串(String)的定义与实现
串的定义
串(即字符串)是一种特殊的线性表,它的数据元素仅有字符组成。
串:是由零个或多个字符组成的有限序列。一般记为:
$$ S = "a_0a_1 \cdots a_{n - 1}"(n \ge 0) $$
其中。$S$是串名,单引号括起来的字符序列是串的值;$a_i$可以是字母、数字或其他字符;串中字符的个数$n$称为串的长度。$n = 0$时的串称为空串(用$\varnothing$表示),不包含任何字符。在C语言中,串一般使用不可显示的字符"\0"作为串的结束符。
子串:串中任意多个连续的字符组成的子序列称为该串的子串。
主串:包含子串的串称为主串。
子串的第一个字符在主串中的序号,定义为子串在主串中的位置,该位置索引(或序号)从0开始。特别的:空串是任何串的子串,任意串是其自身的子串。
串与线性表的区别
- 串的逻辑结构与线性表极为相似,区别仅在于串的数据对象约束为字符集。
- 串的基本操作和线性表有很大差别。
- 在线性表中,大多以“单个元素”作为操作对象。
- 在串中,通常以“串的整体”(子串)作为操作对象。
串的基本操作
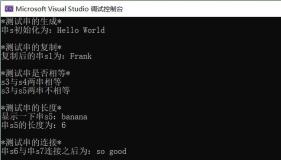
- StrCopy(&Str1, Str2):复制操作,将串Str2的值赋给串变量Str1。
- StrConcat(&Str1, Str2):串连接,将串Str2接在Str1末尾,组成一个新串Str1。
- StrLength(Str):求串长,返回串Str的元素个数。
- SubString(&Sub, Str, index, len):求子串,表示从Str中index位置的字符开始抽出len个字符构成一个新的串用Sub串返回。
- StrCompare(Str1, Str2):比较操作,比较串的编码,从串的一个序号开始比较其编码,若为0比较下一个序号,直到非0或比较完毕。若返回值大于0,表示Str1 > Str2;返回值等于0,表示Str1 = Str2;返回值小于0,表示Str1 < Str2。
- StrInsert(Str1, Str2, index):插入子串,表示把串Str2插入到Str1的index位置处。
- StrDelete(Str, index, len):删除子串,表示删除Str串的index位置及以后的的连续共len个字符。
- StrIndex(Str1, Str2):子串定位,若主串Str1中存在子串Str2,则返回主串中子串的起始位置,否则返回-1。
串的存储结构
定长顺序存储
串的顺序存储结构简称顺序串。顺序串的字符被依次存放在一片连续的单元中。我们可以用一个特定的、不会出现在串中的字符作为串的终结符,放在串的尾部,表示结束。在C语言中用字符"\0"作为串的结束符。
```C
// 顺序串的最大长度define MaxSize 255
typedef struct {
// 数据域
char ch[MaxSize];
// 串的长度
int len;
} SeqString;
### 堆分配存储表示
堆分配存储仍然使用一组连续的存储单元存放串值的字符序列,但是它们的存储空间实在执行过程中动态分配的。
```C
typedef struct {
// 数据域,动态分配存储空间ch的地址为串的基地址
char *ch;
// 串的长度
int len;
} HeapString;
C语言中,存在一个称为“堆”的自由存储区,并用molloc()和free()函数来动态存储管理。
链式存储表示
串的链式存储结构简称为链串。
typedef struct Node{
char data;
struct Node *next;
} LinkString;
索引存储
在索引存储中,除了存放串值外,还要建立一个串名和串值之间对应关系的索引表
带长度的索引表
#define MaxSize 255
typedef struct{
// 串名
char name[MaxSize];
// 串长
int len;
// 串值基地址
char *strAdr;
} LinkString;
带末指针的索引表
带末指针的索引表用存放的末地址的指针endAdr来代替长度len
#define MaxSize 255
typedef struct{
// 串名
char name[MaxSize];
// 串值基地址,末指针
char *strAdr, *endAdr;
} LinkString;
串的基本运算
串的连接运算
/**
* 串连接,将Str2连接在Str1并赋值给Str1
* @param Str1
* @param Str2
*/
void StrConcat(SeqString *Str1, SeqString Str2) {
if (Str1->len + Str2.len > MaxSize) {
// 判断两个串连接后是否溢出
printf("上溢");
} else {
// 将Str2接在Str1后
for (int i = 0; i < Str2.len; i++) {
Str1->ch[Str1->len + i] = Str2.ch[i];
}
// 重置Str1长度和结束符
Str1->len = Str1->len + Str2.len;
Str1->ch[Str1->len] = '\0';
}
}
求子串运算
/**
* 求子串
* @param Sub 子串,传入传出参数
* @param Str 主串
* @param index 子串在主串的下标号
* @param len 子串长度
*/
void SubString(SeqString *Sub, SeqString Str, int index, int len) {
if ((index + len - 1) > Str.len) {
printf("超界");
} else {
for (int i = 0; i < len; i++) {
Sub->ch[i] = Str.ch[i + index];
}
// 重置Str1长度和结束符
Sub->len = len;
Sub->ch[Sub->len] = '\0';
}
}
串的模式匹配(子串定位)
子串定位运算又称为串的模式匹配,是串处理中最重要的运算之一。
设有两个串S和T,$S = "s_0s_1 \cdots s_{n - 1}"$,$T = "t_0t_1 \cdots t_{m - 1}"$,其中$0 < m \le n$。子串定位是在主串S中找出和子串T相同的子串。
一般把主串S称为目标;把子串T称为模式;把从目标S中查找模式为T的子串的过程称为模式匹配。
朴素的模式匹配(BF算法)
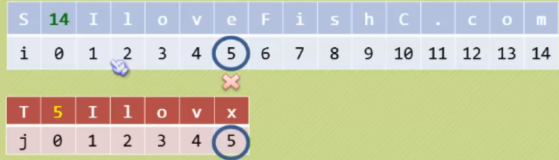
朴素的模式匹配思想:从目标S中的第一个字符开始和模式T中的第一个字符比较,若相等,则继续逐个比较后续字符,否则从目标S的第二个字符开始重新与模式串的第一个字符比较,依次类推,直到模式T中的每个字符依次和目标S中的一个连续字符序列相等为止,则匹配成功,返回模式T中第一个字符在目标S中的位置。否则匹配失败,返回-1。
朴素模式匹配算法是一种不依赖于其他串的暴力匹配算法。
/**
* 朴素模式匹配算法
* @param Str1 主串
* @param Str2 子串
* @return
*/
int SimpleIndex(SeqString Str1, SeqString Str2) {
// i:控制主串下标,j:控制子串下标
int i = 0, j = 0;
// 因为i和j都是下标,所以必不小于对应的串长度
while (i < Str1.len && j < Str2.len) {
// 比较字符
if (Str1.ch[i] == Str2.ch[j]) {
// 相等,比较下一个字符
i++;
j++;
} else {
// 不想等,此时j表示本次匹配,匹配了j个字符,那i - j则主串下标回到本次子串还未开始匹配的位置
// 令其加1,从下一个字符重新开始子串匹配,所以i = i - j + 1
i = i - j + 1;
// 子串回到其第一个字符下标处重新匹配
j = 0;
}
}
// 若此时j即子串的下标等于子串的长度,即为子串匹配成功,否则是主串遍历所以字符仍未找到对应子串
if (j == Str2.len) {
// 此时i的值对应的是匹配串后的一个位置,i - 子串长度Str2.len即为子串在主串中的索引号
return i - Str2.len;
} else {
return -1;
}
}
- 朴素匹配算法的最好平均时间复杂度为:$O(n + m)$。
- 朴素匹配算法的最坏平均时间复杂度为:$O(nm)$。
KMP模式匹配算法
在朴素匹配算法中,每次回溯都会回到比较字符的下一个位置,即回溯$i$值,这其中的大部分回溯都是不必要的。
KMP算法相比朴素匹配算法的改进之处在于:每当一趟匹配过程中出现字符比较不相等时,不需回溯$i$值,而是利用已经得到的“部分匹配”的结果将模式向右“滑动”尽可能远的一段距离后,再进行比较。字符串的前缀、后缀和部分匹配值
要了解子串的结构,首先要弄清:前缀、后缀和部分匹配值等概念。
前缀:除最后一个字符外,字符串的所有头部字符。
后缀:除第一个字符外,字符串的所有尾部字符。
部分匹配值:字符串的前缀和后缀的最长相等前后缀长度。
下面以“ababa”为例进行说明:
| 模式串的各子串 | 前缀 | 后缀 | 交集 |部分匹配值 |
| --- | --- | --- | --- | --- |
| a | $\varnothing$ | $\varnothing$ | $\varnothing$ | 0 |
| ab | a | b | $\varnothing$ | 0 |
| aba | a, ab | a, ba | a | 0 |
| abab | a, ab, aba | b, ab, bab | ab | 2 |
|ababa | a, ab, aba, abab | a, ba, aba, baba | a, aba | 3 |next数组求法
next数组本质上就是模式串$i$前面的子串部分匹配值(有点教材里面是部分匹配值 + 1)。
next数组的开始两个为固定值==next[0] = 0; next[1] = 1;== 或者 ==next[0] = -1; next[1] = 0==
下面以等于部分匹配值为例给出next函数定义(next[0] = -1; next[1] = 0):
$$ y(x)=\left\{ \begin{aligned} -1 && j = 0 \\ max\{k |0 < k < j,且使得t_0t_1 \cdots t_{k - 1} = t_{j - k} \cdots t_{j - 1} \} && 当此集合不空时 \\ 0 && 其他情况 \end{aligned} \right . $$
对于next[0] = 0; next[1] = 1;的情况,只需将对应值加1即可。
下面以具体示例来更好演示求模式串的next值(这里以两种方法穿插求解next值,一种是通过求解前缀后缀后求其交集来求解next(根据next值本质来求),一种是通过前缀后缀的性质来求解。)。
计算$T = "abaabcac"$的next值:
0:固定给next[0]赋值为-1;
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | ? | ? | ? | ? | ? | ? | ? |
1:下标为1对应求解的子串为a,a的前缀和后缀皆为空,对应的部分匹配值为0,所有next[1] = 0
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | ? | ? | ? | ? | ? | ? |
2:下标为2对应求解的子串为ab,去掉头字符后为b,因为头字符为a,所以对应匹配的后缀必以a开头,所以b不是其后缀,所有next[2] = 0
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | ? | ? | ? | ? | ? |
3:下标为3对应求解的子串为aba,aba的前缀为{a, ab},后缀为{a, ba},交集为{a},对应的部分匹配值为1,所有next[3] = 1
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | 1 | ? | ? | ? | ? |
4:下标为4对应求解的子串为abaa,去掉头字符后为baa,因为头字符为a,所以匹配后缀必以a开头,baa不可能是其匹配后缀。使用aa从头字符开始对比两个字符为ab,aa != ab,所以aa不是匹配后缀;使用a和头字符对比,对比成功,长度为1,所有next[4] = 1
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | 1 | 1 | ? | ? | ? |
5:下标为5对应求解的子串为abaab,去掉头字符后为baab,因为头字符为a,所以匹配后缀必以a开头,baab不可能是其匹配后缀。使用aab从头字符开始对比三个字符为aba,aab != aba,所以aab不是匹配后缀;使用ab和头字符对比两个字符为ab,对比成功,长度为2,所有next[5] = 2
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | 1 | 1 | 2 | ? | ? |
6:下标为6对应求解的子串为abaabc,abaabc的前缀为{a, ab, aba, abaa, abaab},后缀为{c, bc, abc, aabc, baabc},交集为{},对应的部分匹配值为,所有next[6] = 0
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | 1 | 1 | 2 | 0 | ? |
7:下标为6对应求解的子串为abaabca,abaabc的前缀为{a, ab, aba, abaa, abaab, abaabca},后缀为{a, ca, bca, abca, aabca, baabca},交集为{a},对应的部分匹配值为1,所有next[7] = 1
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模式 | a | b | a | a | b | c | a | c |
|next[j] | -1 | 0 | 0 | 1 | 1 | 2 | 0 | 1 |
next数组代码求解
/**
* 求取next数组
* @param Str 模式串
* @param next next数组
*/
void GetNext(SeqString Str, int next[]) {
int i = 0, j = -1;
next[0] = -1;
while (i < Str.len) {
if (j == -1 || Str.ch[i] == Str.ch[j]) {
++i;
++j;
next[i] = j;
} else {
j = next[j];
}
}
}
KMP算法的代码
KMP算法的代码和朴素模式匹配算法代码基本类似,主要区别在于回溯的移动的区别。
/**
* kmp模式匹配算法
* @param Str1
* @param Str2
* @return
*/
int KmpIndex(SeqString Str1, SeqString Str2) {
// 求解next数组
int next[Str2.len];
GetNext(Str2, next);
// i:控制主串下标,j:控制子串下标
int i = 0, j = 0;
// 因为i和j都是下标,所以必不小于对应的串长度
while (i < Str1.len && j < Str2.len) {
// 比较字符
if ((-1 == j) || (Str1.ch[i] == Str2.ch[j])) {
// 相等,比较下一个字符
i++;
j++;
} else {
// 不想等,根据next数组将模式串向右移动
j = next[j];
}
}
// 若此时j即子串的下标等于子串的长度,即为子串匹配成功,否则是主串遍历所以字符仍未找到对应子串
if (j == Str2.len) {
// 此时i的值对应的是匹配串后的一个位置,i - 子串长度Str2.len即为子串在主串中的索引号
return i - Str2.len;
} else {
return -1;
}
}
KMP算法的时间复杂度为$O(m + n)$。KMP算法只是在主串和子串有很多“部分匹配”是才明显由于朴素算法。
KMP算法的主要优点是:主串不回溯。