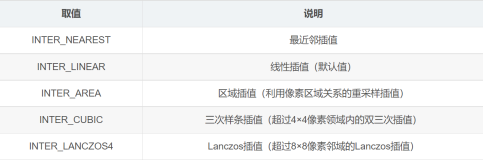
今天才发现上采样还有个这样的方法,之前一直没注意过。
原理很好理解,但是不太明白为什么效果会好,所以去翻论文撸一遍。
翻译了一部分,没有翻译完。
可能是我自己阅读理解的问题,感觉论文里面的filter和feature map有点混淆,然后介绍原理的地方读起来别别扭扭的【怪我英语底子不好
个人感觉相比于看整篇论文,还是看别人总结的原理更容易理解-
使用亚卷积神经网络实时图片和视频超分辨率
Abstract
在图像超分辨率算法上,很多基于深度神经网络的模型都取得了成功,不管是在准确率还是表现上效果都不错。这些方法中,一个低分辨率的输入图像通过使用一个fileter(通常是双三次插值方法)被放大到高分辨率空间。我们认为这种做法是个次优解,并且增加了计算复杂度。在这篇论文中,我们提出了第一个可以在K2 GPU上对1080p视频进行实时处理的卷积神经网络。为了实现该网络,我们提出了一个新的CNN结构,它的特征图在低分辨率空间上提取,我们引入了亚卷积层,它可以一组filter来完成低分辨率特征途到高分辨率输出的放大。通过这样做,我们有效地用一个更复杂的需要对每个特征途训练的放大filters取代了手动的双三次filters,同时也减少了整个超分辨率操作的计算复杂度。我们使用公开数据集中的图像和视频来验证我们的方法,发现它的表现明显更好并且比之前的基于CNN的方法更快。
Introduction
在电子图像处理领域,从低分辨率图像或视频中恢复高分辨率图像视频是一个很受关注的主题。这个任务,又被称为超分辨率(SR),在很多领域都有应用,比如HDTV,医疗图像等。超分辨率问题假设低分辨率图像是高分辨率图像的噪声、模糊、下采样版本。这是一个不适定的问题,由于高频信息的损失通常是不可逆的。此外,超分辨率操作是一个一对多的映射,从低分辨率到高分辨率空间可能有很多的解,而你并不能确定哪一个是正确的解。一个关键假设是高频信息是冗余的,所以能从低频信息中准确的恢复重建。超分辨率因此也变成一个推理的问题,因此依赖我们对问题中图像的统计的模型。(relies on our model of the statistics of images in question 有点翻译不通顺)
很多方法认为同一场景的低照度样例有不同的角度,所以能获得不同的图像。这被归类为多图像超分辨率模型并且通过使用额外信息和逆转下采样过程来约束不适定问题从而利用冗余信息。然而,这些方法经常需要进行负责的图像配准和融合过程,并且这个过程的准确率会直接影响结果的质量。一个替代方法是单一图像超分辨率(SISR)。这些方法致力于寻找自然数据中的隐性冗余来恢复丢失的高分辨率信息。这通常以图像的局部空间相关性和视频的附加时间相关性的形式出现。在这种情况下,需要重构约束形式的先验信息来约束重构的解空间。
Method
SISR任务是去给定一个从高分辨率图像中用缩小手段获得的低分辨率图像,来预测高分辨率图像的过程。下采样的过程是固定的:首先使用高斯滤波对高分辨率图像进行卷积,然后根据因子r进行下采样。我们把r作为放大比率。通常情况下,低分辨率图像和高分辨率图像有着相同的颜色通道数,因此它们都分别可以表示为HxWxC和rHxrWxC。
为了解决SISR问题,SRCNN被提出来从一个插值版本的放大的低分辨率图像中复原高分辨率图像,而不是单纯的低分辨率图像。为了复原超分辨率图像,一个三层的卷积神经网络被使用。在这个部分,我们提出了一个全新的神经网络结构,来防止在把低分辨率图像送入神经网络之前对它进行的放大操作。在我们的结构中,我们首先应用了一个l层卷积神经网络,然后应用了亚卷积层来对它的特征图进行放大,从而产生超分辨率的图像。
对一个L层组成的网络,前L-1层可以表示为:
$$ f^1(I^{LR};W_1,b_1)=\phi(W_1*I^{LR}+b_1)\\ f^l(I^{LR};W_{1:l},b_{1:l})=\phi(W_l*f^{l-1}(I^{LR})+b_l)\\ $$
其中W,b分别代表了权重和偏置。非线性函数 $\phi$在每个像素上应用并且是固定的。最后一层的fL可以把低分辨率特征图映射为高分辨率图像。
Deconvolution layer
一个反卷积层也是一个回复高分辨率的常用选择。这个方法使用高层特征生成语义分割时有着不错的效果。用在SRCNN中的双三次插值只是反卷积的一个特例。反卷积层可以被看作每个输入像素和一个在每个像素上运算的filter的乘积,并在输出上求和。
Efficient sub-pixel convolution layer
另一个放大低分辨率图像的方法是使用步长为1/r的分数步长,可以通过在低分辨率空间上插值、穿孔或者反池化进行。这些方法带来了r的平方倍的计算损失。因为后续的卷积操作是在高分辨率空间进行的。
一个在低分辨率空间的步长为1/r的卷积将会激活filter的不同部分。落在像素之间的权重不需要激活和计算。激活模式的数量是r的平方。每个激活模式,相对它的位置,都有[k/r]的平方个权重激活。在卷积核从图像上走过的时候,根据子像素的位置,这种模式是阶段性的激活的。在这篇论文中我们提出了一个高效的方法来实现上面的操作。
$$ I_{SR}=f^L(I^{LR})=PS(W_L*f^{L-1}(I^(LR)+b_L) $$
PS是阶段性洗牌操作,可以对HxWxC*r的平方大小的tensor进行重排,使它变成rHxrWxC。这个才做可以被表示为:
$$ PS(T)_{x,y,c}=T_{[x/r],[y/r],C*r*mod(y,r)+C*mod(x,r)+c} $$
这个卷积操作WL的大小是n(L-1)xr的平方CxkLxkL。注意我们并不对卷积的输出作非线性操作。我们把我们的新层命名为亚卷积层,我们的神经网络是高效的亚卷积神经网络(ESPCN)。最后一层生成了一个高分辨率图像。
给定一个包含高分辨率图像的训练集,我们生成对应的低分辨率图像并且计算重构后每像素的均方差(MSE)作为目标函数。
$$ l(W_{1:L},b_{1:L})=\frac{1}{r^2HW}\sum^{rH}_{x=1}\sum^{rW}_{x=1}(I^{HR}_{x,y}-f^L_{x,y}(I^{LR}))^2 $$
很明显阶段性洗牌这个操作在训练过程是可以比变得。与其把对输出的洗牌作为这一层的一部分,我们能在训练数据上预先进行洗牌来匹配PS操作前的层的输出。这样我们的训练时间会大大缩短。
Experiments
对实验的细节报告包括了我们使用的原属数据、下采样数据、超解析数据、整体喝单一分数、在K2 GPU上的运行时间等。
Datasets
在验证阶段,我们使用了公开的数据集包括SISR类论文常用的数据集Timofte,它提供了一些方法的代码、91个训练图像喝两个测试数据集set5和set14。还有berkeley分割数据集BSD300和BSD500,分别提供了测试的100张图片和200张图片,同时也提供了136张纹理图片。对于最终的模型,我们使用了50000个从ImageNet中随机选择出来的图片,像之前的工作一样,我们只考虑YCbCr图像空间的亮度通道,因为人们对亮度的变化更敏感,对于每一个放大因子,我们都训练一个特定的网络。
对于视频试验,我们使用来自公共数据集Xiph的1080P高清视频,它在之前一些论文方法中都被使用过。这个数据集包含了一下8HD视频片段,长度大概10秒,宽高分别是1920和1080。此外,我们也使用了Ultra Video Group数据集,包含7个大小为1920x1080的视频,每个长度大概5秒。
Implementation details
对于ESPCN,我们设置l=3,(f1,n1)=(5,64),(f2,n2)=(3,32)和f3=3。这个参数的选择受到SRCNN的三层9-5-5模型的启发。在训练阶段,17r x 17r像素的子图被从高分辨率训练图片中截取处理,r是放大因子。为了生成低分辨率图像,我们使用高斯滤波器对图像进行模糊处理,并且按照放大因子进行下采样。子图像按照步长
$$ 17-\sum mode(f,2)\times r $$
从高分辨率图像中获取,并按照步长
$$ 17-\sum mode(f,2) $$
从低分辨率图像中获取对应的子图像。这也保证了原始图像的所有像素都能够出现一次且只有一次。我们选择tanh激活函数而不是relu。
在100个epochs之后,损失函数没有提升,于是我们把训练停止。初始的学习率设置为0.01,最终的学习率是0.0001并且在损失比设置的阈值好时逐渐更新。在K2 GPU上训练时间用了大约3个小时,使用ImagesNet的数据并将放大因子设置为3,用了七天时间训练。我们使用PSNR作为表现矩阵来衡量模型。
Image super-resolution results
在这部分,我们描述了我们的亚卷积层和使用tanh做激活函数的优点。我们首先和SRCNN标准9-1-5模型作比较来衡量我们的亚卷积层。我们先使用relu作为激活函数,并且分别在91张图片和imagenet数据集的图片上。ESPCN模型取得了明显比SRCNN模型好的表现。ESPCN(91)表现的和SRCNN(91)很相似,图像多的时候,ESPCN的效果明显更好。
为了在我们的亚卷积网络和SRCNN之间做一个直观的比较,我们画出了ESPCN(ImageNet)和SRCNN 9-5-5的权重,我们的第一层和最后一层的滤波器有着强相似性,相对设计好的比如log-Gabor滤波-小波和Haar特征等。很明显尽管每个滤波器在低分辨率空间是独立的,在高分辨率空间经过PS后这些独立的滤波器都变得平滑了。相对于SRCNN最后一层的滤波器,我们的最终层滤波器有着复杂的模型,它也有着更丰富的更有意义的表达。
我们也测验了tanh激活函数在以上模型的影响。tanh激活函数在SISR任务中表现比relu要好。