1.写在前面
就在7月19日,MetaAI开源了LLama2大模型,Meta 首席科学家、图灵奖获得者 Yann LeCun在推特上表示Meta 此举可能将改变大模型行业的竞争格局。一夜之间,大模型格局再次发生巨变。
推文上列了Llama2的网站和论文,小卷给大家贴一下,感兴趣的友友可以自己看看
论文:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Github页:https://github.com/facebookresearch/llama
2.LLama2是什么
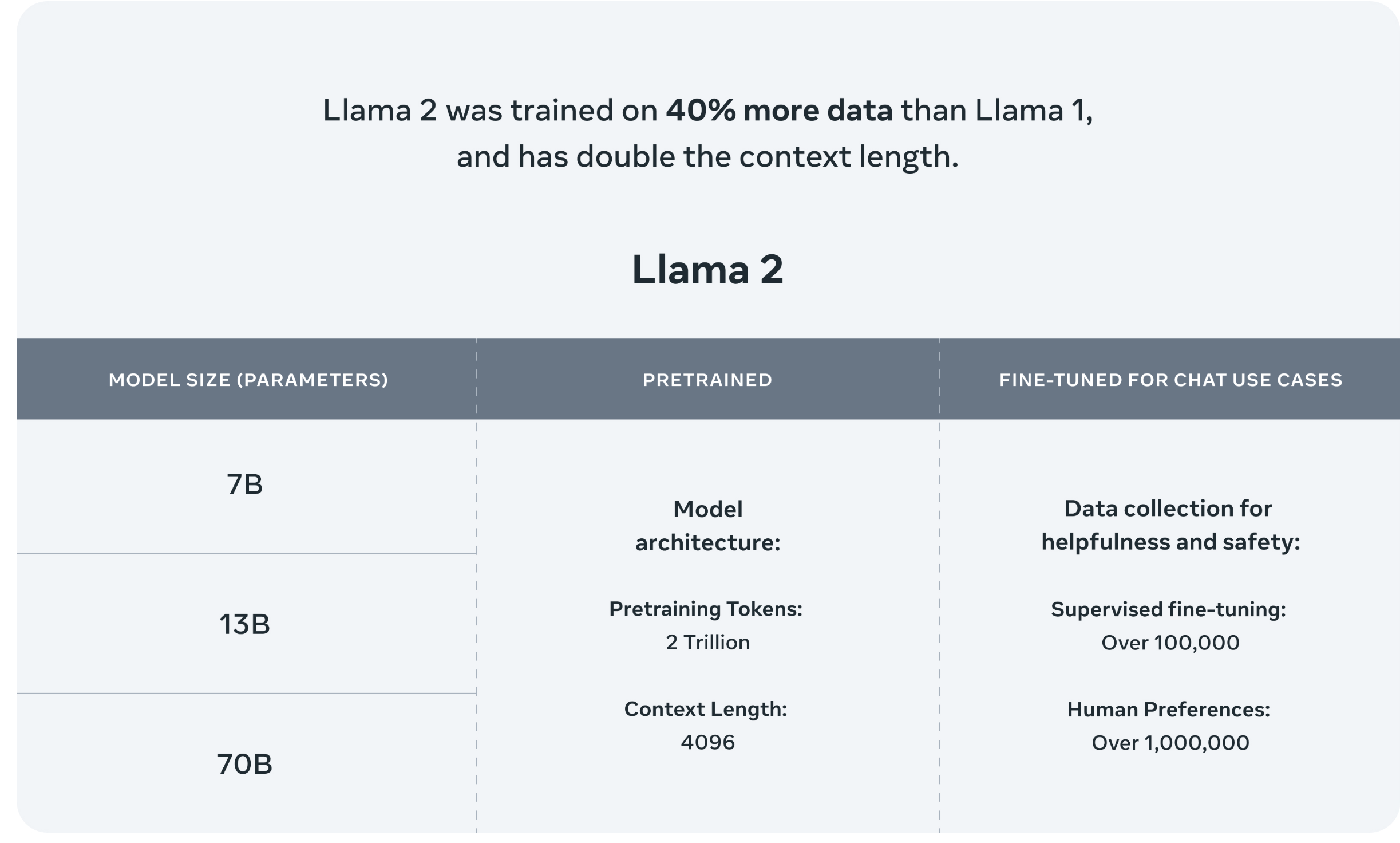
Llama官网的说明是Llama2下一代开源大语言模型,可免费用于学术研究或商业用途。
目前模型有7B、13B、70B三种规格,预训练阶段使用了2万亿Token,SFT阶段使用了超过10w数据,人类偏好数据超过100w。
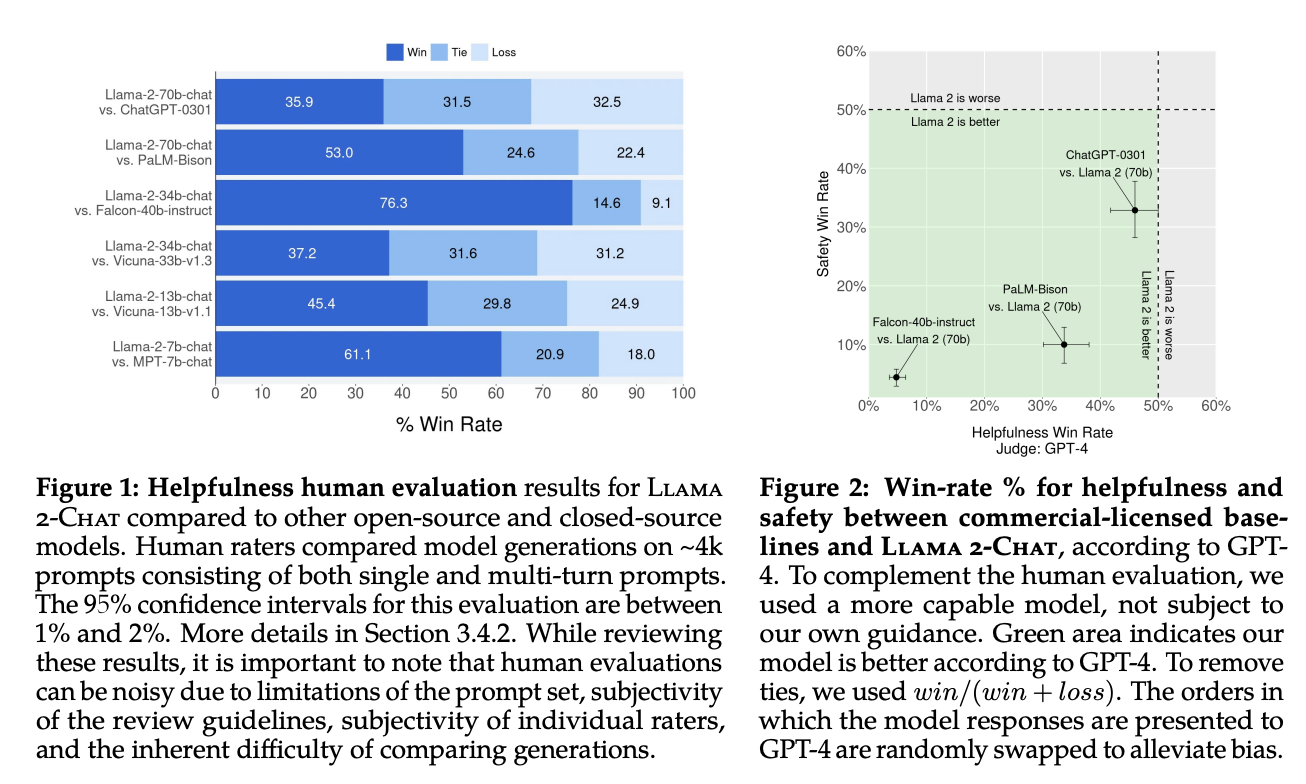
另外大家最关心的Llama2和ChatGPT模型的效果对比,在论文里也有提到,
对比GPT-4,Llama2评估结果更优,绿色部分表示Llama2优于GPT4的比例
虽然中文的占比只有0.13%,但后续会有一大推中文扩充词表预训练&领域数据微调的模型被国人放出。这不才开源几天而已,GIthub上就已经有基于Llama2的中文大模型了。。。
3.部署使用
关于LLama2的技术细节就不再多说了,大家可以自行查阅。接下来就教大家怎么自己玩一玩LLama2对话大模型。
大部分人都是没有本地GPU算力的,我们选择在云服务器上部署使用。我这里用的是揽睿星舟平台的GPU服务器(便宜好用,3090只要1.9/小时,且已在平台上预设了模型文件,无需再次下载)
新用户注册还送2小时的3090算力,记得注册时码写4104
3.1新建空间
登录:https://www.lanrui-ai.com/console/workspace
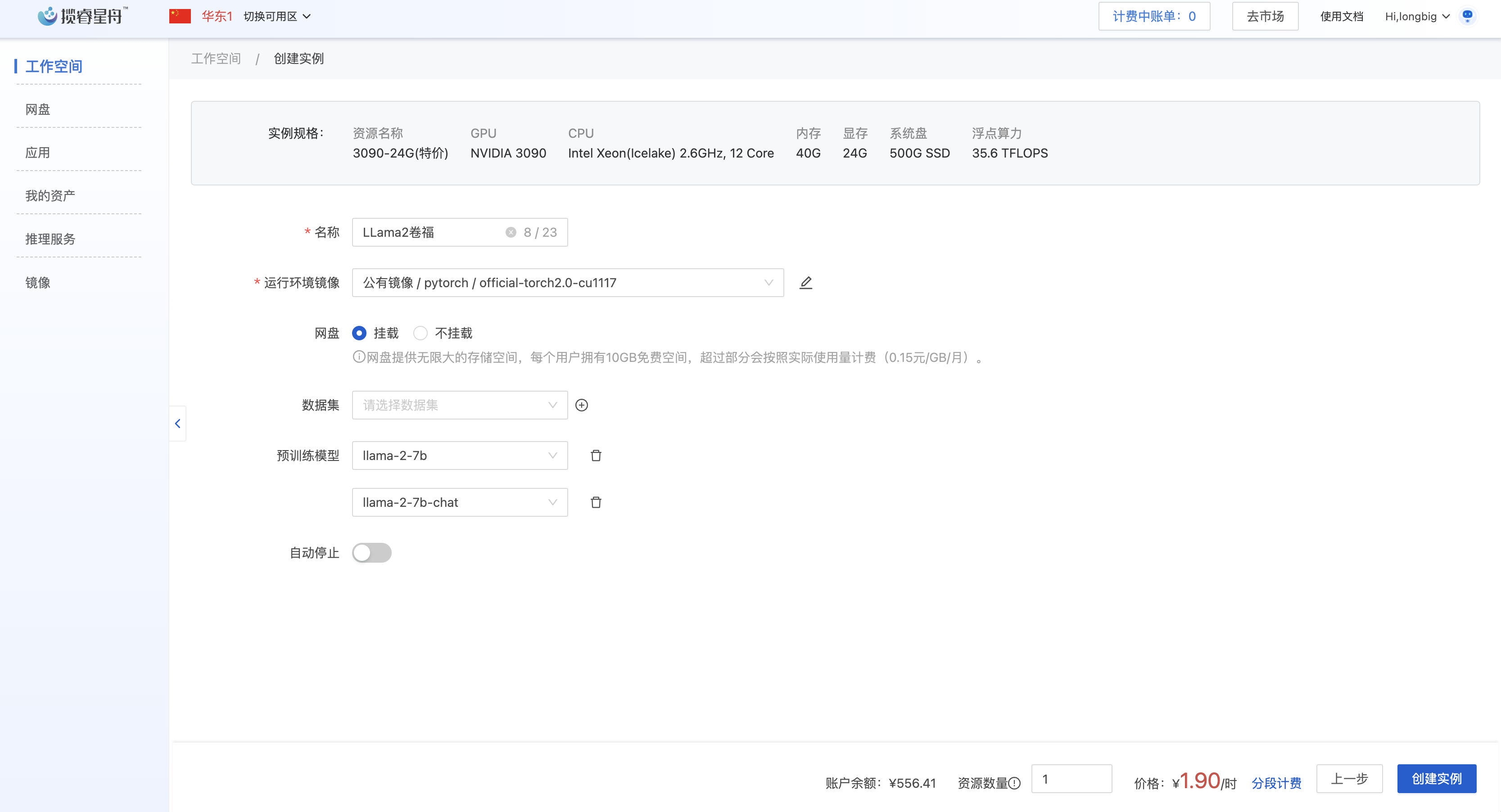
创建一个工作空间,运行环境镜像挂载公有镜像:pytorch: official-torch2.0-cu1117。选择预训练模型:llama-2-7b 和 llama-2-7b-chat。然后创建实例
3.2下载代码
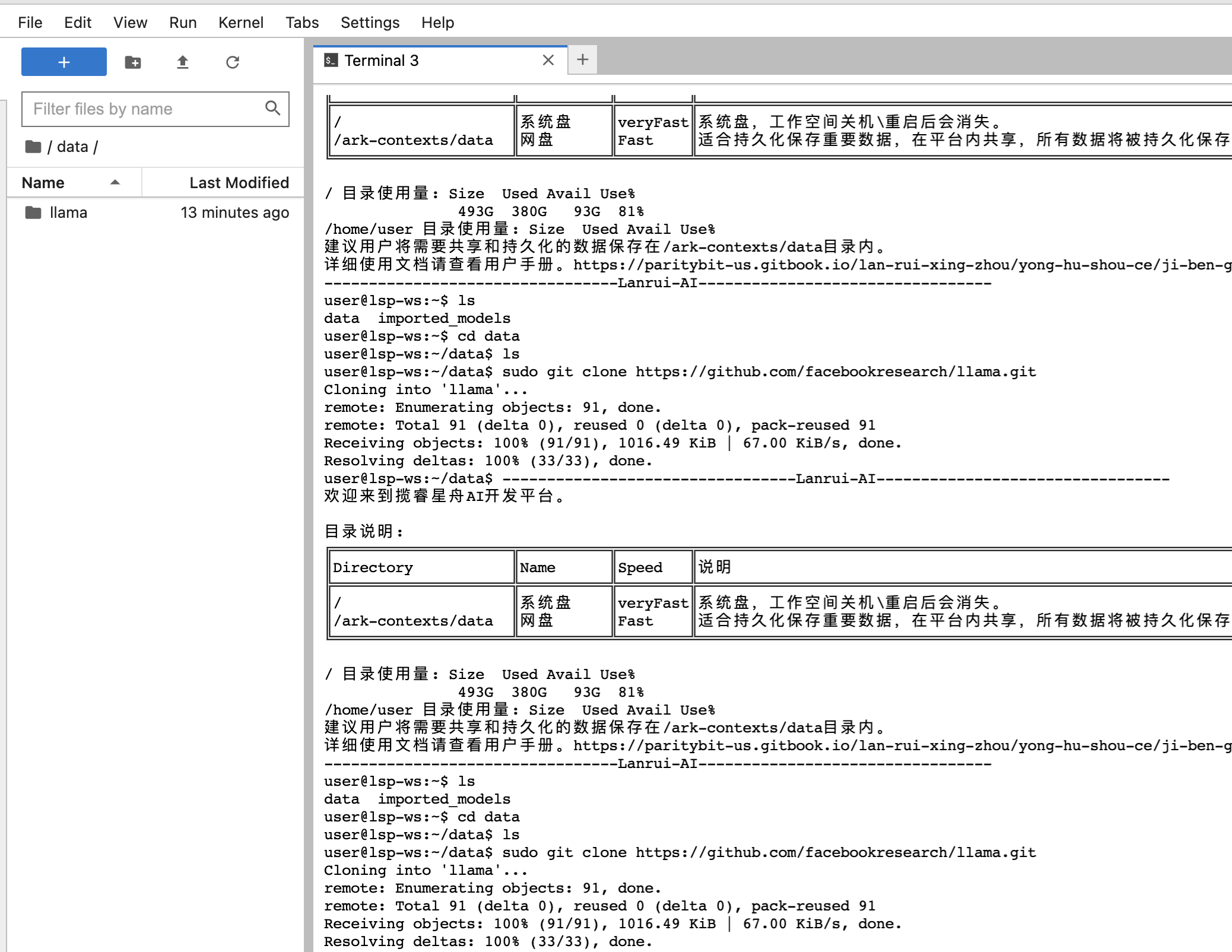
实例创建完成后,以jupyterLab方式登录服务器,新建一个Terminal,然后进入到data目录下
cd data
下载代码
执行下面的命令从GIthub上拉取llama的代码
sudo git clone https://github.com/facebookresearch/llama.git
下载完成后,会多一个llama目录
3.3运行脚本
进入llama目录
cd llama
安装依赖
sudo pip install -e .
测试llama-2-7b模型的文本补全能力
命令行执行:
torchrun --nproc_per_node 1 example_text_completion.py \
--ckpt_dir ../../imported_models/llama-2-7b/Llama-2-7b \
--tokenizer_path ../../imported_models/llama-2-7b/Llama-2-7b/tokenizer.model \
--max_seq_len 128 --max_batch_size 4
文本补齐效果示例:
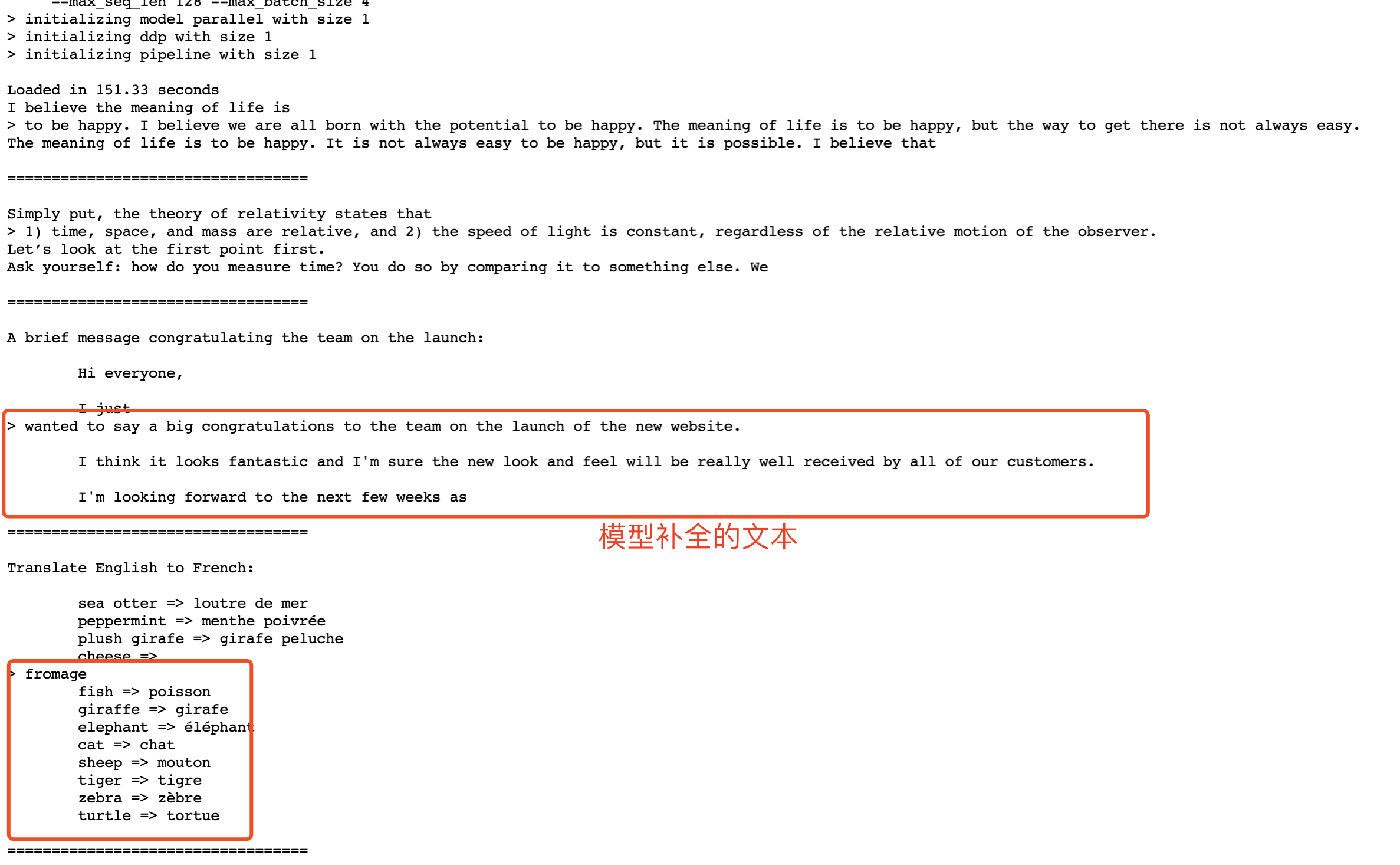
上面的例子是在python脚本里写了一段话,让模型补全后面的内容。
测试llama-2-7b模型的对话能力
修改llama目录权限为777,再修改example_chat_completion.py文件中的ckpt_dir和tokenizer_path路径为你的llama-2-7b-chat模型的绝对路径
// 1.修改目录权限为可写入
chmod 777 llama
//2.修改example_chat_completion.py文件里的参数
ckpt_dir: str = "/home/user/imported_models/llama-2-7b-chat/Llama-2-7b-chat/",
tokenizer_path: str = "/home/user/imported_models/llama-2-7b-chat/Llama-2-7b-chat/tokenizer.model"
//3.运行对话脚本
torchrun --nproc_per_node 1 example_chat_completion.py
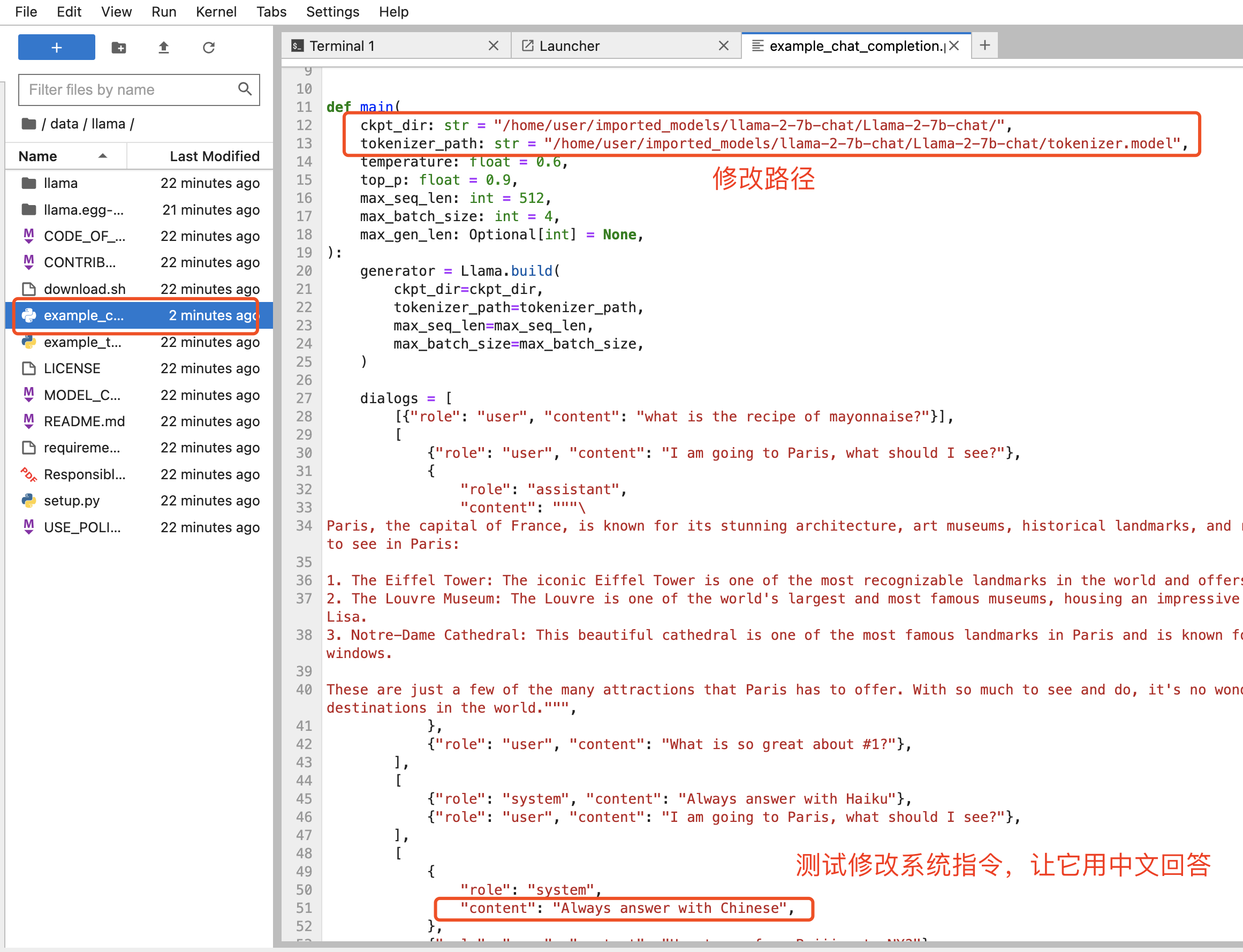
这里我修改提示语让它用中文回答,执行对话脚本后,对话效果如下:
torchrun --nproc_per_node 1 example_chat_completion.py

说明:目前官方还没有提供UI界面或是API脚本代码给咱使用,还没法进行对话交互,如果有懂python的友友,可以自行加个UI界面,欢迎大家留言讨论。
4.下载更多模型
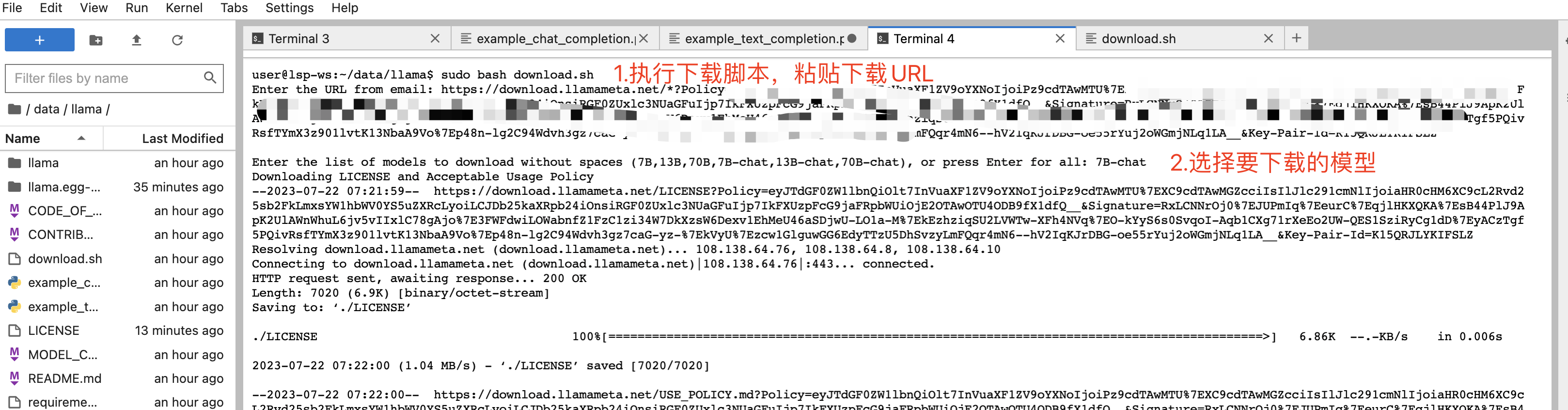
llama代码里有download.sh脚本可以下载其他模型,但是下载需要的URL需要自行获取。下载步骤如下:
1.Meta AI网站获取下载URL
MetaAI下载模型页地址:https://ai.meta.com/llama/#download-the-model

点击Download后,要求填入一些信息和邮箱,提交后会给你的邮箱发一个下载URL,注意这个是你自己的下载链接哦~
下图是小卷邮箱里收到的模型下载链接
2.下载模型
服务器上命令行执行
sudo bash download.sh
接着按照提示粘贴下载URL和选择要下载的模型
总结
对于国内大模型使用来说,随着开源可商用的模型越来越多,国内大模型肯定会再次迎来发展机遇。
文章原创不易,欢迎多多转发,点赞,关注
也欢迎关注我卷福同学,技术问题都可在公众号内交流

