💥1 概述
基于二进制草蝉优化算法选择特征并使用KNN(K-Nearest Neighbors,K最近邻算法)进行训练是一种特征选择和分类算法的组合。这种方法主要用于解决特征选择问题,并利用选定的特征集合来训练KNN分类器。
下面是该算法的基本步骤:
特征选择:
采用二进制草蝉优化算法对原始特征集进行优化,从而选择出最佳特征子集。二进制草蝉优化算法是一种基于草蝉行为的启发式优化算法,用于解决特征选择问题。该算法通过模拟草蝉的生存行为来选择特征子集,以使得目标函数最小化或最大化。
特征提取:
通过二进制草蝉优化算法选择出的最佳特征子集,对原始数据集进行特征提取,得到一个新的数据集,该数据集只包含选定的特征。
数据预处理:
对特征提取后的数据集进行预处理,包括归一化、标准化或其他必要的数据处理步骤,以确保数据的可比性和有效性。
KNN分类器:
使用KNN算法来对处理后的数据集进行分类。KNN是一种常见的分类算法,它通过计算待分类样本与训练样本之间的距离,选取最近的K个训练样本,并根据这K个样本的分类标签来预测待分类样本的标签。
训练和测试:
使用经过特征选择和KNN分类器训练得到的模型,对测试数据进行分类,评估分类结果的准确性和性能。
需要注意的是,特征选择是为了去除冗余和噪音特征,提高分类性能和降低计算复杂度。而KNN作为分类器是一种懒惰学习方法,具有简单易实现的优点,但在大规模数据上可能效率较低。
最终的结果取决于草蝉优化算法的性能、特征选择和KNN分类器的调优以及数据集本身的特性。因此,在实际应用中,可能需要进行多次实验和优化,以选择最合适的特征子集和分类器参数。同时,建议参考相关研究论文和文献,以获得更深入的了解和具体实现细节。
📚2 运行结果
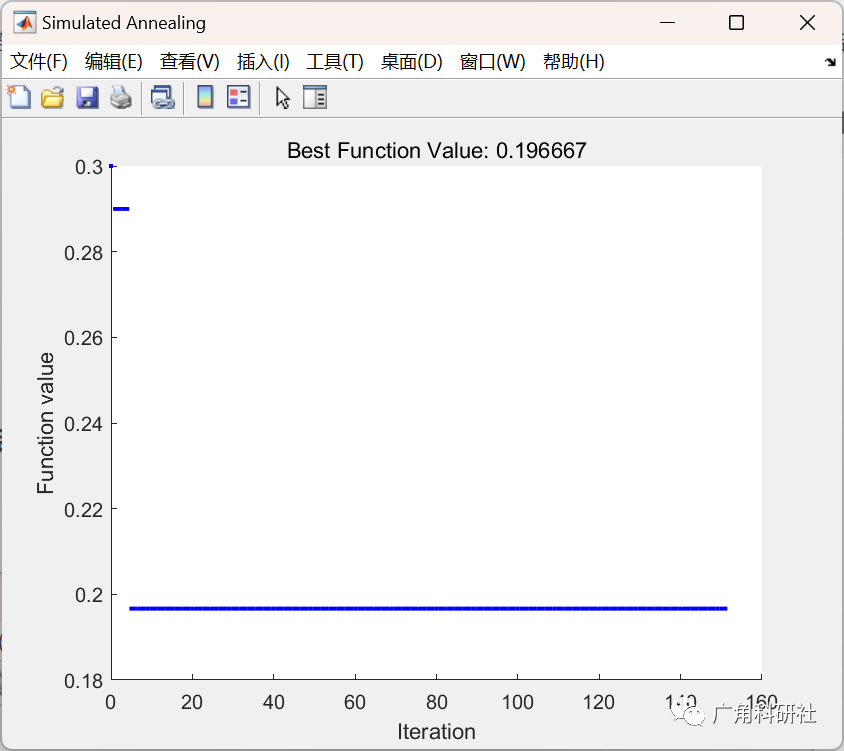
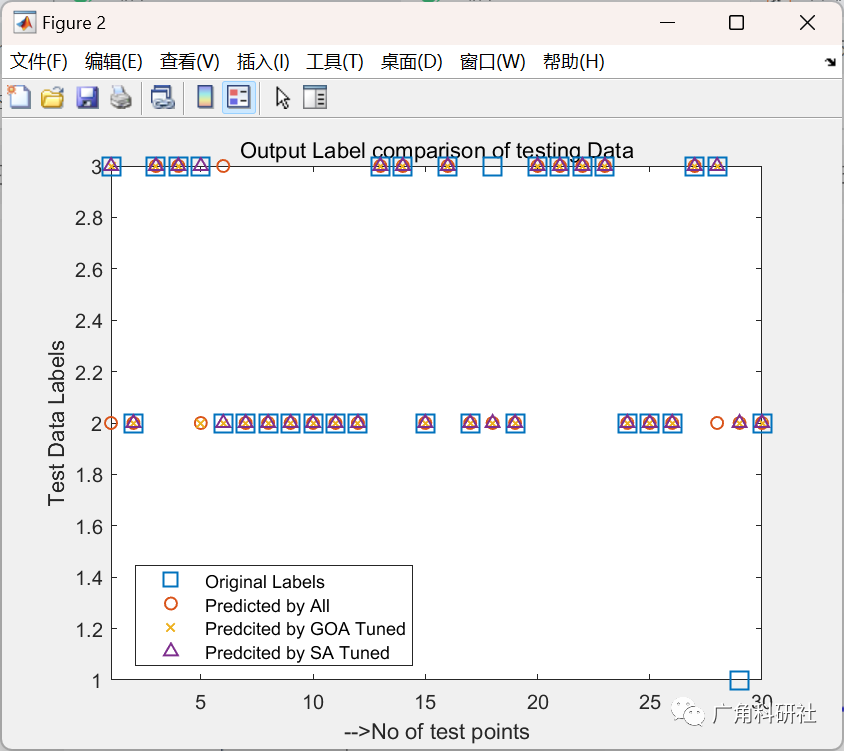
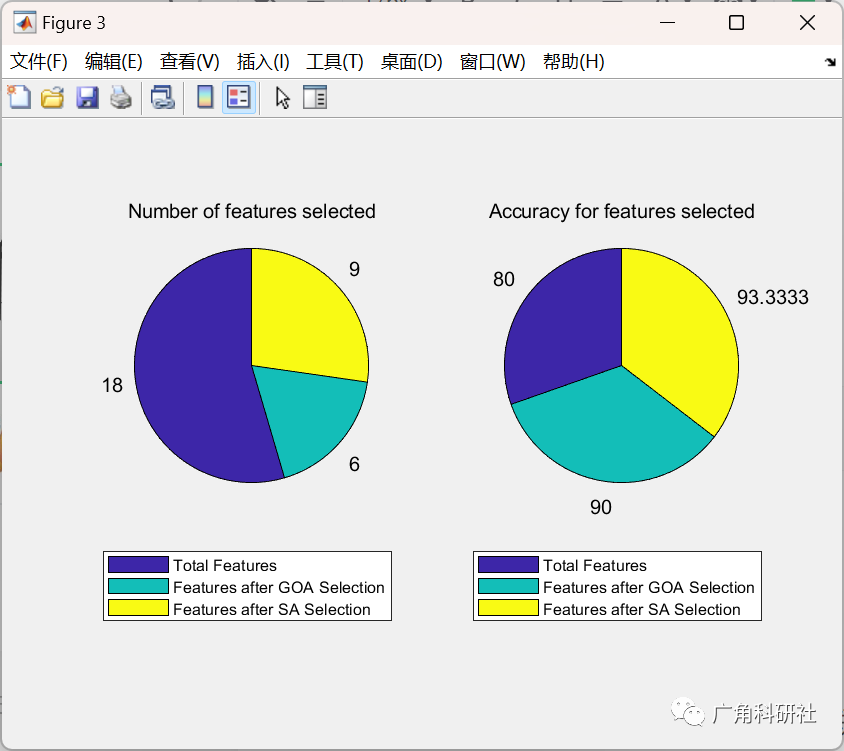
主函数部分代码:
close all clear clc addpath(genpath(cd)) %% load the data % load winedata.mat load breast-cancer-wisconsin % load ionosphere % load Parliment1984 % load heartdata load lymphography %% % preprocess data to remove Nan entries for ii=1:size(Tdata,2) nanindex=isnan(Tdata(:,ii)); Tdata(nanindex,:)=[]; end labels=Tdata(:,end); %classes attributesData=Tdata(:,1:end-1); %wine data % for ii=1:size(attributesData,2) %normalize the data % attributesData(:,ii)=normalize(attributesData(:,ii)); % end [rows,colms]=size(attributesData); %size of data %% seprate the data into training and testing [trainIdx,~,testIdx]=dividerand(rows,0.8,0,0.2); trainData=attributesData(trainIdx,:); %training data testData=attributesData(testIdx,:); %testing data trainlabel=labels(trainIdx); %training labels testlabel=labels(testIdx); %testing labels %% KNN classification Mdl = fitcknn(trainData,trainlabel,'NumNeighbors',5,'Standardize',1); predictedLables_KNN=predict(Mdl,testData); cp=classperf(testlabel,predictedLables_KNN); err=cp.ErrorRate; accuracy=cp.CorrectRate; %% SA optimisation for feature selection dim=size(attributesData,2); lb=0;ub=1; x0=round(rand(1,dim)); fun=@(x) objfun(x,trainData,testData,trainlabel,testlabel,dim); options = optimoptions(@simulannealbnd,'MaxIterations',150,... 'PlotFcn','saplotbestf'); [x,fval,exitflag,output] = simulannealbnd(fun,x0,zeros(1,dim),ones(1,dim),options) ; Target_pos_SA=round(x); % final evaluation for GOA tuned selected features [error_SA,accuracy_SA,predictedLables_SA]=finalEval(Target_pos_SA,trainData,testData,... trainlabel,testlabel); %% GOA optimisation for feature selection SearchAgents_no=10; % Number of search agents Max_iteration=100; % Maximum numbef of iterations [Target_score,Target_pos,GOA_cg_curve, Trajectories,fitness_history,... position_history]=binaryGOA(SearchAgents_no,Max_iteration,lb,ub,dim,... trainData,testData,trainlabel,testlabel); % final evaluation for GOA tuned selected features [error_GOA,accuracy_GOA,predictedLables_GOA]=finalEval(Target_pos,trainData,testData,trainlabel,testlabel); %% % plot for Predicted classes figure plot(testlabel,'s','LineWidth',1,'MarkerSize',12) hold on plot(predictedLables_KNN,'o','LineWidth',1,'MarkerSize',6) hold on plot(predictedLables_GOA,'x','LineWidth',1,'MarkerSize',6) hold on plot(predictedLables_SA,'^','LineWidth',1,'MarkerSize',6) % hold on % plot(predictedLables,'.','LineWidth',1,'MarkerSize',3) legend('Original Labels','Predicted by All','Predcited by GOA Tuned',... 'Predcited by SA Tuned','Location','best') title('Output Label comparison of testing Data') xlabel('-->No of test points') ylabel('Test Data Labels' ) axis tight % pie chart for accuracy corresponding to number of features figure subplot(1,2,1) labels={num2str(size(testData,2)),num2str(numel(find(Target_pos))),... num2str(numel(find(Target_pos_SA)))}; pie([(size(testData,2)),numel(find(Target_pos)),numel(find(Target_pos_SA))],labels) title('Number of features selected') legendlabels={'Total Features','Features after GOA Selection',... 'Features after SA Selection'}; legend(legendlabels,'Location','southoutside','Orientation','vertical') subplot(1,2,2) labels={num2str(accuracy*100),num2str(accuracy_GOA*100),num2str(accuracy_SA*100)}; pie([accuracy,accuracy_GOA,accuracy_SA].*100,labels) title('Accuracy for features selected') legendlabels={'Total Features','Features after GOA Selection',... 'Features after SA Selection'}; legend(legendlabels,'Location','southoutside','Orientation','vertical')
🎉3 参考文献
[1]张著英,黄玉龙,王翰虎.一个高效的KNN分类算法[J].计算机科学,2008(03):170-172.
部分理论引用网络文献,若有侵权联系博主删除。

