大家好,我是欧K~
本期我们通过分析利用Python分析上海市餐饮数据,看看:
- 哪个区的餐饮店铺分布最多
- 各类餐饮口碑评价怎么样
- 各类餐饮的人均消费大概定价多少
- 各区都适合开哪些类型的店铺
- ...
希望对小伙伴们有所帮助,如有疑问或者需要改进的地方可以私信小编。
涉及到的库:
- Pandas — 数据处理
- Pyecharts — 数据可视化
- matplotlib — 数据可视化
可视化部分:
- 饼图 — Pie
- 柱状图 — Bar
- 地图 — Map
- 组合组件 — Grid
1. 导入模块
import numpy as np import pandas as pd from collections import Counter from pyecharts.charts import Pie from pyecharts.charts import Bar from pyecharts.charts import Grid from pyecharts.charts import Page from pyecharts.charts import Map from pyecharts import options as opts from pyecharts.commons.utils import JsCode import matplotlib.pyplot as plt from mpl_toolkits.axes_grid1.inset_locator import inset_axes plt.rcParams['font.sans-serif'] = ['SimHei']
2. Pandas数据处理
2.1 读取数据
df = pd.read_csv('上海餐饮数据.csv') df.head()
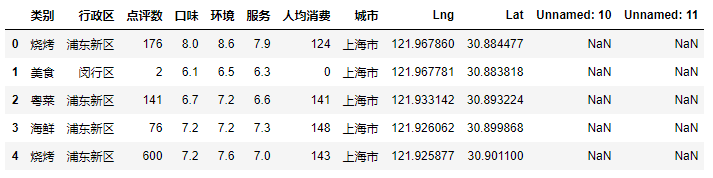
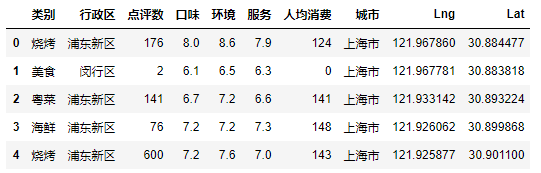
2.2 去除最后两行无用的列
df = df.iloc[:,:-2] df.head()
2.3 查看索引、数据类型和内存信息
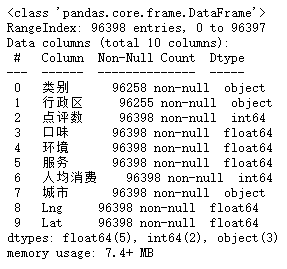
一共 96398 条信息,其中类别和行政区这两个字段有数据缺失。2.4 清除空值
df.isnull().sum() df = df.dropna()
2.5 行政区替换
卢湾区目前已经划入黄浦区,所以将行政区列中的卢湾区替换成黄浦区:
df['行政区'] = df['行政区'].str.strip() df['行政区'] = df['行政区'].replace('卢湾区','黄浦区')
3. Pyecharts数据可视化
3.1 上海各类餐饮店数量分布玫瑰图/各区餐饮店数量分布
def get_pie(regions, region_count, category, count, mean, size, colors): num= len(size) width = 2 * np.pi / num rad = np.cumsum([width] * num) plt.figure(figsize=(8, 8),dpi=500) ax = plt.subplot(projection='polar') ax.set_ylim(-1, np.ceil(max(size) + 1)) ax.set_theta_zero_location('N',-5.0) ax.set_theta_direction(1) ax.grid(False) ax.spines['polar'].set_visible(False) ax.set_yticks([]) ax.set_thetagrids([]) ax.bar(rad, size, width=width, color=colors, alpha=1) ax.bar(rad, 1, width=width, color='white', alpha=0.15) ax.bar(rad, 3, width=width, color='white', alpha=0.1) ax.bar(rad, 5, width=width, color='white', alpha=0.05) ax.bar(rad, 7, width=width, color='white', alpha=0.03) # 设置text for i in np.arange(num): if i < 8: ax.text(rad[i], size[i]-0.2, f'{category[i]}\n{count[i]}家\n({mean[i]})', rotation=rad[i] * 180 / np.pi -5, rotation_mode='anchor', fontstyle='normal', fontweight='black', color='white', size=size[i]/2.2, ha="center", va="top" ) elif i < 15: ax.text(rad[i]+0.02, size[i]-0.7, f'{category[i]}\n{count[i]}家\n({mean[i]})', fontstyle='normal', fontweight='black', color='white', size=size[i] / 1.6, ha="center" ) else: ax.text(rad[i], size[i]+0.1, f'{category[i]} {count[i]}家 ({mean[i]})', rotation=rad[i] * 180 / np.pi + 85, rotation_mode='anchor', fontstyle='normal', fontweight='black', color='black', size=4, ha="left", va="bottom" ) cell_width = 20 cell_height = 5 axins1=inset_axes(ax,width=3.05, height=cell_height-0.6, loc=1) regions_len = len(regions) ncols = 2 nrows = regions_len // ncols + int(regions_len % ncols > 0) axins1.set_xlim(0,cell_width*3.5) axins1.set_ylim(cell_height* (nrows-0.5),1-cell_height/2.) axins1.yaxis.set_visible(False) axins1.xaxis.set_visible(False) axins1.set_axis_off() for i in range(regions_len): row = i % nrows col = i // nrows y = row*2 text_pos_x = cell_width * col + 10 axins1.text(text_pos_x-5, y, str(region_count[i]), fontsize=4,color='#FAFAFA',fontweight='bold', horizontalalignment='left',verticalalignment='center',backgroundcolor="#EC407A" ) axins1.text(text_pos_x, y, regions[i], fontsize=4,color='#3F51B5',fontweight='bold', horizontalalignment='left',verticalalignment='center' ) plt.show()

- 店铺较多的餐饮为甜点、快餐、咖啡厅、西餐等,紧随其后是浙菜、川菜、火锅、烧烤等类型
3.2 各餐饮类型人均消费
bar = ( Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='1000px',bg_color='#0d0735')) .add_xaxis(df_category_mean_tmp['类别'].tolist()) .add_yaxis("", df_category_mean_tmp['人均消费'].tolist()) .set_series_opts(label_opts=opts.LabelOpts(position="right", font_size=12, font_weight='bold', formatter='{c} 元'), ) .set_global_opts( xaxis_opts=opts.AxisOpts(is_show=False,), yaxis_opts=opts.AxisOpts( axislabel_opts=opts.LabelOpts(font_size=13,color='#fff200'), axistick_opts=opts.AxisTickOpts(is_show=False), axisline_opts=opts.AxisLineOpts(is_show=False) ), title_opts=opts.TitleOpts(title="各餐饮类型人均消费",pos_left='center',pos_top='1%', title_textstyle_opts=opts.TextStyleOpts(font_size=22,color="#38d9a9")), visualmap_opts=opts.VisualMapOpts(is_show=False, min_=5, max_=140, is_piecewise=False, dimension=0,), ) .reversal_axis() )
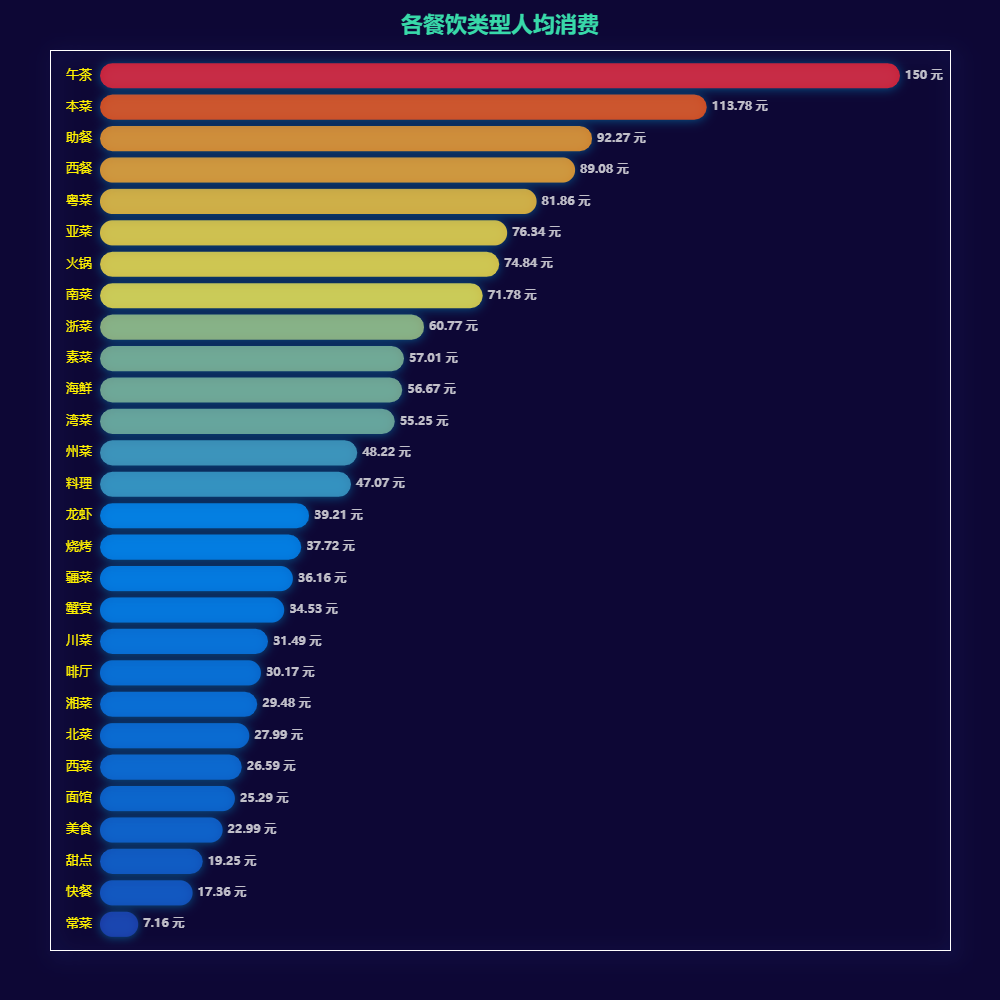
- 甜点、快餐的人均售价大概在15-20元之间,这也符合上海快节奏的城市生活
- 店铺数量较多餐饮类型的人均消费基本都在100以内
3.3 上海各区餐饮店数量地图分布
地图:
m0 = ( Map(init_opts=opts.InitOpts(width='1000px', height='800px',bg_color='#0d0735')) .add('', [list(z) for z in zip(regions, region_count)], '上海', is_map_symbol_show=False, ) .set_global_opts( title_opts=opts.TitleOpts( title="上海各区餐饮店数量分布", pos_left="center", pos_top='1%', subtitle='<制图@公众号:Python当打之年>', item_gap=5, title_textstyle_opts=opts.TextStyleOpts( font_size=24, font_weight="bold", color="#DC143C", ), subtitle_textstyle_opts=opts.TextStyleOpts(color="#94d82d", font_size=14, font_weight="bold") ), visualmap_opts=opts.VisualMapOpts( max_= 13000, is_piecewise=True, is_show=True, split_number = 10, pos_top='40%', pos_left='10%', ), ) )
柱状图:
bar = ( Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='300px',bg_color='#0d0735' )) .add_xaxis(regions) .add_yaxis("", region_count) .set_series_opts(label_opts=opts.LabelOpts(position="insideBottom", font_size=10, rotate='90', vertical_align='middle', horizontal_align='left', font_weight='bold', color='#e7298a', formatter='{b}: {c} 家'), markline_opts=opts.MarkLineOpts( data=[opts.MarkLineItem(name="平均:", type_ = 'average',)], label_opts=opts.LabelOpts(is_show=False)) ) .set_global_opts( xaxis_opts=opts.AxisOpts(is_show=False, boundary_gap=False), yaxis_opts=opts.AxisOpts(is_show=False), visualmap_opts=opts.VisualMapOpts( is_piecewise=True, split_number = 10, is_show=False, max_=13000,), title_opts=opts.TitleOpts( title=f"各区平均店铺:{df_region['数量'].mean().round(2)}家", pos_right="10%", pos_top='45%', title_textstyle_opts=opts.TextStyleOpts(font_size=13) ), tooltip_opts=opts.TooltipOpts( is_show=True), ) )
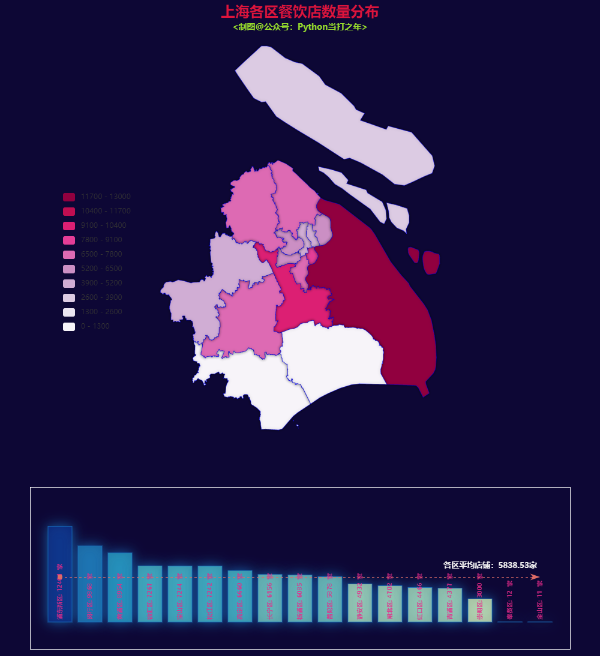
- 上海市各区中浦东新区的餐饮店铺数量最多,超过12000家
- 闵行区、黄浦区、徐汇区、宝山区、松江区、嘉定区、长宁区、杨浦区、普陀区的餐饮店铺数量也在5000家以上
3.4 各区餐饮口味好评率、环境好评率、服务好评率
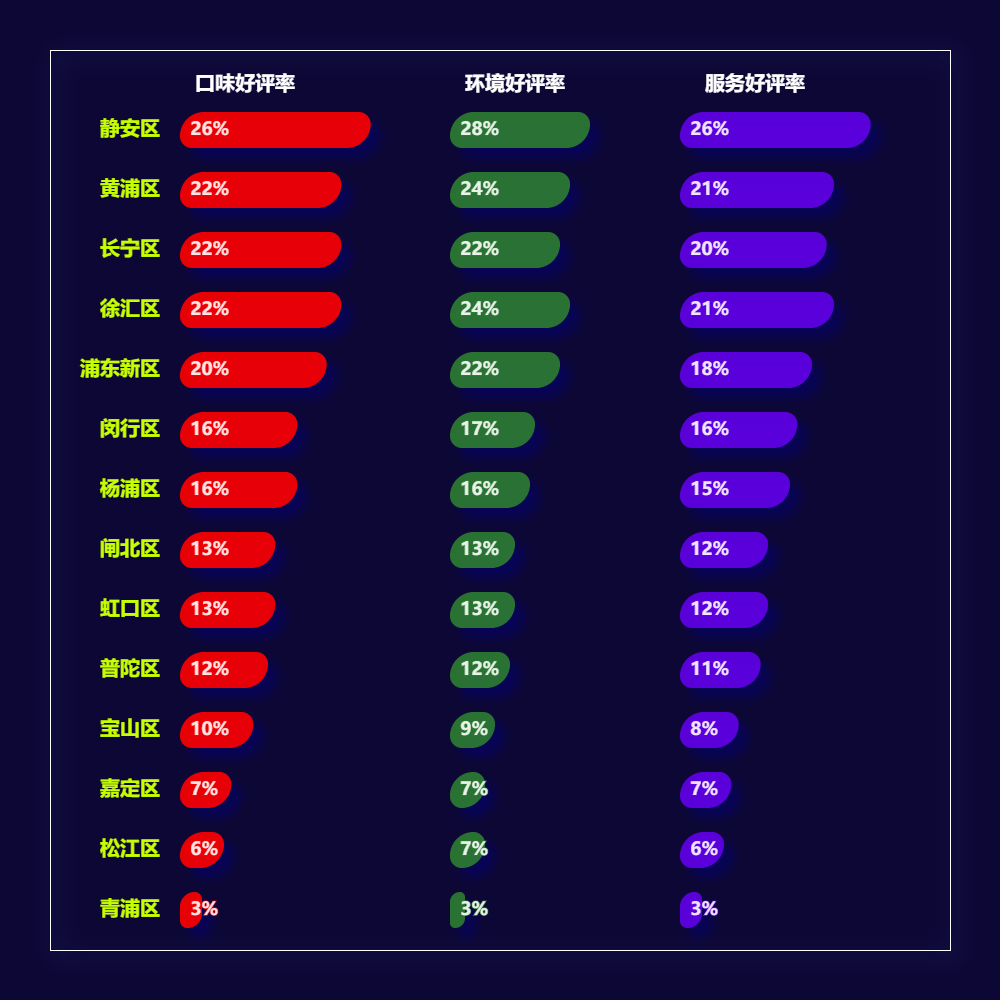
注:好评为评分8.0分以上
- 静安区、黄浦区、长宁区、徐汇区等几个区的店铺口味好评率、环境好评率、服务好评率都在20%以上
3.5 各餐饮类型口味好评率、环境好评率、服务好评率

- 南菜、素菜、本菜、亚菜、火锅等几个餐饮类别口味好评率、环境好评率、服务好评率普遍较高
4. 在线运行地址
篇幅原因,部分代码未展示,在线运行地址(含源码):
https://www.heywhale.com/mw/project/62c7d80db04acf0ba422e96c END
END
以上就是本期为大家整理的全部内容了,赶快练习起来吧,,如果需要数据文件,可以在公众号后台回复 “ 上海餐饮 ”获取,喜欢的朋友可以 点赞、点在看
点赞、点在看 也可以分享让更多人知道
也可以分享让更多人知道


