核心API
估计器 fit()
任何可以基于数据集对一些参数进行估计的对象都被称为估计器
两个核心点:1.需要输入数据,2.可以估计参数。估计器首先被创建,然后被拟合。
预测器 predict() | score()
预测器在估计器上延展出预测功能
两个核心点:1.基于学到的参数预测,2.预测有很多指标。最常见的就是predict()函数
model.predict(X_test):评估模型在新数据上的表现
model.predict(X_train):确定模型在老数据上的表现
装换器
装换器也是一种估计器,两者都带有拟合功能,但估计器做完拟合来预测,而装换器做完拟合来装换
核心点:估计器里fit+predict,装换器里先创建再fit+再transform
警示: fit() 函数只能作用在训练集上,千万不要作用在测试集上,要不然你就犯了数据窥探的错误了!拿标准化举例,用训练集 fit 出来的均值和标准差参数,来对测试集做标准化。
分类:
1.将分类型变量编码成数值型变量
2.规范化或标准化数值型变量
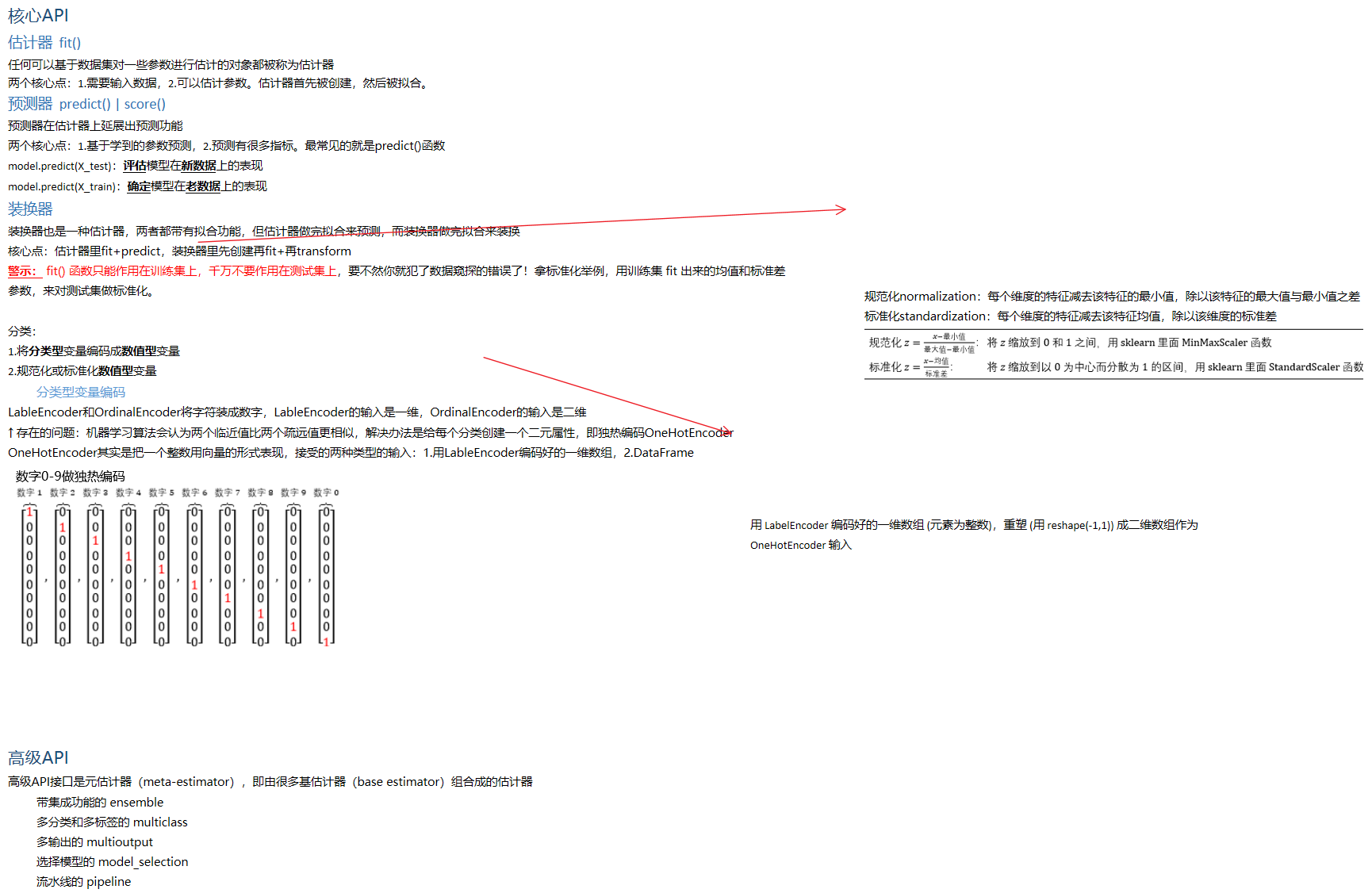
分类型变量编码
LableEncoder和OrdinalEncoder将字符装成数字,LableEncoder的输入是一维,OrdinalEncoder的输入是二维
↑ 存在的问题:机器学习算法会认为两个临近值比两个疏远值更相似,解决办法是给每个分类创建一个二元属性,即独热编码OneHotEncoder
OneHotEncoder其实是把一个整数用向量的形式表现,接受的两种类型的输入:1.用LableEncoder编码好的一维数组,2.DataFrame
规范化normalization:每个维度的特征减去该特征的最小值,除以该特征的最大值与最小值之差
标准化standardization:每个维度的特征减去该特征均值,除以该维度的标准差
用 LabelEncoder 编码好的一维数组 (元素为整数),重塑 (用 reshape(-1,1)) 成二维数组作为 OneHotEncoder 输入
高级API
高级API接口是元估计器(meta-estimator),即由很多基估计器(base estimator)组合成的估计器
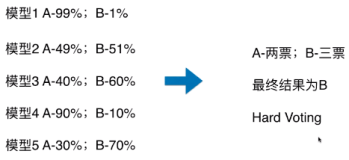
带集成功能的 ensemble
多分类和多标签的 multiclass
多输出的 multioutput
选择模型的 model_selection
流水线的 pipeline