据《中国居民营养与慢性病状况报告(2020 年)》显示,2019 年我国因慢性病导致死亡占总死亡的 88.5%,可见,慢性病已成为威胁人类健康的一大「杀手」。以慢性病中被学者们称为「人类最糟糕疾病」的精神分裂症为例,患者要想完全康复,就需要进行较长时间的维持治疗。但这期间,患者服药可能由于各种原因中断,从而造成复发。
为解决慢性病人服药依从性差的情况,长效注射剂问世,该药是将足够剂量的药物溶解于某种制剂中,通过注射途径进入体内形成小型药物「储存仓库」,再在体内缓慢释放药物,起到稳定的治疗作用。与传统药物相比,长效注射剂有给药间隔长、作用迅速、药物剂量稳定等优点。
但另一方面,这种新型药物的研发也颇具挑战,比如,为了令药物在规定时间范围内在体内达到最佳释放量,就需对多种候选制剂进行大量、广泛实验。此过程繁琐且耗时长,成为长效注射剂进一步发展的瓶颈。
近期,来自多伦多大学 (University of Toronto) 的研究人员开发了一个机器学习模型,相关实验成果显示该模型能准确预测长效注射剂药物释放速率,有效加速长效注射剂研发。目前该研究已发布在《Nature Communications》期刊上,标题为「Machine learning models to accelerate the design of polymeric long-acting injectables」。
 目前该成果已发布在《Nature Communications》
目前该成果已发布在《Nature Communications》
论文地址:
https://www.nature.com/articles/s41467-022-35343-w#Abs1
实验概述
长效注射剂制剂种类多样,一般是脂类和合成聚合物。下图展示了传统和数据驱动的长效注射剂制剂研发方法对比。
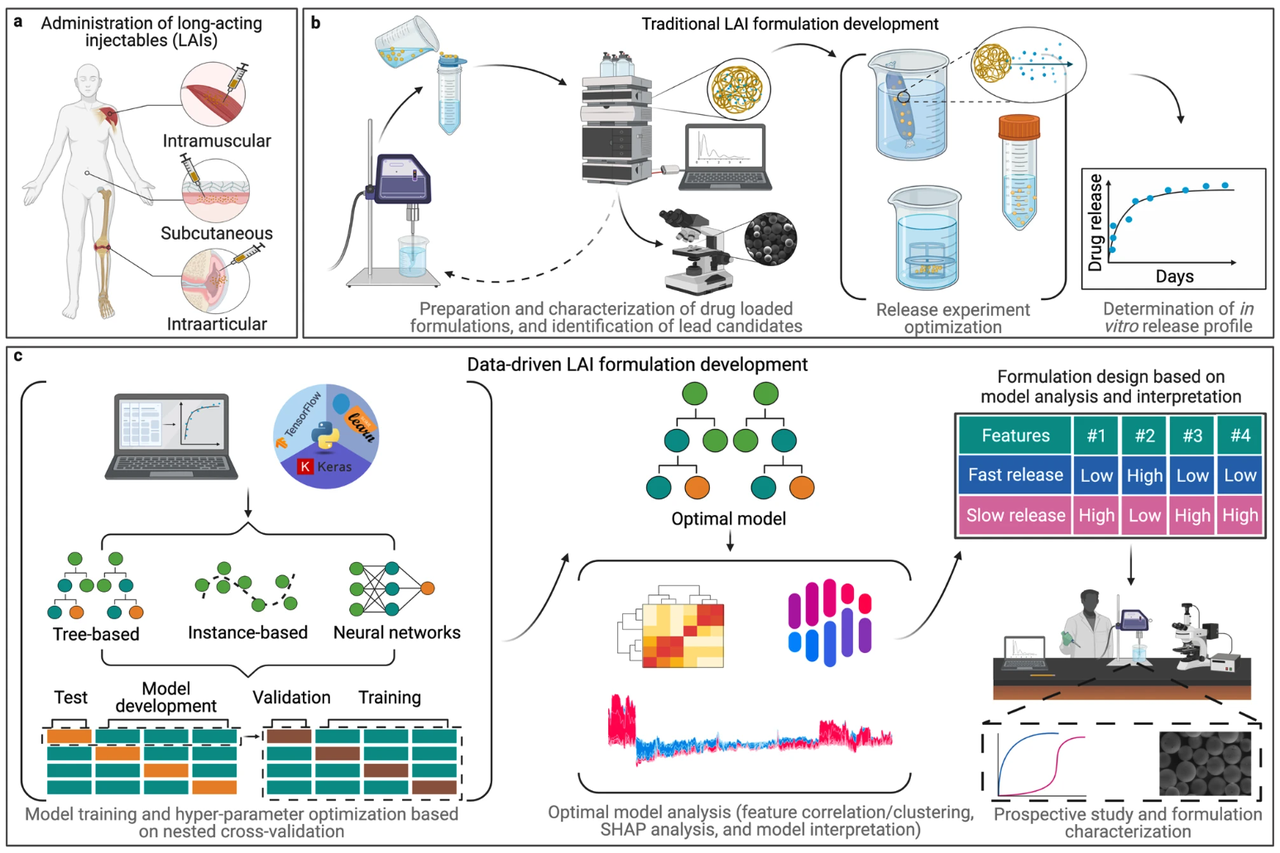 图1:传统和数据驱动的长效注射剂制剂研发方法示意图
图1:传统和数据驱动的长效注射剂制剂研发方法示意图
a 图:美国食品及药物管理局批准的长效注射剂制剂给药途径。
b 图:传统长效注射剂制剂研发的典型试错循环。
c 图:本研究的工作流程概览,即用训练好的机器学习模型加速长效注射剂制剂研发过程。
本实验数据集由先前发表的研究成果构建,同时还添加了由 Web of Science 引擎中搜索出来的外部来源数据。具体来看,数据集包括了 181 种药物及 43 种药物-聚合物组合释放量(给定时间内释放的药物分子数量)。同时,研究人员将构建好的数据集分为两个子集,分别用于模型训练和测试。
长效注射剂数据集
发布机构:多伦多大学
包含数量:181 种药物和 43 种药物-聚合物组合释放量
预估大小:394.1 KB
发布时间:2022 年
下载地址:hyper.ai/datasets/23625**
实验过程
本项研究中,研究人员共训练了 11 种机器学习算法,包括多元线性回归 (MLR)、最小绝对值收缩和选择算子 (Lasso)、偏最小二乘回归 (PLS)、决策树 (DT)、随机森林 (RF)、光梯度增强机 (LGBM)、极端梯度增强 (XGB)、自然梯度增强 (NGB)、支持向量回归 (SVR)、 k 最近邻算法 (k-NN) 以及神经网络 (NN)。
模型选择
为了评估这些机器学习模型的预测性能,研究人员采用了嵌套交叉验证的方法,该方法包括内部(训练和验证)和外部(测试)循环两部分。具体过程为,研究人员先将数据集按照药物-聚合物组合进行分组,再分别对每个机器学习模型进行 10 次嵌套交叉验证实验。
最终,各个机器学习模型在内部和外部嵌套交叉验证循环中的预测性能总结如下表 1 和图 2 所示。表 1 为嵌套交叉验证 (n=10) 中,使用不同机器学习算法预测药物释放后得到的平均绝对误差 (MAE) 值以及平均标准误差 (σM,括号内显示)。从表中可以看到,基于树 (tree-based) 的机器模型整体上要比线性、基于实例和深度学习的模型更加准确 (MAE<0.16)。

表1:各机器学习模型嵌套交叉验证中预测性能情况
图2为嵌套交叉验证 (n=10) 中获得的药物释放预测量的绝对误差 (AE) 值。结合表 1 和图 1 的信息,基于 LGBM 的模型在内部和外部循环中 MAE 值以及 AE 值均为 11 个模型中最小。因此,研究人员认为基于 LGBM 的模型是预测性能最好的模型。
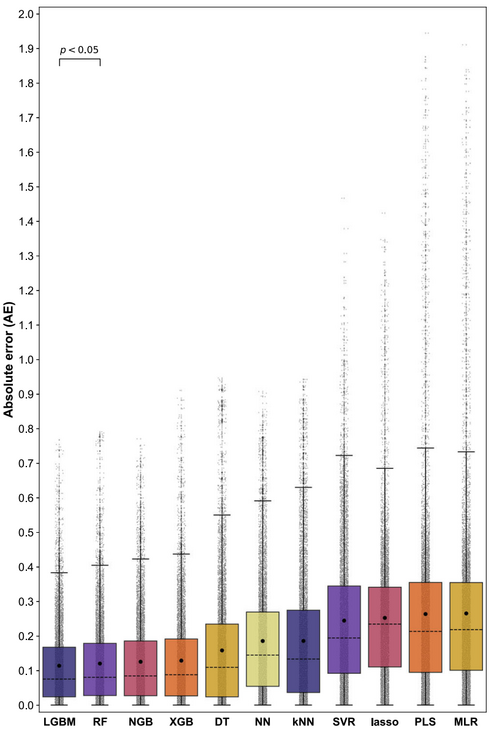
图 2:各算法模型整体预测性能情况
图中方框内的黑色圆圈和黑色虚线分别代表每个模型的 MAE 值和 AE 值。
模型优化
为了进一步提高机器学习模型的泛化能力,研究人员又通过聚类分析对 17 个特征的 LGBM 模型进行了优化、改进。
这里他们采用了最远邻聚类算法 (farthest neighbor clustering algorithm),如下图所示,将输入特征排列成一个层次结构,研究人员发现 17 个特征中存在冗余。经过改进后,最终确定 15 个特征的 LGBM 模型表现最优。

图 3:初始17个输入特征的Spearman相关系数热力图
深蓝色表示绝对 Spearman 相关系数 (根据等级资料研究两变量间相关关系的方法) 为 1,粉色表示绝对 Spearman 相关系数为 0。热力图旁边附有一个树形图,显示通过聚合层次聚类分析确定的特征集群的层次结构。
实验结果
得到上述最优模型后,研究人员进行了两项测试,其一是使用该模型预测某一种长效注射剂药物释放曲线,其二是使用该模型预测测试集中药物-聚合物的药物释放曲线,并将得到的结果分别与实验药物释放曲线进行比较,结果如下图所示。
图 4 显示了某种所选长效注射剂的预测和实验药物释放曲线的比较,图 5 则显示了药物-聚合物的药物释放曲线和实验药物释放曲线比较,可以看到在两种情况下,预测值和实验值均基本一致,因此,研究人员认为基于 LGBM 算法的模型能够准确预测长效注射剂药物释放速率。

图 4:数据集中长效注射剂预测和实验药物释放曲线对比

图 5:药物-聚合物预测和相应实验药物释放曲线对比
加速联盟:助力科研新范式落地
值得注意的是,本研究成果的作者 Christine Allen 以及 Alán Aspuru-Guzik 都来自加速联盟 (The Acceleration Consortium,AC)。加速联盟诞生于 2021 年,是学术界、工业界和政府之间的一项新的全球性合作,总部位于加拿大多伦多大学,其愿景是利用 AI 和机器人技术加速发现和设计新材料和分子。
「我们的目标是加速科学发展,」加速联盟主任 Alán Aspuru-Guzik 称,「为了实现这一目标,我们意识到可以将汽车自动驾驶的思路扩展到自动化实验室,利用 AI 和自动化技术用更智能的方式进行实验。

图 6:加速联盟,一位科学家从自动固体分配机器人中取出预先分配好的试剂
值得关注的是,就在上个月加速联盟刚刚获得了加拿大首席研究卓越基金 (Canada First Research Excellence Fund,CFREF) 2 亿美元的拨款,该笔拨款将用于支持联盟「自动驾驶实验室」(self-driving labs) 领域的相关工作。对此,多伦多大学校长 Meric Gertler 谈道,「这些对 AI 驱动研究和创新方面的重大投资,有望改善加拿大乃至全世界人民的生活」。