大家好,我是欧K~
本期我们通过分析山东省高考考生考试成绩分布数据以及双一流大学(985/211)录取山东省考生数据,看看:
- 山东省考生高考成绩主要集中在哪些区间
- 本科上线率有多少
- 双一流大学录取最低分各是多少
- 考生报考比较多的专业有哪些
- ...
希望对小伙伴们有所帮助,如有疑问或者需要改进的地方可以私信小编。
涉及到的库:
- Pandas — 数据处理
- Pyecharts — 数据可视化
可视化部分:
- 柱状图 — Bar
- 折线图 — Line
- 饼图 — Pie
- 组合组件 — Grid
1. 导入模块
import re import os import pandas as pd from pyecharts.charts import Bar from pyecharts.charts import Line from pyecharts.charts import Grid from pyecharts.charts import Pie from pyecharts import options as opts from pyecharts.commons.utils import JsCode
2. Pandas数据处理
2.1 读取数据
df = pd.read_excel('./data/2020年夏季高考和普通高中学业水平等级模拟考试文化成绩一分一段表.xlsx',header=None,skiprows=[0]) df.head(10)
结果:
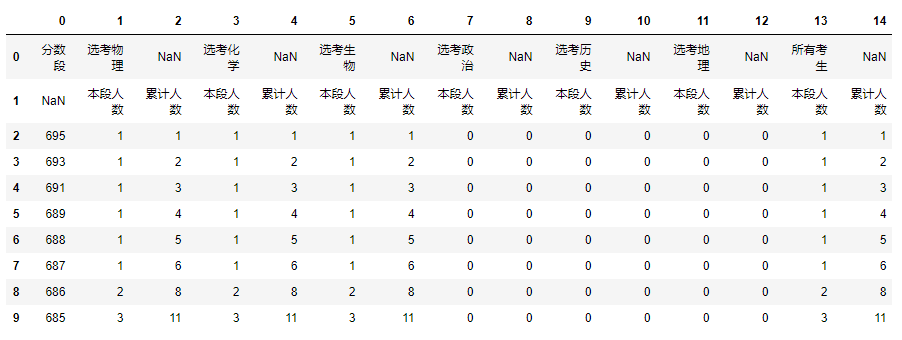
2.2 行数据填充,重置列索引,去除前2行
df.loc[0] = df.loc[0].fillna(method = 'ffill') df.iloc[:,0] = df.iloc[:,0].fillna('') df.columns = df.loc[0] + df.loc[1] df = df[2:] df.head(10)
结果:

3. Pyecharts可视化
3.1 所有考生及各学科总分分布图
colors = ["#00BCD4","#ea1d5d", "#ffb900", "#4FC3F7"] L1 = ( Line() .add_xaxis(df['分数段']) .add_yaxis("所有考生本段人数",df['所有考生本段人数'],symbol_size=0.5,) .set_series_opts( areastyle_opts=opts.AreaStyleOpts(opacity=1, color=colors[0]), label_opts=opts.LabelOpts(is_show=False), markarea_opts=opts.MarkAreaOpts( data=[ opts.MarkAreaItem( name="本科线", x=(435, 437),y=(0,2000), label_opts=opts.LabelOpts(color=colors[1]), itemstyle_opts=opts.ItemStyleOpts(color=colors[1]) ) ] ) ) .set_global_opts( legend_opts=opts.LegendOpts(is_show=False), tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), title_opts=opts.TitleOpts(title="所有考生总分分布",pos_bottom="93%",pos_left="center", title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=18), ), xaxis_opts=opts.AxisOpts(min_=df['分数段'].min(), axislabel_opts=opts.LabelOpts(font_size=12, color=colors[3]), axisline_opts=opts.AxisLineOpts( is_show=False,linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3])) ), yaxis_opts=opts.AxisOpts( axislabel_opts=opts.LabelOpts(font_size=12, color=colors[3]), axisline_opts=opts.AxisLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3]) ),) ) ) grid = Grid(init_opts=opts.InitOpts(width='1000px', height='1200px',bg_color='#0d0735')) grid.add(L1, grid_opts=opts.GridOpts(pos_bottom="75%", pos_top="5%"))
效果:

- 所有考生的成绩基本呈正太分布,本科线附近考生数量基本靠近最大值
- 理科(物理/化学/生物)考生的成绩分布与所有考生的成绩分布基本一致
- 文科(政治/历史/地理)考生的成绩分布呈非正太分布,存在本科线以下的小波峰,过线率要偏低
3.2 本科上线人数比例
b1 = ( Bar() .add_xaxis(df_rate_data.index.tolist()[::-1]) .add_yaxis('', df_rate_data[0].values.tolist()[::-1], category_gap='40%') .set_series_opts( label_opts=opts.LabelOpts( position='insideRight', vertical_align='middle', font_size=14, font_weight='bold', formatter='{c} %') ) .set_global_opts( xaxis_opts=opts.AxisOpts( position='top', axislabel_opts=opts.LabelOpts(font_size=16, color=colors[3]), axisline_opts=opts.AxisLineOpts( is_show=False,linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3])) ), yaxis_opts=opts.AxisOpts( axislabel_opts=opts.LabelOpts(font_size=16, color=colors[3]), axisline_opts=opts.AxisLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(width=2, color=colors[3]) ),), title_opts=opts.TitleOpts(title="本科上线人数比例", pos_top="3%", pos_right="center", title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=20),), ) .reversal_axis() )
效果:

- 本科上线考生占比 51.22%,基本一半以上的考生是过了本科线的
- 可以看出理科考生本科上线占比要明显高于文科考生
3.3 各学科考生比例
color_series = ['#C9DA36','#37B44E','#1E91CA','#6A368B','#D5225B','#CF7B25'] df1=df.iloc[-1,[i%2==0 and i!=0 for i in range(len(df.columns))]] subj_data = [round(i/df1.values.tolist()[-1]*100,2) for i in df1.values.tolist()][:-1] subj_name = ['物理','化学','生物','历史','地理','政治'] df_subj = pd.DataFrame(subj_data,index=subj_name,columns=['比例']) df_subj.sort_values('比例',ascending=False,inplace=True) P = ( Pie(init_opts=opts.InitOpts(width='1000px', height='600px',bg_color='#0d0735')) .add( "", [list(z) for z in zip(df_subj.index, df_subj['比例'])], radius=["30%", "70%"], center=["50%", "50%"], rosetype="radius", label_opts=opts.LabelOpts(is_show=False), ) .set_colors(color_series) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}%",font_size=16)) .set_global_opts( title_opts=opts.TitleOpts(title="各学科\n考生比例", pos_top="46%", pos_right="center", title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=28),), legend_opts=opts.LegendOpts(is_show=False), ) )
效果:

所有考生中选考政治科目的人数最多,占比超过2/3,达到了63.6%,选考历史的人数最少,占比为34.31%。
3.4 985/211大学(理工类)录取最低平均分数
line1 = ( Line() .add_xaxis(y_score_mean) .add_yaxis( series_name = '最低平均分', y_axis = x_data, symbol ="diamond", symbol_size=14, z=10, linestyle_opts=opts.LineStyleOpts(color="#FFEB3B", width=3), itemstyle_opts=opts.ItemStyleOpts(border_width=2, border_color="#C62828", color="#FFEB3B"), label_opts=opts.LabelOpts(color='#FFEB3B',position='right'), ) ) bar1 = ( Bar() .add_xaxis(x_data) .add_yaxis("2017年", y_score_2017, color='#EC407A') .add_yaxis("2018年", y_score_2018, color='#26A69A') .add_yaxis("2019年", y_score_2019, color='#3F51B5') .set_series_opts( label_opts=opts.LabelOpts( position='inside', vertical_align='middle', ), ) .set_global_opts( tooltip_opts=opts.TooltipOpts(is_show=True, trigger='axis', axis_pointer_type='cross'), datazoom_opts=opts.DataZoomOpts(orient="vertical",range_start=70,range_end=100), title_opts=opts.TitleOpts( title='985/211大学(理工类)录取最低分数', subtitle='<制图@公众号:Python当打之年>', pos_left='center', pos_top='1%', title_textstyle_opts=opts.TextStyleOpts(color='#ffb900', font_size=18), ), legend_opts=opts.LegendOpts(pos_left="center", pos_top='7%'), xaxis_opts=opts.AxisOpts( min_=400, axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'), axisline_opts=opts.AxisLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093'))), yaxis_opts=opts.AxisOpts( axislabel_opts=opts.LabelOpts(font_size=14, color='#c2ff00'), axisline_opts=opts.AxisLineOpts( is_show=False, linestyle_opts=opts.LineStyleOpts(width=2, color='#DB7093') ), ) ) .reversal_axis() )
效果:

- 985/211大学(理工类)录取平均最低分数最高的前三甲学校:北京大学(689),复旦大学(681),上海交通大学(673)
- 中国科学技术大学(671),浙江大学(670),中国人民大学(668),南京大学(668)次之
3.5 985/211大学(理工类)录取最低平均位次

- 985/211大学(理工类)录取平均最低位次最高的前三甲学校:清华大学(20),北京大学(77),复旦大学(223),上海交通大学(473)
- 中国科学技术大学(554), 浙江大学(572),南京大学(687)紧随其后
3.6 985/211大学(文史类)录取最低平均分数

- 985/211大学(文史类)录取平均最低分数最高的前三甲学校:清华大学(664),北京大学(653),复旦大学(645),
- 中国人民大学(642),上海交通大学(641),浙江大学(639)次之
3.7 985/211大学(文史类)录取最低平均位次

- 985/211大学(文史类)录取平均最低位次最高的前三甲学校:清华大学(20),北京大学(29),复旦大学(91)
- 中华人民大学(118),上海交通大学(144),浙江大学(172)紧随其后
3.8 985/211大学录取数量前15的理工类专业
P1 = ( Pie(init_opts=opts.InitOpts(width='1000px', height='600px',bg_color='#0d0735')) .add( "", [list(z) for z in zip(df_subj_top10['专业名称'].values.tolist(), df_subj_top10['数量'].values.tolist())], radius=["40%", "70%"], center=["50%", "50%"], label_opts=opts.LabelOpts(is_show=False), ) .set_colors(color_series) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=16)) .set_global_opts( title_opts=opts.TitleOpts(title="录取数量前15的\n理工类专业", pos_top="46%", pos_right="center", title_textstyle_opts=opts.TextStyleOpts(color=colors[2], font_size=28),), legend_opts=opts.LegendOpts(is_show=False), ) )
效果:

3.9 985/211大学录取数量前15的文史类专业

4. 项目在线运行地址
篇幅原因,部分代码未展示,在线运行地址(含源码):https://www.heywhale.com/mw/project/62a037c3744a8f77ab3c0450 END
END
以上就是本期为大家整理的全部内容了,赶快练习起来吧,喜欢的朋友可以 点赞、点在看
点赞、点在看 也可以分享让更多人知道
也可以分享让更多人知道


