一、提出原因
使用(image-text pairs)图像-文本对数据的对比语言图像预训练模型(Contrastive language-image pretraining,CLIP)在图像分类方面的zero-shot和迁移学习的取得了非常好的结果。但是,直接应用CLIP这样的模型来进行图像区域推理(如目标检测)效果将会不好。主要原因:CLIP只是进行图像整体与文本描述匹配,而不能捕获图像区域(image regions)与其对应文本之间的细粒度对齐(fine-grained alignment)。也就是CLIP建立的是image-text pair的匹配,并没有对图像里某个目标/对象进行文字描述的匹配,也并不能准确定位图片上的区域。
二、目的
因此,RegionCLIP的目的便是实现从image-text pairs的匹配到region-text pairs的匹配。构建一个模型进行图像区域的推理研究(如目标检测),目的是学习一个包含丰富的对象概念的区域视觉-语义空间,以便它可以用于开放词汇的目标检测。实质上就是训练一个视觉编码器V,使它可以编码图像区域,并将它们与语言编码器L编码的区域描述相匹配。

上图主要是说明CLIP模型在图像区域的分类效果不好,而该作者的核心想法便是进行一个图像区域与其对应的文本描述的学习。
三、思想方法
从图像描述的文本语料中解析的对象概念,并这些概念填充到预定义的模板中来形成图像区域描述(prompt templates操作)。根据输入图像及其生成的候选区域(如RPN来生成),使用一个预先训练好的CLIP模型来进行图像区域与其区域描述的匹配,形成了region-text pairs数据,即为图像区域创建相应的“伪”标签。此外,我们结合“伪”图像区域-文本描述对(“pseudo” region-text pairs)和真实的图像-文本对(ground-truth image-text pairs),通过对比学习和知识精馏对我们的视觉语言模型(VLP)进行预训练,从而学习region representations。
四、具体步骤
4.1 符号说明
$V_t$表示CLIP的Visual encoder,$L$表示CLIP的Language encoder,$V$表示自己(RegionCLIP)的Visual encoder。
主要方法就是,先利用CLIP预训练模型进行图像与文本描述的匹配(Image-text pretraining),从而训练一个Visual encoder $V_t$和Language encoder $L$,然后,进行region-text pretraining,将$V_t$作为teacher model,$V$作为student model,利用知识蒸馏(Knowledge Distillation,KD)的方法,将$V_t$学到的知识提取到$V$,而Language encoder $L$在image-text pretraining与region-text pretraining,始终保持一致。
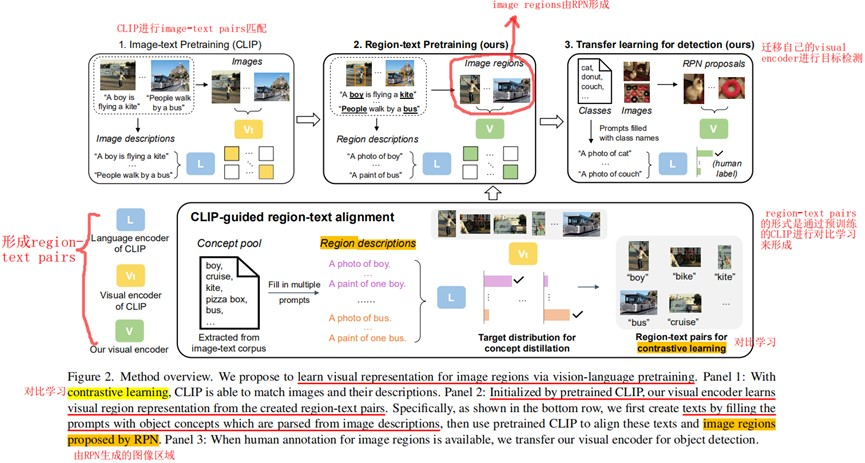
4.2 Image-text pretraining(CLIP)
即利用CLIP预训练一个image-text level的Visual encoder $V_t$和Language encoder $L$。
4.3 Region-text pretraining
首先是region-text pairs的生成,这里又分为Visual region representation和Semantic region representation。
4.3.1 Visual region representation
关于visual region representation的表达,文中指出将目标检测任务分解为定位与识别。
首先利用现成的目标定位器(off-the-shelf object localizers,如RPN)生成一些候选区域$r$(proposed regions),(实际上,默认使用了只带bounding boxes标签,不带分类标签进行RPN的预训练),因此,这里便是使用RPN进行图像区域的定位的操作。
将由RPN形成的候选区域$r$(proposed regions)经过visual encoder $V_t$ 进行Visual region representation(这里通过了特征池化feature pooling(如RoIAlign)的方法对RPN形成的候选区域的特征进行池化),形成每个候选区域$r$对应Visual 特征$v$。
4.3.2 Semantic region representation
Semantic region representation的实现相对来说更为容易一些,文中指出,利用现成的语言解析器(off-the-shelf language parsers)从文本语料库(text corpus,指的就是对图片的描述文本)提取出有关目标/对象的词库(a pool of object concepts,感觉就是提出图像中对象的名称,图片有猫,就将图片对应文本描述中cat这个词提取出来).然后将这个object concepts pool转化为prompt templates,(比如:cat-->a photo of a cat),就相当于从对图像的描述转化为了对图像区域的更细节的描述。
然后利用第一步CLIP训练好的language encoder $L$ 来进行 Semantic region representation(感觉就是word embedding,转化为向量)形成对应的semantic embeddings $l$。
4.3.3 Alignment of region-text pairs
通过对前面visual encoder与language encoder分别形成的regions feature $v$ 和 semantic embeddings $l$ 计算其之间的余弦相似度(内积)进行一个匹配,选择对应相似度最高的作为一个region-text pair。这样就为每一个图像区域生成了一个伪标签(pseudo label for each region):
$$ S(v,l)=\frac{v^T\cdot l}{||v||\cdot ||l||} $$
4.3.4 Pretraining scheme
形成region-text pairs数据后联合现存的image-text pairs均使用,就可以开始自己的visual encoder $V$ 的预训练来进行visual region representation。(值得注意的是visual encoder $V$ 是经由teacher visual encoder $V_t$ 来初始化的),文中设计对比损失和蒸馏损失(contrastive and a distillation loss)。
$$ L_{cntrst}=\frac{1}{N}\sum_i-\log(p(v_i,l_m)) $$
其中:
$$ p(v_i,l_m)=\frac{\exp(S(v_i,l_m)/T)}{\exp(S(v_i,l_m)/T)+\sum_{k\in N_{r_i}}\exp(S(v_i,l_k)/T)} $$

考虑到之前设计的contrastive loss是针对region-level的,而在训练过程中使用了image-text pairs数据,因此,还应该设计image-level contrastive loss,对于image就直接当作由一个框覆盖了所有的区域(不管里面有多少对象)即可。

论文后面就是使用RegionCLIP进行一些相关实验(迁移到Open-Vocabulary Object Detection和Fully Supervised Object Detection、Zero-shot Inference for Object Detection以及一些消融对比实验),还没有继续仔细看。

