一个完全合作式的多智能体任务(我们有n个智能体,这n个智能体需要相互配合以获取最大奖励)可以描述为去中心化的部分可观测马尔可夫决策模型(Dec-POMDP),通常用一个元组G GG来表示:

IQL
IQL论文全称为:MultiAgent Cooperation and Competition with Deep Reinforcement Learning
多智能体环境中,状态转移和奖励函数都是受到所有智能体的联合动作的影响的。对于多智能体中的某个智能体来说,它的动作值函数是依据其它智能体采取什么动作才能确定的。因此对于一个单智能体来说它需要去了解其它智能体的学习情况。
这篇文章的贡献可能就是在于将DQN扩展到分散式的多智能体强化学习环境中吧,使其能够去处理高维复杂的环境。
作者采用的环境是雅塔丽的Pong环境。作者基于不同的奖励函数设计来实现不同的多智能体环境。在竞争环境下,智能体期望去获取比对方更多的奖励。在合作的环境下,智能体期望去寻找到一个最优的策略去保持上图中的白色小球一直在游戏中存在下去。
为了测试分散式DQN算法的性能,作者只通过奖励函数的设计就构建出来了不同的多智能体范式环境:
- 完全竞争式:胜利方奖励
+1,失败方奖励-1,是一个零和博弈。 - 完全合作式:在这个环境设定下,我们期望这个白色小球在环境中存在的时间越长越好,如果一方失去了球,则两方的奖励都是
-1。 - 非完全竞争式:在完全竞争和完全合作式中,失去小球的一方奖励都式
-1,对于胜利一方,作者设置一个系数ρ ∈ [ − 1 , 1 ] \rho \in [-1, 1]ρ∈[−1,1]来看参数的改变对实验结果的影响。
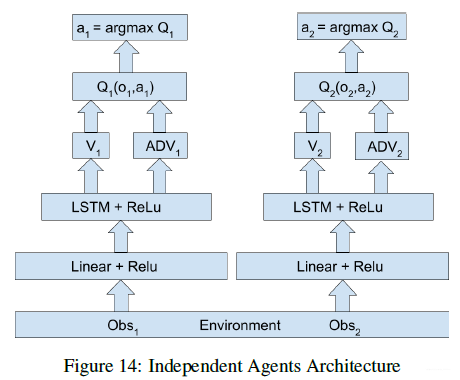
IQL(Independent Q-Learning)算法中将其余智能体直接看作环境的一部分,也就是对于每个智能体a aa都是在解决一个单智能体任务,很显然,由于环境中存在智能体,因此环境是一个非稳态的,这样就无法保证收敛性了,并且智能体会很容易陷入无止境的探索中,但是在工程实践上,效果还是比较可以的。
独立的智能体网络结构可以参考下图所示:
VDN
VDN论文全称为:Value-Decomposition Networks For Cooperative Multi-Agent Learning
在合作式多智能体强化学习问题中,每个智能体基于自己的局部观测做出反应来选择动作,来最大化团队奖励。对于一些简单的合作式多智能体问题,可以用中心式(centralized)的方法来解决,将状态空间和动作空间做一个拼接,从而将问题转换成一个单智能体的问题。这会使得某些智能体在其中滥竽充数。
另一种极端方式式训练独立的智能体,每个智能体各玩各的,也不做通信,也不做配合,直接暴力出奇迹。这种方式对于每个智能体来说,其它智能体都是环境的一部分,那么这个环境是一个非平稳态的(non-stationary),理论上的收敛性是没法证明的。还有一些工作在对每个智能体都基于其观测设计一个奖励函数,而不是都用一个团队的团队奖励,这种方式的难点在于奖励函数的设计,因为设计的不好很容易使其陷入局部最优。
VDN中提出一种通过反向传播将团队的奖励信号分解到各个智能体上的这样一种方式。其网络结构如下图所示:
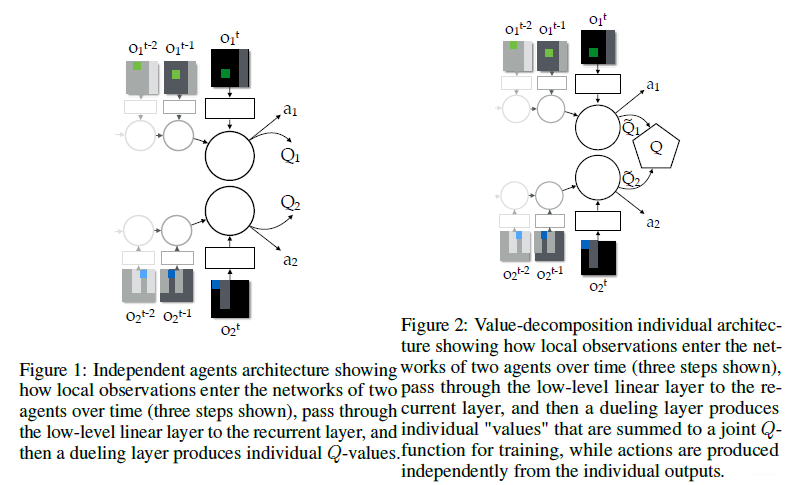
先看上图中的图1,画的是两个独立的智能体,因为对每个智能体来说,观测都是部分可观测的,所以Q 函数是被定义成基于观测历史数据所得到的Q ( h t , a t ) ,实际操作的时候直接用RNN来做就可以。图2说的就是联合动作值函数由各个智能体的值函数累加得到的:

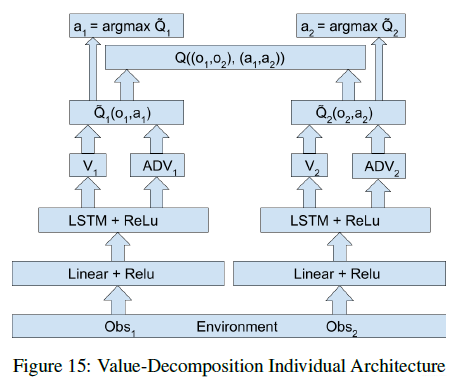
值分解的独立的智能体网络结构可以参考下图所示:
如果在此基础上在加上底层的通信的话可以表示为如下形式(其实就是将各个智能体的观测给到所有的智能体):
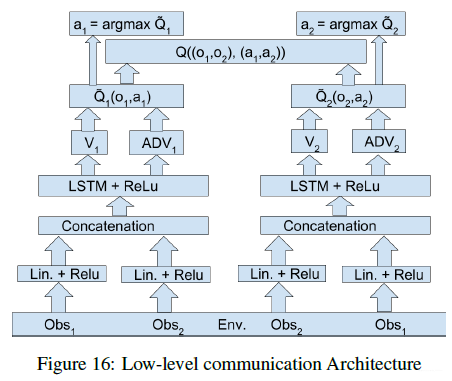
如果是在高层做通信的话可以得到如下形式:
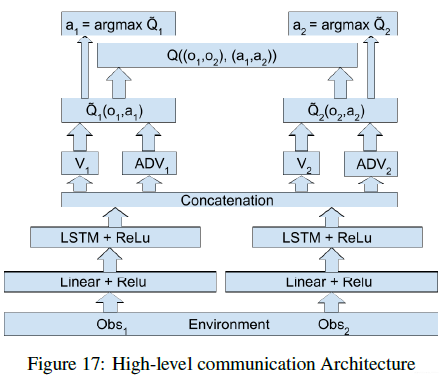
如果是在底层加上高层上都做通信的话可以得到如下形式:
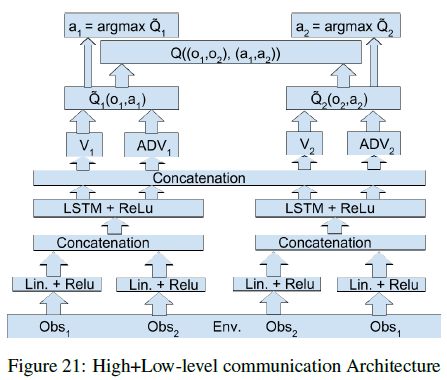
如果是集中式的结构的话,可以表示为如下形式:
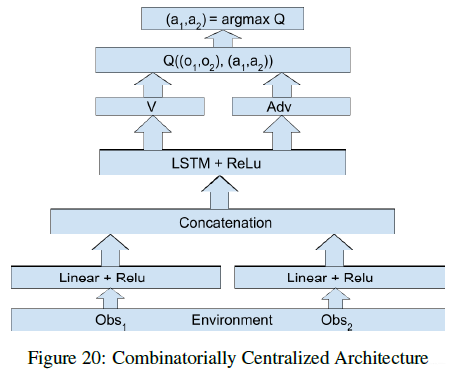
QMIX
QMIX论文全称为:QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
在之前的值分解网络中,拿到了联合动作的Q QQ值之后,我们就可以直接取能够获取最大的Q t o t ( τ , u ) 所对应的联合动作。这种方式就能够实现集中式学习,但是得到分布式策略。并且对全局值函数做argmax与对单个智能体地值函数做argmax能够得到相同的结果:

这样的话,每个智能体a 都可以基于Q a以贪婪策略选择动作。由于每个子智能体都采用贪婪策略,因此这个算法必定会是off-policy的算法,这一点是很容易实现的,并且样本的利用率会比较高。在VDN中采用的是线性加权,因此上述等式会成立,而如果是采用一个神经网络来学习融合各个智能体的Q 函数的话,上述等式就未必会成立了。
在QMIX中也是需要一个联合动作值函数的,但是与值分解网络的不同之处在于,这个联合动作值函数并不是简单地由各个智能体的值函数线性相加得到的。为了保证值函数的单调性来使得上述等式(1)能够成立,作者对联合动作值函数Q t o t 和单个智能体动作值函数Q a 之间做了一个约束:

设计思想如上所示,具体的网络结构如下图所示:
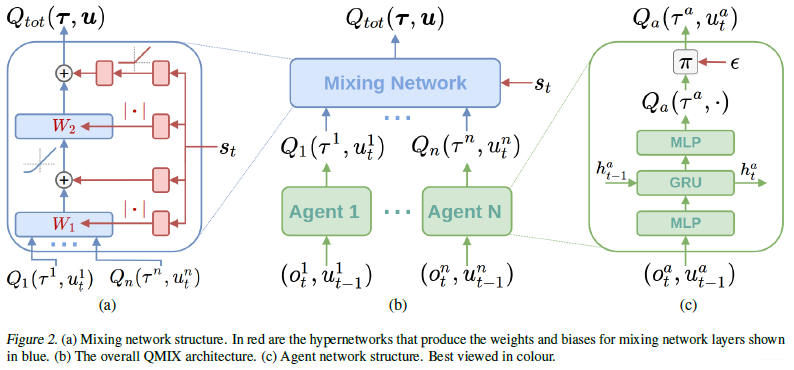
上述这个复杂的网络结构可以拆分为如下三部分:

hypernetworks:hypernetworks网络去产生mixing network的权重,超参数网络输入状态s ,输出Mixing网络的每一层的超参数向量,激活函数来使得输出非负,对于Mixing网络参数的偏置并没有非负的要求。
QMIX的训练方式是端到端的训练:

上述算法中,单纯地去考虑前向传播的话,智能体之间其实是没有配合的。仅仅是取每个智能体能够获得的最大的值函数。因为对于单个智能体来说,它的最优动作是基于队友智能体的动作下得到的,但是由于整个网络是端到端进行训练的,所以感觉问题也不大。
还有就是在基于单个智能体的动作值函数下得到联合动作值函数的过程中,也就是在Mixing网络中有考虑状态s t s_{t}st,所以相当于是有考虑全局的信息下去得到一个联合动作值函数。
QTRAN
QTRAN论文全称为:QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement learning- 代码:
https://github.com/Sonkyunghwan/QTRAN
之前说的VDN和QMIX都是值分解领域的两大标杆性文章,并且在一般的工程项目实战上VDN和QMIX的效果就还是比较好的,不过是在论文中的效果有被弱化,更具体地可以参考看一下这篇文章:RIIT: Rethinking the Importance of Implementation Tricks in Multi-Agent Reinforcement Learning。但是这篇QTRAN从理论层面还是值得分析一下的:
值分解地文章其实就是在保证联合动作取argmax的时候能够是对各个智能体的值函数取argmax。VDN中采用的是线性求和的方式,QMIX中采用的是保证单调性。对于一些任务,比如像联合动作的最优就是各个智能体的单独的最优的值函数,这样的问题可以采用这种方式,对于不是这类型的问题的话,这种限制就太强了。QTRAN提出了一种新的值分解的算法。
不管这个值分解如何分解,其实它们都需要取保证一个东西:

VDN和QMIX中的线性求和和保证单调性都能够去保证上述条件的成立,也就是给了两个充分条件,但不是必要条件。为了之后更好的理论分析,在QTRAN中对上述这个东西做了一个定义IGM (Individual-Global-Max):

QTRAN直观理解

可分解值函数的充分条件


说明只有在各个智能体都采取最优动作的时候才能获得联合动作值函数最大。IGM条件得证。
可分解值函数的必要条件

这个就是VDN了,不同之处就是多了一个修正项B
其网络结构如下:
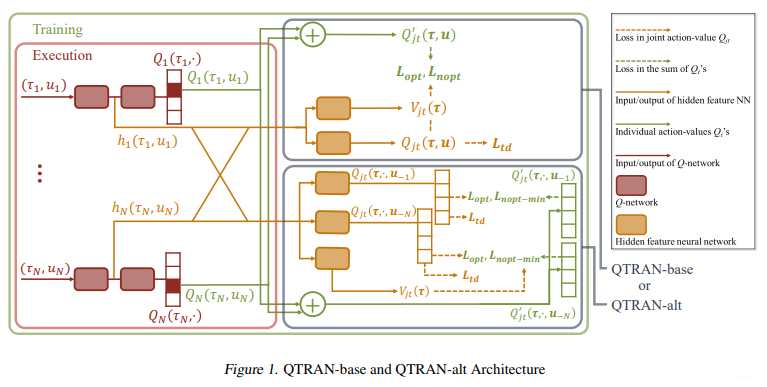
网络结构中主要有三部分:

此时损失函数可以表达成如下形式:

第一个lossL t d 可以无忧无虑地去近似最优的联合动作值函数,下面两个就是用来去满足可分解值函数地充分必要条件的。
除此之外作者还提出了几个QTRAN算法的变种,整体算法如下图所示:

参考
- MultiAgent Cooperation and Competition with Deep Reinforcement Learning
- Value-Decomposition Networks For Cooperative Multi-Agent Learning
- QMIX: Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning
- QTRAN: Learning to Factorize with Transformation for Cooperative Multi-Agent Reinforcement learning

