参考教程:
https://arxiv.org/pdf/2012.12877.pdf
https://github.com/facebookresearch/deit
概述
在之前的章节中提到过,VIT模型训练的一个问题是对数据的要求比较高,因为基于transformer的模型相对于基于卷积的模型,更加flexible。卷积的模型有着预设好的感受野,而transformer的模型需要自己去学习哪部分更加重要,因此训练上也更困难。
在这种情况下,想独自训练一个效果比较好的transformer模型是很困难的,你很难准备大几百万的数据集用于训练。这也给论文复现带来了难度,你看别人的模型效果好,你想去学习,但是没有资源训练出相当的模型。
DEIT提出了一种基于token的蒸馏方法,使用和训练卷积网络差不多的时间,只用imagenet作为训练集,就实现了非常不错的效果。
总的来说,DEIT做出了以下贡献(这一段直接翻译的论文原文):
- 证明了不包含卷积层的网络在只是用ImageNet数据的情况下也能取得很有竞争力的表现。
- 提出了一种基于token的蒸馏方法,并且这个方法的效果明显超过了普通的蒸馏方法。
- 有趣的是,基于transformer的模型以convnet为老师时表现的比以transformer为老师时要好。
- 他们的基于imagenet预训练的模型应用于其它下游任务时效果也很不错。
Knowledge Distillation
在这里补充一点知识蒸馏相关的内容。
知识蒸馏简单来说呢,就是把我们想要训练的模型当作“学生”模型,在向我们的hard label,也就是ground truth的结果靠近的同时,也让它向一个“老师”模型(一般是一个效果更好的、体量更大的模型)输出的soft label靠近。
比较简单的方法就是直接让学生模型的输出logits去拟合老师模型的输出logits,复杂一点的会增加层与层之间的拟合。
下面的代码就来自一个比较早期的repohttps://github.com/haitongli/knowledge-distillation-pytorch/tree/master
可以看到KD_loss明显有两部分组成。
T = params.temperature
KD_loss = nn.KLDivLoss()(F.log_softmax(outputs/T, dim=1),
F.softmax(teacher_outputs/T, dim=1)) * (alpha * T * T) + F.cross_entropy(outputs, labels) * (1. - alpha)
第一个部分就是我们的软目标损失,使用KLD散度计算输出的logits与老师模型输出的logits的差距,T在这里是一个温度系数,T越大得到的概率分布就越平滑。第二个部分就是我们的硬目标损失,也就是输出与label的交叉熵损失。
DEIT
base model: VIT
首先来重新介绍一下DEIT方法中使用的模型框架,其实也就是复习了一遍VIT。
transformer block
DEIT的工作是在VIT模型的基础上完成的。使用固定大小的RGB图像作为输入,这个图像被拆解成N个大小为16*16的小patch,N的大小一般是14*14。也就是说默认图像的大小是224*224。
每个patch都会被处理成一个指定维度的token。在之前的章节中我们介绍过这里有两个常用做法,再次复述一下。
第一种做法是使用reshape之后,使用全连接层完成维度的变化。
self.proj = Rearrange('b c (h p) (w p ) -> b (h w) (p1 p2 c)', p = patch_size)
self.linear = nn.Linear(patch_size * patch_size * in_c, embed_dim)
第二种做法是直接使用卷积。
self.proj = nn.Conv2d(in_c, embed_dim, kernel_size = patch_size, stride=patch_size)
目前来说第二种方法是更常用的。
然后再给得到的embedding加上一个class_token和一个position_embeddings。就构成了一个完整的输入。
class token
VIT中模仿BERT的做法,在得到的patch embedding上concat了一个可训练的class token。这个class token也会贯穿整个网络,并且最终用于分类。它相当于起到了串联所有patch_embedding的作用,它包含的也是一个整体的信息。
也就是说在整个过程中,transformer一共使用了N+1个token,但是只有第一个class token被用来进行结果的预测。
position embedding
已知transformer中最重要的结构就是MSA,在MSA中会根据你的输入计算三个vector,分别是Query, Key, Value。并使用Q和K的内积计算attention。
我们直接看一下源码,可以看到这个qkv是通过全连接得到的,它完成的是从embed_dim到embed_dim的映射,这个过程是和embed的数量无关的。
self.qkv = nn.Linear(emb_size, emb_size*3)
所以一个在low-resolution的图像上训练的模型,也是很容易用在high-resolution的图像上的。只要使用一样的patch_size就可以。
这时候聪明的你可能会发现一个问题,patch_size大小一样,在high-resolution图像上得到的patch的数量肯定比low-resolution要多呀。那么position_embedding是会受到影响的,position_embedding的大小是和我们的数量以及embed_size都有关系的。
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
原VIT论文中的做法是这样的
We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image.
Distillation through attention
作者在论文中对蒸馏的部分进行了比较详细的介绍。
soft distillation
软蒸馏就是上面介绍的,用学生模型的logits向老师模型的logits学习,两者的差距使用KL散度来衡量。
hard distillation
硬蒸馏是将老师模型预测的结果也作为真实的标签,让你的学生模型也去学习这个标签。
$$ L^{hardDistill}_{global} = (1-\epsilon)\times\frac{1}{2}L_{CE}(\psi(Z_s),y) + \epsilon\times\frac{1}{2}L_{CE}(\psi(Z_s),yt) $$
这种实现方法也更简单方便。老师模型预测的label和ground truth的label扮演一样的角色。
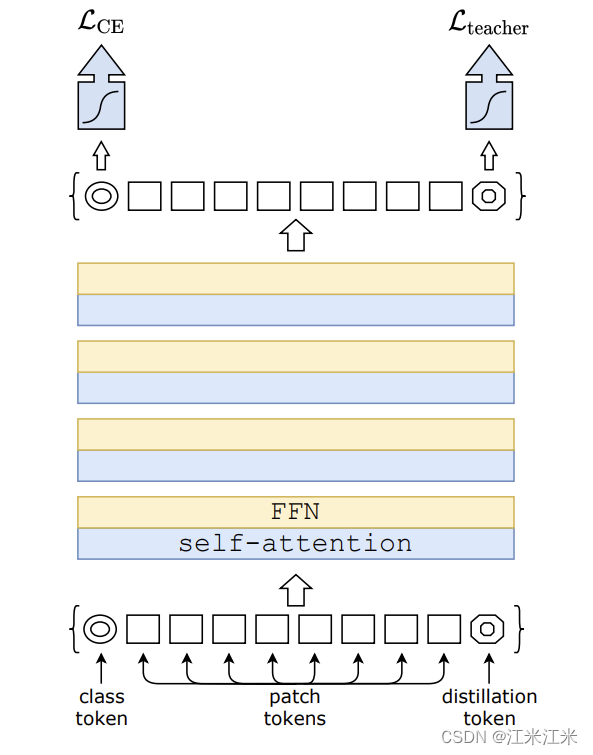
Distillation token
上图介绍了DEIT是如何进行token的蒸馏的。它们在原有的patch embedding的基础上(patch and class token)新增了一个额外的token,称为distillation token。
distillation token和class token一样,在整个训练过程中和别的token进行交互,并在最后一层输出。
class_token的分类结果向ground_truth靠齐,distillation_token的分类结果向我们的teacher靠齐。
整体的原理还是很简单的,可以看作class_token和distillation_token各学各的,在最后测试的时候,两个token是合在一起使用的。
代码实现
DistilledVisionTransformer
参考的是这里的源码:https://github.com/facebookresearch/deit/blob/main/models.py
我们首先来看一下这个DEIT的类。
class DistilledVisionTransformer(VisionTransformer):
它是直接继承的VisionTransformer的类,并在此基础上进行了一些修改,这个修改也没有很大,比较好理解。
init()
首先,它增加了一个dist_token,这个token和class_token的大小是完全一样的,用一样的代码就可以定义。
self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if class_token else None
然后它的position_embedding和之前不一样了。在不使用蒸馏的时候position_embedding的长度 = num_patch + 1 (class_token)。现在增加了一个新token,所以它的长度也增加了1,变成了num_patch + 2。
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 2, self.embed_dim))
此外,除了原有的分类头外,现在增加了一个新的蒸馏头,用来预测distillation_token的结果。这个部分代码和之前的分类头也是一样的。
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if self.num_classes > 0 else nn.Identity()
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
forward()
在模型的forward中,之前只有一个输出,现在变成了两个。整体的流程是没有什么变化的。
在之前的章节中我们梳理过VIT的流程。
- 输入img,获得patch,并转成embedding的形式。
- 增加cls embedding和position embedding。
- 进入transformer encoder构成的blocks。每个block由两部分组成:
- multi-head attention
- mlp
- 进入mlp分类头,输出结果。
在DEIT中增加了distillation_token,所以流程变为了:
- 输入img,获得patch,并转成embedding的形式。
- 增加cls embedding和dist embedding和position embedding。
- 进入transformer encoder构成的blocks。
- cls token进入mlp分类头,dist token进入另一个分类头。
第二点主要是输入的维度发生了变化,对整个训练流程是没有影响的。最后一点也不过是分开了两个输出。
embedding
在原版VIT中。
if self.cls_token is not None:
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1)
x = x + self.pos_embed
在DIET中。
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_token, x), dim=1)
logits
在原版VIT中。
def forward_head(self, x, pre_logits: bool = False):
# 这里的x是self.forward_features的结果。
if self.global_pool:
x = x[:, self.num_prefix_tokens:].mean(dim=1) if self.global_pool == 'avg' else x[:, 0]
x = self.fc_norm(x)
return x if pre_logits else self.head(x)
在DEIT中。
如果是训练中使用,两个结果分开输出,因为要分别计算loss。如果是在inference中,则使用两个输出融合的结果。
def forward(self, x):
x, x_dist = self.forward_features(x)
x = self.head(x)
x_dist = self.head_dist(x_dist)
if self.training:
return x, x_dist
else:
# during inference, return the average of both classifier predictions
return (x + x_dist) / 2
distillation loss
除了模型代码的改动外,DEIT中使用的loss也和之前不一样。
我们先来看一下loss的这个类。
init()
class DistillationLoss(torch.nn.Module):
"""
This module wraps a standard criterion and adds an extra knowledge distillation loss by
taking a teacher model prediction and using it as additional supervision.
"""
def __init__(self, base_criterion: torch.nn.Module, teacher_model: torch.nn.Module,
distillation_type: str, alpha: float, tau: float):
super().__init__()
self.base_criterion = base_criterion
self.teacher_model = teacher_model
assert distillation_type in ['none', 'soft', 'hard']
self.distillation_type = distillation_type
self.alpha = alpha
self.tau = tau
这里传入的base_criterion是你打算用来计算你的分类损失的loss,也就是你的class_head预测的结果和你的图像类别的ground_truth的loss。
if mixup_active:
# smoothing is handled with mixup label transform
criterion = SoftTargetCrossEntropy()
elif args.smoothing:
criterion = LabelSmoothingCrossEntropy(smoothing=args.smoothing)
else:
criterion = torch.nn.CrossEntropyLoss()
if args.bce_loss:
criterion = torch.nn.BCEWithLogitsLoss()
第二个参数teacher model是你想要学习的老师模型,因为我们只用这个模型做预测,不用它参与训练,所以要注意使用
teacher_model.eval()
第三个参数distillation_type是让你选择你先用软标签还是硬标签的方法。
第四个参数alpha用于分类损失和蒸馏损失的权重分配。
第四个参数tau就是温度系数,在软标签才会用到。
forward()
def forward(self, inputs, outputs, labels)
损失函数forward的部分的输入有三个,第一个input是我们的原始输入,它会被送入teacher_model中用于计算teacher_model的输出。第二个outputs是我们的学生模型的输出结果,它实际上包括了output(head的输出)和output_kd(dist_head)的输出。第三个labels就是我们的ground truth。
我们的分类损失直接用self.base_criterion进行计算。
base_loss = self.base_criterion(outputs, labels)
蒸馏损失按照你选择的distillation_type可以分为两类:soft和hard。其实还有一个选项是None,这种情况下不使用蒸馏损失。
teacher_outputs = self.teacher_model(inputs)
假如你使用软损失。那么就是用你的dist_head的logits和teacher_model的logits进行比较。在计算中还是使用KL散度。并且这里还会用到我们的温度系数tau。
T = self.tau
distillation_loss = F.kl_div(F.log_softmax(outputs_kd/T,dim=1), F.log_softmax(teacher_outputs/T, dim=1),reduction='sum',log_target=True)*(T*T)/outputs_kd.numel()
# We provide the teacher's targets in log probability because we use log_target=True
假如你使用的是硬损失。那么就是用你的dist_head的logits和teacher_model输出的标签进行比较。
distillation_loss = F.cross_entropy(outputs_kd, teacher_outputs.argmax(dim=1))
最终输出的loss用alpha这个参数平衡了权重。
loss = base_loss * (1 - self.alpha) + distillation_loss * self.alpha
