重大挑战,阻碍了RL在汽车行业的广泛使用。RL仍然处于原型状态的一个原因是,所有研究都使用了不同的工具,这些工具适用于给定的用例,但由于与传统开发过程不兼容,很难转移到实际应用程序中。这些工具很难集成到现有的开发管道中,具有实时性能限制,或者不符合行业标准和法规。此外,由于RL特工的黑匣子性质,存在普遍的安全问题。基于RL的控制器的泛化能力和鲁棒性目前还不能得到保证[40],因此必须建立新的测试方法,以确保在所有可能的场景中安全运行。最后,它的试错方法导致对计算成本高昂的训练集的高需求,通常需要数千个来解决甚至相对简单的问题,这加剧了它在许多不同任务中的应用难度。
我们的贡献旨在降低基于RL的控制功能的进入壁垒,并试图使其更接近于在生产车辆中的应用。我们介绍了一个更适合基于RL的自动化控制功能开发需求的框架,并展示了一个潜在的工具解决方案。核心元素是开源RL库RLlib和常用且完善的d SPACE汽车开发工具链之间的连接。通过利用相关的汽车仿真模型(ASM),可以实现向更高虚拟化级别(如Hi-L)的无缝转移,ASM通常用于整个V型模型的系列开发。此外,该框架提供了模拟场景和所有模型参数的连续变化,以及集成测试能力,以持续监控代理的性能,并证明其在不同条件下的稳健性。为了能够处理高训练需求,特别是在传感器模拟等计算成本高昂的任务中,我们将工具链转移到云中,以便分布式并行执行训练和测试。工具链的另一个优点是它在用例和RL算法方面都具有灵活性。要开发该功能的车辆可以配备不同的传感器、动力总成拓扑结构和软件功能。因此,表1中列出的所有用例都可能被覆盖。每个模拟的车辆组件在工厂和控制模型之间都有明确的分离,使RL代理能够轻松集成到接近真实软件结构的位置。RL代理和仿真之间的通用接口也为无模型RL算法的选择留下了灵活性。
2.1强化学习
RL是机器学习的三个主要范式之一,还有监督和无监督学习,它处理的是一个智能体与环境自由交互,以获得经验,这些经验后来用于优化智能体的策略。该范式的核心是将环境定义为时间离散马尔可夫决策过程(MDP),其中S是所有状态的集合,a是所有动作的集合,是转移概率函数,是奖励函数。代理的策略由具有可配置参数的操作分布来描述。体验是一种单一的互动,即主体观察到的状态、选择的行动、环境过渡到的后续状态以及给予的奖励
(1) 从开始状态到结束状态被称为事件。RL努力最大限度地提高累计折扣剧集奖励
(2) 折扣率在哪里。它通过修改策略参数来做到这一点,例如通过梯度上升[10]。
RL代理需要一个与之交互的环境,他们从中学习将输入映射到输出,从而表示控制功能本身。在真正的硬件上进行培训既费时又昂贵,而且在自动驾驶的情况下,这也是高度安全的关键。因此,RL代理在仿真模型中进行训练。
2.2.仿真环境
开发汽车应用的控制功能通常从定义需求和用例开始[41,42,43]。基于这些定义,必须推导或选择一个合适的模型来表示具有手头功能所需保真度的植物行为。保真度还取决于开发阶段,以及是测试单个功能还是集成多个功能。因此,需要一个灵活的模型基础来提供可变的复杂性水平,这使得控制功能可以很容易地集成,以加速开发过程。满足这些要求的测试环境如图1所示。它基于Eisenbarth等人的工作。[44],可以在从Mi L、软件在环(Si L)到Hi L、车辆在环(Vi L)的不同平台上使用,也可以在本地或基于云的环境中使用。
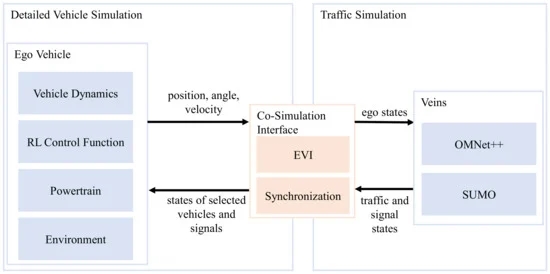
图1。仿真环境的体系结构,包括自我车辆模型、交通和通信仿真以及接口模型。
该测试环境的主要组件是左侧的详细车辆模拟、右侧的交通模拟以及耦合这两个领域的协同模拟接口。详细的车辆仿真基于ASM工具套件,代表了一个高保真的自我车辆和环境实时仿真模型。术语ego车辆用于开发控制功能的车辆。RL控制功能包括一个独立于用例的RL块和单独的、可选的预处理和后处理功能,如第2.3节所述。交通仿真基于Vehicles in Network simulation(Veins),利用SUMO来模拟道路网络中大量的低保真度车辆模型,而C++中的Objective Modular Network Testbed(OMNe T++)则模拟静态和动态对象之间的通信。协同模拟接口同步两个模拟,并接收ASM中模拟的自我车辆的状态,并返回相关交通对象,然后由模拟传感器感知。基于自我车辆周围圆形区域中的最小距离范数来选择相关交通对象,其中定义自我车辆周围的附加圆以选择用于车辆到一切(V2X)通信的相关节点。这两项任务都由自我车辆接口(EVI)处理[44]。
根据使用情况,模拟环境的相关部分可以单独用于功能开发或单元测试,并在集成不同功能时集成在更复杂的环境中。例如,控制发动机的RL代理可以仅使用单自我车辆的动力系模型来训练,而控制自动化车辆的RL代理需要车辆动力学和传感器的模型,以及可能涉及车辆到基础设施(V2I)通信的现实交通场景。本文中提供的模拟环境既可用于两个用例,其各个组件将在以下部分中进行描述。
2.2.1物理模拟
ASM工具套件是车辆动力学、动力总成、传感器和环境仿真模型的基础,也是控制车辆纵向或横向运动的软ECU的基础。这些组件基于开放的MATLAB/Simulink模型,通过总线接口连接,并在工厂和控制部分分离,具有直接连接外部控制算法的接口。因此,单个子系统可以用不同保真度级别的模型或在不同基础上实现的模型来代替,例如,功能实体单元(FMU)、机器人操作系统(ROS)或虚拟电子控制单元(VECU)。这种结构可以代表一辆装有柴油发动机的卡车和一辆电池电动汽车,在图1所示的测试环境中,这两种类型的车辆都可以用作电动汽车。模型的保真度可以很容易地调整。例如,可以用模拟缸内压力的模型来代替平均值发动机模型。对于更高级别的高级驾驶员辅助系统(ADAS)功能,可以使用线路、交通标志、声纳和雷达传感器,以及环境模型和电子地平线,其中包含高级驾驶员辅助设备接口规范(ADASIS)联盟[45]基于v2标准的地图信息。对于现实场景,自我车辆周围的交通参与者和基础设施由SUMO控制,如下节所述。
2.2.2微观交通模拟
交通流和通信模拟基于开源软件环境Veins 5.0,连接SUMO 1.13.0用于交通,OMNe T++5.6.2用于网络通信模拟。这使得能够模拟真实的交通场景,包括车辆之间以及车辆与基础设施之间的通信。例如,场景可以代表城市的高峰时间,并用于具有现实负载循环的动力系统功能开发,以及用于在密集交通中控制车辆的自动驾驶功能,而无需单独建模周围车辆的行为。SUMO模拟单个交通参与者通过给定道路网络的移动。交通需求可以是多模式的,每个参与者都有自己的路线,并遵守交通规则和交通灯。每个交通参与者也由OMNe T++中的一个节点表示,其中模拟通信,包括干扰效应和其他移动物体或建筑物的阴影。图2展示了ASM和SUMO的联合仿真。在左侧,ASM模拟通过Motion Desk进行可视化,可以看到蓝色的ego车辆。在SUMO图形用户界面(GUI)中,此车辆在右侧显示为黄色车辆。红绿灯的同步状态也在两个模拟工具中突出显示。
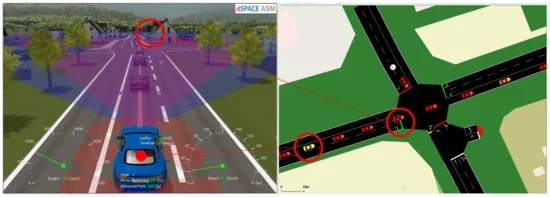
图2:带有ASM(左)和SUMO(右)的模拟环境。
2.3.分布式学习框架
如第2.1节所述,为了克服策略上数据生成和模型执行速度方面的挑战,开发了云设置和专有软件界面。云设置的基础是SIMPHERA[46],它提供了一个基于web的界面,用于参数化、并行模拟和分析单个场景。
专有软件接口基于主-从体系结构。图3展示了训练过程,该过程由主机以循环方式管理:在每个循环开始时,主机提取策略NN,并将其与训练和场景参数一起发送给从属节点,以协调用于模拟的逻辑场景。这会提示爪牙开始可配置数量为n的并行模拟,每个模拟的任务是完成一集,并等待它们完成。如果生成的体验在终止后数量不够(例如,如果模型进入灾难性状态,因此模拟无法继续),则爪牙开始额外的模拟。一旦收集到必要数量的数据,就会使用自定义协议通过TCP/IP将其发送回主机。随后,master与开源库RLlib[47]对接,并用minion生成的数据训练代理。更新代理后,循环再次开始。除了这些训练周期之外,所谓的验证周期在预定义数量的训练周期之后连续执行。这两种类型之间的区别在于,在验证过程中,只执行一个模拟,在这个模拟中,代理的行为不是根据随机采样的,而是只取策略的平均值。因此,实现了代理性能的更可比较的快照和控制功能的可再现行为。此外,可以定义关键性能指标(KPI)来评估验证运行期间控制功能的性能。一旦根据前面定义的要求对代理进行了充分的培训,这些KPI可用于停止培训过程。
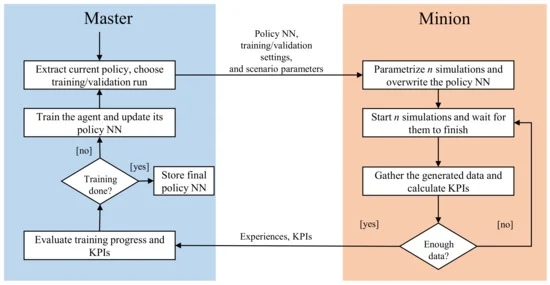
图3。拟议云框架中的培训周期。
上述培训过程由SIMPHERA协调,使用其智能测试控制接口执行模拟、计算KPI和收集结果。这个云设置如图4所示,以及左侧用于开发基于RL的控制功能的工作流。最初,定义了要控制的功能,并将RL块和可选的预处理和后处理功能集成到相应的控制功能模型中(参见图1)。接下来,通过选择工厂模型和场景的相关组件、定义KPI并说明培训设置(包括状态和行动空间的定义以及奖励函数)来配置培训。在完成这些手动步骤之后,所提出的框架开始自动生成控制功能,并且不需要进一步的人工干预。在进行图4所示的训练过程之前,SIMPHERA启动以这种方式配置的训练,在云环境中为master和minion启动并配置容器,其中单个容器用灰色背景突出显示。在训练过程中,SIMPHERA将工厂模型和控制功能的各个组件组合成一个联合应用程序,并使用由图1中的设置组成的n个模拟容器开始大规模执行该应用程序。这一步骤还包括逻辑场景的具体化,其中每个模拟实例接收不同的具体场景,从而允许宽带宽的情况。因此,还提高了代理的可推广性,使其在未知情况下获得更好的性能。控制功能的中心组件是RL块,它负责执行策略NN,存储经验并根据应用的RL算法对动作进行采样。对于每个周期,策略NN的权重和偏差被发送到爪牙。由于RL块使用Tensor Flow Light Micro[48],并且是用C++编写的,因此基于RL的控制函数可以很容易地编译用于实时原型硬件。RL块可以附带用于预处理观测值(例如,最小-最大归一化)或对动作进行后处理(例如,去归一化或安全过滤)的自定义模块,但也可以在学习端到端策略时独立执行。一集结束后,计算出的KPI和经验会被发送给仆从。因为这种模拟是基于容器化架构的,所以可以根据可用的云资源自由缩放。一旦主控根据定义的KPI确定了足够的训练进度,大规模模拟和智能测试控制就会关闭,并存储最终的策略NN和训练结果
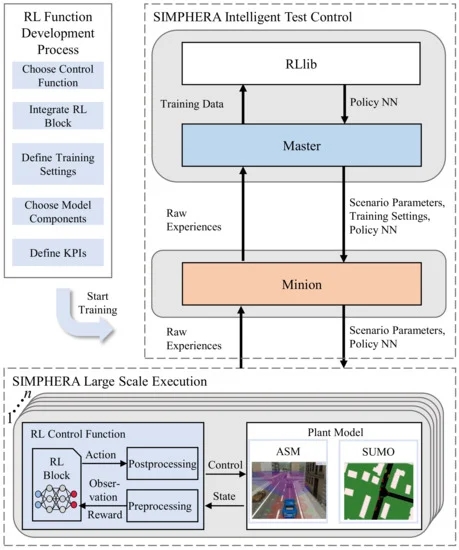
图4。RL功能开发框架的体系结构。灰色背景表示SIMPHERA环境中的各个容器。本示意图中的工厂模型显示了ASM和SUMO的耦合。
3.可行性研究
为了展示上一章介绍的框架的潜在应用,进行了一项示范性可行性研究。这里,用于自动化车辆的纵向控制器表示将使用RL和所提出的模拟工具链开发的控制功能。控制器的目标是在考虑不同安全方面的同时,生成平滑且节能的轨迹。
3.1.场景
为了训练和验证代理,选择了一条路线,在该路线上,在ASM中模拟的自我车辆与其他交通参与者和SUMO控制的交通灯进行交互。
3.1.1.路线
模拟环境基于德国中型城市帕德博恩的真实道路网络,如[49]所述,其中对交通量进行了校准,以匹配实际交通测量。路线上的所有交通灯都以90 s的周期切换,从红色到绿色的过渡处出现持续时间为3的黄灯阶段。在这种情况下,将选择一条代表典型市中心车道的路线,长度为。沿着路线,会出现不同的限速区(30、50和70/)和不同数量的车道(1-2)。此外,它还包括9个信号交叉口和18个无信号交叉口。整个路线都有优先通行权,所有左转交通灯都是专用的。具有所有功能的路线如图5所示。
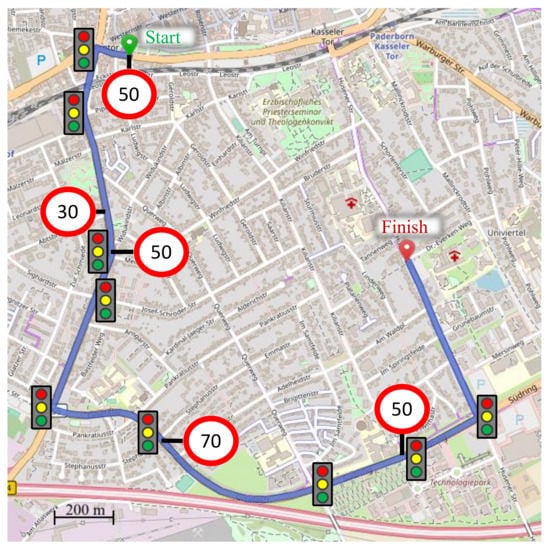
图5。具有信号交叉口和限速的Ego车辆路线[50]。
3.1.2.Ego车辆
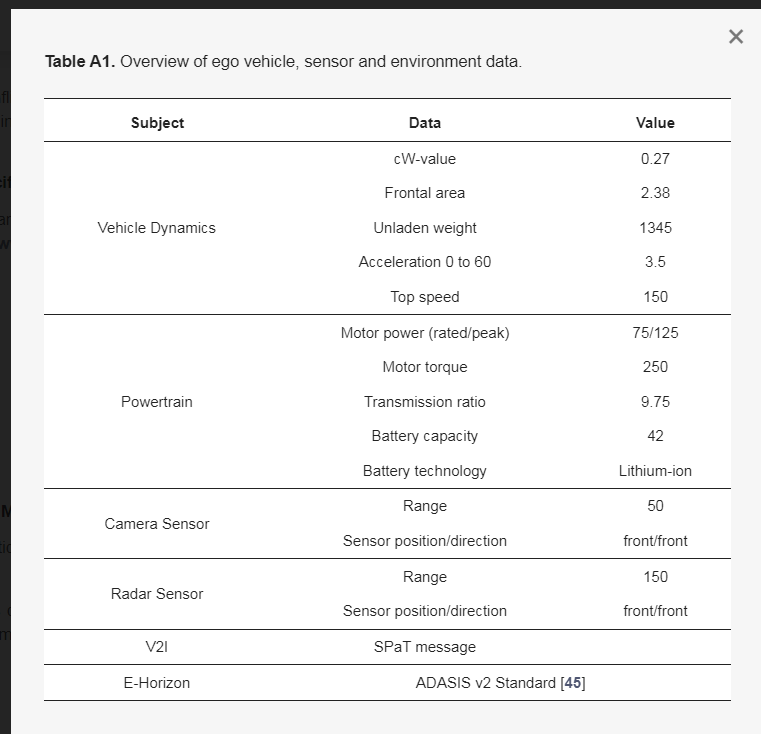
ASM套件被配置为将ego车辆建模为带有单个永磁同步电机的电动汽车。电机通过带有集成单级齿轮组的差速器连接到后轮。所有车辆和动力系统参数都经过校准,以匹配宝马i3车辆,并在表A1中列出。为了尽可能接近实际应用,ego车辆配备了各种非理想环境传感器。雷达传感器能够检测位于ego车辆前方150处的车辆,并提供多达15个物体的列表。每个物体都有类型的特征,其中包含物体是否是车辆及其速度以及相对于自我车辆的位置的信息。摄像头传感器提供ego车辆前方10–50距离处ego车道边界的位置。为此,获得车道每侧上5个等距点的位置。这两个传感器都位于车辆前部,并考虑掩蔽和噪音等影响。此外,ego车辆包含一个电子地平线,并通过V2I接收信号相位和定时(SPa T)消息。ego车辆的横向控制由传统的车道保持控制器执行。
3.1.3.RL控制功能
代表待开发系统的控制功能的任务是通过确定作为给定传感器信息的函数的目标扭矩来提供车辆的安全、有效的纵向引导。功能架构如图6所示,逻辑上可分为预处理、RL块和后处理三部分。通过融合算法对传感器数据进行预处理,该算法将摄像头的车道信息与雷达传感器的目标列表相匹配,以找到相关的目标车辆。此外,分别从电子地平线和V2I消息中提取关于即将到来的路段的道路曲率、速度限制、道路坡度和红绿灯状态的信息。然后,这些处理后的数据用于计算当前时间步长的状态信号s和奖励r(见第3.2节)。这两个量被输入RL块,在那里对它们进行采样,然后用于确定代理的动作,即自我车辆的期望加速度。

同时,安全功能通过计算安全加速请求来确保安全驾驶条件。在此,考虑以下安全标准:
碰撞:确保安全时间间隔(1)和与前车的距离(1)。
限速:保证遵守法定限速。
曲率:曲线速度受到限制,以确保不会超过3的横向加速度。
红绿灯:防止闯红灯。
对于每个项目,使用自我车辆的运动学模型来计算刚好满足相应标准的最大加速度。则等于这四个计算出的加速度值中的最小值。加速度请求由最小值形成,以防止代理进入安全关键驾驶状态,然后由下游PI控制器转换为目标扭矩。该目标转矩被反馈到模拟环境中,并影响车辆的运动以闭合控制回路。
3.2问题表述
代理与环境的接口的定义和合适的RL算法的选择是一个关键步骤,需要在基于RL的功能开发过程的早期阶段手动执行。状态空间(见表2)包含自我车辆的动态状态以及生成安全纵向轨迹所需的来自环境传感器的信息。红绿灯状态指示是否允许在当前车道上穿过红绿灯。结合下一次切换时间和距离,它能够生成预期的驾驶轨迹。定义了具有上限()和下限()的速度带,以引导代理在绿色阶段到达红绿灯。当检测到新的红绿灯时,通过在考虑前方速度限制的情况下基于距离和切换时间信息计算最早和最晚到达所需的速度来确定它们一次。速度上限和下限都只能在允许最大速度的70%到100%的范围内,以免与人类驾驶行为偏离太多。此外,来自安全功能的当前安全加速度用于提供关于当前驾驶状态的临界性的信息。状态信号被传递到RL块,在那里它们被用于提供加速度需求作为在的采样时间内的动作。根据表2中规定的范围,对所有状态变量进行最小-最大归一化。
表2。RL代理的状态和操作空间概述。
奖励函数由多个术语组成,以服务于不同的目标。如果期望加速度超过安全函数加速度极限,则奖励函数的第一项惩罚不安全的加速度请求。自我车辆速度与速度带上限和下限的偏差被考虑在内,以引导智能体朝着有效的速度轨迹前进并加速训练。批准自我车辆的加速可以确保平稳的运动。成功通过红绿灯交叉口会得到奖励,以鼓励最大限度地延长行驶距离。奖励函数的各个项使用因子、和进行加权。因此,完整的奖励函数定义为:
(3)
选择无模型的基于策略的RL算法进行可行性研究。尽管与最先进的非策略算法相比,PPO的策略上性质往往使算法的数据效率更低,但PPO在不同领域脱颖而出:首先,它的超参数数量相对较低;因此,训练过程很容易设置。其次,它是一个稳定的算法,因为它优化了代理目标函数,防止了巨大的更新步骤。[51]一个具有3层的全连接tanh激活前馈神经网络,每个层由16个节点组成,用作RL块内的策略网络。
3.3.结果
本节讨论了使用第2节中介绍的基于云的框架进行的可行性研究的结果。代理人的培训和验证均通过第3.1节中规定的途径执行。
3.3.1培训结果
ASM-SUMO联合模拟分布在10个并行计算事件的模拟节点上。每一集的模拟时间最长为600秒,相当于3000个样本。如果车辆提前到达终点位置,或者小黄人之一在训练期间坠毁,则开始新的训练,直到达到船长要求的样本数量。
图7实时显示了培训和验证过程,包括培训周期和培训持续时间。从训练事件中获得的所有数量都用黑色标记,而红点表示在每十个训练周期后执行的验证运行的结果,因此用点突出显示。上图包含每个周期10个训练集的最小、最大和平均累积奖励,以及验证集内的总奖励。平均奖励在第一个周期中相对强劲地增加,然后随着训练持续时间的推移而趋于平稳。它在大约280个循环后达到最大值,然后开始略有下降,直到310个循环后训练停止。这一趋势在验证事件中得到了复制,但由于行动采样的停用而产生了轻微偏差。此外,在训练过程中,最小和最大奖励之间的范围会减小,因为动作的方差会稳步减小,而代理会变得更有经验。这一点在图7中间的图中用递减熵表示。下图显示了平均速度作为训练期间监控的KPI示例。代理学习完成整个路由大约需要200个周期。通常,这些KPI可用于评估与预定义控制目标相关的培训进度。

计算310个周期总共花费了160个,大约一周。尽管模拟时间和开销略有变化,导致了一些较小的随机偏差,但训练时间与周期成正比。所有模拟实例的总执行时间为1212。训练、参数化、模型下载和结果上传以及验证运行约占总执行时间的25%,而75%的时间用于并行模拟。通过将模拟分布到10个节点,总训练因此加速了7.5倍,证明了分布式训练方法的有效性。必须考虑到,云系统的优化是为了最小化运营成本,而不是为了计算能力。增加计算能力并为并行模拟分配额外的节点可以进一步减少训练所需的时间。
3.3.2验证结果
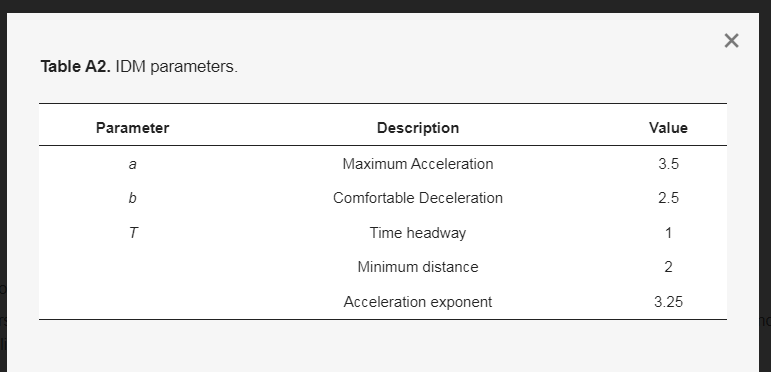
来自训练阶段的最佳性能代理的验证运行用于对进化策略的分析。选择基于智能驾驶员模型(IDM)[52](见附录B)的基于规则的控制函数作为参考,该函数的参数如表A2所示,并进行了修改,以考虑红绿灯和速度限制。为了进行公平的比较,使用相同的交通场景和初始条件,使用基于RL和基于IDM的控制器进行模拟。本章中评估的所有指标都涉及图5所示路线上的单个驱动器。
图8显示了基于RL和参考控制功能的速度曲线。红线表示法定速度限制和曲率速度限制的最小值。红绿灯的位置标记在x轴上。可以看出,代理根据给定的速度边界来操作车辆。然而,在没有安全功能干预的情况下,特工并没有完全完成路线。在红绿灯4和7处,仍需要进行少量干预,以调节前车后方的确切停车位置。在红绿灯3之前和红绿灯8之后,禁止超过法定限速两次。无需采取任何安全干预措施来调整转弯速度或防止闯红灯。对速度轨迹的比较表明,代理往往加速和减速较少,并达到较低的最大速度。虽然参考控制功能充分利用了速度边界,因此车辆被迫更频繁地制动,但基于RL的控制功能通常保持与速度限制的较大距离。这允许代理人在没有停车和随后的加速阶段的情况下通过前三个红绿灯,并且通常减少了为减速或减速前行车辆而制动的必要性。
图8。基于RL和参考控制功能的速度剖面。
图9中的s–t图显示了RL控制场景中雷达传感器感知到的两个控制功能相对于红绿灯和前车的自我车辆随时间的位置。当不存在灰线时,在传感器范围内未检测到前方车辆。这证明了代理处理有噪声的传感器数据的能力。代理人倾向于在前一辆车之间留下相对较大的间隙,但随后在下一个红绿灯时赶上。使用此策略,代理不仅可以避免在1-3号红绿灯处停车,还可以减少在其他红绿灯处的等待时间(4、6、9)。尽管静止阶段较少,但与基于IDM的控制器相比,基于RL的控制策略表现出平均37%的绝对加速度和更均匀的速度分布。这意味着需要从机械能到电化学能的损耗较小的能量转换,反之亦然。结合由降低的最大车速引起的降低的驱动阻力,车轮能量需求大大降低。总的来说,在几乎相同的行程时间(IDM:590,RL:602)下,能耗降低了14%,从16.2降低到每100。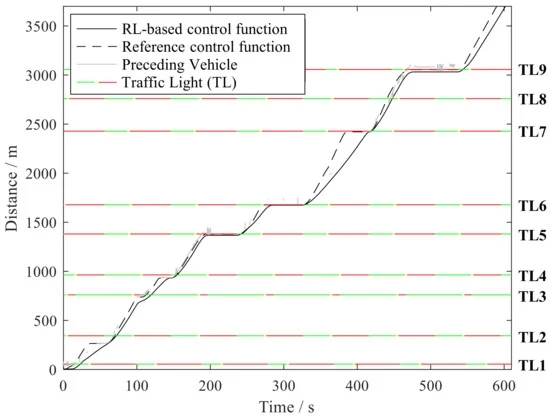
设置订购文章重印
开放访问文章
基于云的强化学习在汽车控制功能开发中的应用
由Lucas Koch 1、Dennis Roeser 2、Kevin Badalian 1、Alexander Lieb 1和Jakob Andert 1
1.
移动推进机电一体化教学研究区,亚琛工业大学52074,德国亚琛
2.
d SPACE Gmb H,Rathenaustraße 26,33102 Paderborn,德国
通信地址应为的作者。
车辆2023、5(3)、914-930;https://doi.org/10.3390/vehicles5030050
接收日期:2023年5月29日/修订日期:2023.7月18日/接受日期:2023:7月27日/发布日期:2023-8月2日
(本文属于《智能交通系统(ITS)的最新发展》特刊)
下载键盘向下箭头浏览图形版本说明
摘要
汽车控制功能变得越来越复杂,其开发也越来越精细,这导致在开发过程中强烈需要自动化解决方案。在这里,强化学习为功能开发提供了巨大的潜力,可以以自动化的方式生成优化的控制功能。尽管它成功地部署在各种控制任务中,但在汽车行业中仍然缺乏基于强化学习的功能开发标准工具解决方案。为了解决这一差距,我们提出了一个灵活的框架,将传统的开发过程与开源的强化学习库相结合。它具有相关车辆部件的模块化物理模型、与微观交通模拟的协同模拟以生成真实场景,并实现分布式和并行训练。我们在一项可行性研究中证明了我们提出的方法的有效性,该研究旨在学习城市交通场景中电动汽车自动纵向控制的控制函数。进化的控制策略产生了一个平滑的轨迹,节能高达14%。结果突出了强化学习在自动化控制功能开发中的巨大潜力,并证明了所提出的框架的有效性。
关键词:强化学习;自动化云模拟;功能开发;协同仿真
1.简介
近年来,汽车行业发生了重大变革,车辆从机械系统转向高度软件驱动的系统。如今,软件已成为汽车制造商最重要的因素[1],车辆中约80%的功能都是通过软件实现的[2]。现代生产车辆通常有100多个电子控制单元(ECU),具有数百万条代码线[3,4]。随着软件在车内和外部设备之间的互联程度越来越高,以及自动驾驶功能具有更广泛的功能和更严格的法规,这种已经很高的复杂性预计将呈指数级增长[1]。
随着汽车软件的复杂性不断增加,ECU内部的底层控制算法的重要性也在增加,ECU通过将传感器信息转换为执行器的控制命令来操作车辆的机电子系统。因此,控制功能最终负责车辆的安全和环保操作,并对整体性能产生重大影响。在V模型[5]规定的传统汽车软件开发过程中,控制功能开发发生在过程的早期阶段,通常涉及模型在环(Mi L)模拟。然后,将产生的控制功能转换为目标硬件的机器代码,并部署在ECU上,通常首先在硬件在环(Hi-L)环境中,随后开始微调控制参数的校准过程[6]。尽管开发过程的某些步骤,特别是代码生成和测试[7],是部分自动化的,但大多数功能开发和校准过程仍然高度依赖于人类专家。然而,这些任务的工作量不断增加,这主要是由于几个因素导致功能开发[1]的复杂性增加所致。对可持续交通的迫切需求以及相关的更严格的法规,如预期的欧7排放标准,正在提高性能要求[8]。此外,ECU传感器和执行器的数量不断增加,不仅导致需要实现额外的功能,而且由于彼此之间的复杂交互,其开发也变得更加困难。与此同时,车辆变体的数量以及对特定、单独软件的需求正在增加[9]。最后,由于传感器信息和
作者贡献
概念化,L.K。;方法论,L.K.、D.R.和K.B。;软件,L.K.、D.R.、K.B.和A.L。;验证,L.K.、D.R.、K.B.和A.L。;形式分析。;调查,L.K。;资源、D.R.和J.A。;数据管理,L.K.、D.R.和K.B。;书写——原始草稿准备,L.K.、D.R.、K.B.和A.L。;写作——评论与编辑,J.A。;可视化,L.K.、D.R.、K.B.和A.L。;监督,J.A。;项目管理,J.A。;资金收购,J.A.所有作者都已阅读并同意手稿的出版版本。
基金
本文报道的研究是在欧洲区域发展基金(ERDF)支持的Hy-Nets4all项目(批准号:EFRE-0801698)的背景下进行的。此外,这项工作的一部分是在德国研究基金会和德国科学与人文委员会资助的移动推进中心进行的。
数据可用性声明
不适用。
利益冲突
提交人声明没有利益冲突。资助者在研究的设计中没有任何作用;收集、分析或解释数据;在手稿的书写中;或者决定公布结果。
附录A.Ego车辆规范
表A1规定了用于第3节可行性研究的ego车辆的参数。车辆动力学和动力系统已校准为宝马i3(https://www.press.bmwgroup.com/global/article/attachment/T0284828EN/415571(2023年5月28日访问))车辆。
附录B.智能驾驶员模型
IDM[52]是一个数学模型,其目标是用一个相对简单的方程来反映人类的驾驶风格:
(A1)
所需加速度是根据相对速度和与前一辆车或下一个红灯的d计算的,具体取决于哪一个更近。在速度项的分母中引入,以实现遵守法定速度限制。IDM的参数如表A2所示。
参考文献
Ebert,C。;Favaro,J.汽车软件。IEEE软件。2017年,34,33–39。[谷歌学者][交叉参考]
Vogel,M。;Knapik,P。;Cohrs,M。;Szyperek,B。;Pueschel,W。;Etzel,H。;Fiebig,D。;Rausch,A。;Kuhrmann,M.汽车软件开发中的度量:系统文献综述。J.软。Evol。流程2021,33,e2296。[谷歌学者][交叉参考]
Antinyan,V.揭示汽车软件的复杂性。在第28届ACM欧洲软件工程联席会议论文集和软件工程基础研讨会上,虚拟,2020年11月8日至13日;1525-1528页。[谷歌学者]
Greengard,S.汽车系统变得更智能。Commun。ACM 2015,58,18-20。[谷歌学者][交叉参考]
Möhringer,S.Entwicklungsmethodik für机电系统;Heinz Nixdorf研究所:帕德博恩,德国,2004年。[谷歌学者]
汽车控制:车辆建模与控制;施普林格:柏林/海德堡,德国,2022年。[谷歌学者]
Juhnke,K。;Tichy,M。;Houdek,F.关于汽车软件测试中测试用例规范的挑战:频率和关键性的评估。柔和。Qual。J.2021,29,39–100。[谷歌学者][交叉参考]
Claßen,J。;Pischinger,S。;Krysmon,S。;Sterlepper,S。;Dorscheidt,F。;Doucet,M。;Reuber,C。;Görgen,M。;Scharf,J。;Nijs,M。;等。统计支持的实际驾驶排放校准:使用循环生成为欧7提供车辆特定和具有统计代表性的测试场景。《国际发动机研究杂志》,2020,21783-1799。[谷歌学者][交叉参考]
Mattos,D.I。;Bosch,J。;奥尔森,H。;Korshani,A.M。;Lantz,J.汽车A/B测试:实践中的挑战和经验教训。2020年8月26日至28日,在斯洛文尼亚波托罗兹举行的2020年第46届欧洲微软件工程与高级应用会议(SEAA)上;第101–109页。[谷歌学者]
Sutton,R.S。;Barto,A.G.强化学习:导论,第2版。;麻省理工学院出版社:2018年,美国马萨诸塞州剑桥。[谷歌学者]
曹。;徐,S。;彭H。;杨博士。;Zidek,R.自动驾驶汽车的自信强化学习。IEEE Trans。Intell。Transp。系统。2021年,237419–7430。[谷歌学者][交叉参考]
Gutiérrez Moreno,R。;Barea,R。;洛佩斯·吉伦,E。;Araluce,J。;Bergasa,L.M.CARLA模拟器中基于强化学习的十字路口自动驾驶。传感器2022、22、8373。[谷歌学者][交叉参考]
李博士。;Okhrin,O.使用CARLA模拟器,用真实世界的人类驾驶体验修改了DDPG跟车模型。Transp。Res.Part C Emerg。Technol。2023147103987。[谷歌学者][交叉参考]
曹。;Bıyık,E。;王。;拉文托斯A。;Gaidon,A。;罗斯曼G。;Sadigh,D.基于强化学习的准事故驾驶模仿策略控制。ar Xiv 2020,ar Xiv:2007.00178。[谷歌学者]
李。;杨。;李,S。;屈,X。;Lyu,N。;李,S.E.自动驾驶汽车在变道场景中的决策:具有风险意识的深度强化学习方法。Transp。Res.Part C Emerg。Technol。2022年,134103452。[谷歌学者][交叉参考]
张,Y。;郭。;高,B。;屈。;陈,H.确定性提升强化学习在自动化车辆纵向速度控制中的应用。IEEE Trans。车辆。Technol。2019年,69338–348。[谷歌学者][交叉参考]
田。;曹,X。;黄,K。;费。;郑。;纪,X.学习像人一样开车:一种基于深度强化学习的方法。IEEE Trans。Intell。Transp。系统。2021年,236357–6367。[谷歌学者][交叉参考]
宋。;陈H。;孙,H。;刘,M.用于自动停车系统中集成横向规划和控制的数据高效强化学习。传感器20207297。[谷歌学者][交叉参考]
赵J。;程,S。;李。;李,M。;张,Z.一种基于强化学习的不确定主动转向系统无模型控制器。Proc。Inst.Mech。工程师D J.汽车。Eng.2021,235,2470–2483。[谷歌学者][交叉参考]
邓H。;赵。;Nguyen,A.T。;Huang,C.基于深度强化学习的四轮电机驱动电动汽车转矩分配容错预测控制。IEEE/ASME Trans。机械加速器。2023年,28668–680。[谷歌学者][交叉参考]
Fuchs,F。;宋。;考夫曼E。;Scaramuzza,D。;Dürr,P.使用深度强化学习在gran turismo运动中的超人类表现。IEEE机器人。Autom。Lett。2021年,64257–4264。[谷歌学者][交叉参考]
Wurman,P.R。;Barrett,S。;Kawamoto,K。;Mac Glashan,J。;Subramanian,K。;沃尔什,T.J。;Capobianco,R。;Devlic,A。;Eckert,F。;Fuchs,F。;等。具有深度强化学习的越野冠军Gran Turismo车手。《自然》2022,602,223–228。[谷歌学者][交叉参考]
Min,K。;Kim,H。;哈,K.基于深度分布强化学习的高层驾驶决策。IEEE Trans。Intell。车辆。2019年,416–424。[谷歌学者][交叉参考]
白。;郝。;

![[OpenVI-视觉生产系列之视频稳像实战篇]再见吧云台,使用AI“魔法”让视频稳定起来](https://ucc.alicdn.com/pic/developer-ecology/hv5y3lsfkkv2q_1021493a694443cc9d25b257f8903583.png?x-oss-process=image/resize,h_160,m_lfit)