▏开源工业级Paraformer非自回归端到端语音识别模型
我们在ModelScope上开放了阿里工业级的语音识别模型,涉及不同的模型结构(UniASR,Paraformer),不同的模型大小(small,large),不同的语种(中文,英文,中英自由说,日语,俄语,印尼语等)。
以Paraformer为例,本文将介绍其原理,以及如何体验和定制化训练自己的Paraformer模型。(本文介绍的模型在modelscope中名称为Paraformer-large,可在官网直接搜索)。
1. Paraformer基础原理
2. 为什么选择Paraformer?
大模型
开源的Paraformer-large模型相对论文中的学术Paraformer模型采用了更深更大的模型结构。Paraformer-large模型的Encoder有50层,包括memory equipped self-attention(SAN-M)和feed-forward networks (FFN)。Decoder有16层,包括SAN-M,FFN和multi-head attention(MHA)。
大数据
相对于公开论文中在单独封闭数据集(AISHELL-1、AISHELL-2等)上进行的效果验证,我们使用了更大数据量的工业数据上对模型进行训练,利用数万小时16K通用数据,包括半远场、输入法、音视频、直播、会议等领域。并在微调实验中,使用AISHELL-1、AISHELL-2单独数据集对模型进行finetune。
高效率
Paraformer采用非自回归结构,配合GPU推理,可以将推理效率提升5~10倍。同时使用了6倍下采样的低帧率建模方案,可以将计算量降低接近6倍,支持大模型的高效推理。
高性能
Paraformer-large模型在主流的中文语音识别任务中的识别准确率均远超于公开发表论文中的结果,同时具备工业落地的能力,在工业大数据上取得了与阿里云公有云上文件转写服务相当的效果。
3. Paraformer的效果
我们提出的Paraformer模型在一系列语音识别任务上进行了实验,以验证其性能优越性,其中包括学术数据集AISHELL-1、AISHELL-2、WenetSpeech,以及第三方评测项目SpeechIO TIOBE白盒测试集。 在学术界常用的中文识别评测任务AISHELL-1上,我们提出的Paraformer在目前公开发表论文中,为性能(识别效果&计算复杂度)最优的非自回归模型,且Paraformer-large模型的识别准确率远远超于目前公开发表论文中的结果(dev/test:1.75/1.95)。同时,Paraformer是首个能够在工业大数据上获得与自回归模型相当识别率的非自回归模型,Paraformer-large模型在工业界的第三方评测SpeechIO TIOBE白盒测试场景中也取得了最优的性能。
公开数据集
①AISHELL-1
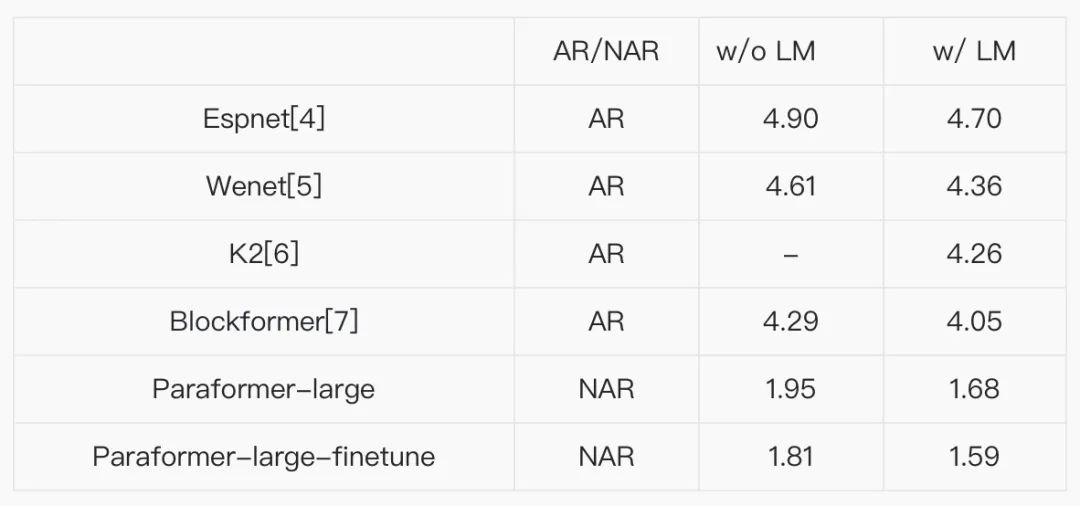
表一. Paraformer模型在AISHELL-1上的表现②AISHELL-2

表二. Paraformer模型在AISHELL-2上的表现③WenetSpeech
表三. Paraformer模型在WenetSpeech上的表现

表四. Paraformer模型的RTF性能(AISHELL-1)表一、表二和表三中分别展现了Paraformer-large模型在AISHELL-1、AISHELL-2和WenetSpeech测试集上的效果,其表现远远超于目前公开发表论文中的结果,远好于使用单独封闭数据集训练的模型。从测试结果可以看到,大数据对于语音识别系统性能的重要性。在AISHELL-1公开数据集上,我们进行了finetune效果验证,单独使用AISHELL-1数据对Paraformer-large进行微调,在test集上分别取得了7.2%的效果提升,后续在AISHELL-1及AISHELL-2数据集上finetune实验结果及代码也将进行开源。
SpeechIO TIOBE

表五. Paraformer-large模型与各厂商在SpeechIO白盒测试集的效果对比
表五中展现了Paraformer-large模型与各家厂商语音服务的对比结果。可以看到在无LM的情况下,Paraformer-large模型取得了白盒测试场景榜单第二的成绩,接近喜马拉雅CER 2.16的成绩,在加入TransformerLM进行shallow fusion解码后取得了榜单第一的成绩。
*注:各厂商服务测试结果,为SpeechIO滚动测试报:2022年8月期公布结果,https://mp.weixin.qq.com/s/f8MU3CxHH3lsn5DmDNe1mw。
▏如何快速体验模型效果?
1.在线体验
您可以在ModelScope官网,进入模型主页(复制该链接在浏览器中打开:https://www.modelscope.cn/models/damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary),在页面右侧,可以在“在线体验”栏内看到我们预先准备好的示例音频,点击播放按钮可以试听,点击“执行测试”按钮,推理完成后会在下方“测试结果”栏中显示识别结果。如果您想要测试自己的音频,可点击“更换音频”按钮,选择上传或录制一段音频,完成后点击执行测试,识别内容将会在测试结果栏中显示。具体使用方法请参考视频演示:
,时长00:26
2.在Notebook中开发
对于有开发需求的使用者,特别推荐您使用Notebook进行离线处理。先登录ModelScope账号,点击模型页面右上角的“在Notebook中打开”按钮出现对话框,首次使用会提示您关联阿里云账号,按提示操作即可。关联账号后可进入选择启动实例界面,选择计算资源,建立实例,待实例创建完成后进入开发环境,输入api调用实例。具体使用方法请参考视频演示:
,时长01:56
api调用方式可参考如下范例:from modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasks inference_16k_pipline = pipeline( task=Tasks.auto_speech_recognition, model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch') rec_result = inference_16k_pipline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav')print(rec_result)
若输入音频为pcm格式,调用api时需要传入音频采样率参数audio_fs,例如:
rec_result = inference_16k_pipline(audio_in='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.pcm', audio_fs=16000)
▏如何训练自有的Paraformer语音识别模型?
本文介绍的Paraformer是基于大数据训练的通用领域的识别模型,开发者可以基于此模型进一步利用本项目对应的Github代码仓库进一步进行模型的领域定制化。
1.如何基于开源模型训练自有模型
FunASR框架支持魔搭社区开源的工业级的语音识别模型(Paraformer-large)的training & finetuning,使得研究人员和开发者可以更加便捷的进行语音识别模型的研究和生产,目前已在Github开源:https://github.com/alibaba-damo-academy/FunASR。
目前FunASR框架已支持:
- Paraformer-large模型ModelScope下载
- Paraformer-large模型在AISHELL-1、AISHELL-2数据集上微调并推理
- Paraformer-large模型在AISHELL-1、AISHELL-2、WenetSpeech、SpeechIO白盒场景推理
- Paraformer-large模型使用自有数据微调并推理
接下来我们以FunASR框架的egs_modelscope/common为例,介绍如何使用小规模自有语料在Paraformer-large模型上进行领域定制化训练,并体验产出的模型效果。
环境搭建
- 安装FunASR框架
# Clone the repo:git clone https://github.com/alibaba/FunASR.git # Install Conda:wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.shsh Miniconda3-latest-Linux-x86_64.shconda create -n funasr python=3.7conda activate funasr # Install Pytorch (version >= 1.7.0):conda install pytorch==1.7.0 torchvision==0.8.0 torchaudio==0.7.0 cudatoolkit=9.2 -c pytorch # For more versions, please see https://pytorch.org/get-started/locally/ # Install other packages:pip install --editable ./
- 安装ModelScope
pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
模型微调训练
- 数据准备
目前FunASR支持数据格式如下:
tree ./example_data/./example_data/├── dev│ ├── text│ └── wav.scp├── test│ ├── text│ └── wav.scp└── train ├── text └── wav.scp 3 directories, 6 files
text文件中存放音频标注,wav.scp文件中存放wav音频绝对路径,样例如下:
cat textBAC009S0002W0122 而 对 楼市 成交 抑制 作用 最 大 的 限 购BAC009S0002W0123 也 成为 地方 政府 的 眼中 钉 cat wav.scpBAC009S0002W0122 /mnt/data/wav/train/S0002/BAC009S0002W0122.wavBAC009S0002W0123 /mnt/data/wav/train/S0002/BAC009S0002W0123.wav
- 特征提取
原始数据准备完成后,按照以下方式提取训练所需特征:
cd egs_modelscope/common # compute fbank featuresutils/compute_fbank.sh --cmd "utils/run.pl" --nj 32 --speed_perturb "1.0" \ example_data/train ${exp_dir}/exp/make_fbank/train ${fbankdir}/trainutils/fix_data_feat.sh ${fbankdir}/train # apply low_frame_rate and cmvnutils/apply_lfr_and_cmvn.sh --cmd "utils/run.pl" --nj 32 --lfr True --lfr-m 7 --lfr-n 6 \ ${fbankdir}/train am.mvn ${exp_dir}/exp/make_fbank/train ${feat_train_dir} # Text Tokenize# 我爱reading->我 爱 read@@ ingutils/text_tokenize.sh --cmd "utils/run.pl" --nj 32 ${fbankdir}/train seg_dict ${feat_train_dir}/log ${feat_train_dir} # Dictionary Preparationawk -v v=,vocab_size '{print $0v}' ${feat_train_dir}/text_shape > ${feat_train_dir}/text_shape.charcp ${feat_train_dir}/speech_shape ${feat_train_dir}/text_shape ${feat_train_dir}/text_shape.char asr_stats_fbank_zh_char/train # dev集参照如上train集对音频进行特征提取
- 下载模型
Paraformer-large模型是达摩院语音实验室提供的基于大数据训练的通用领域识别模型,我们以此为basemodel做后续微调。设定模型名称后,执行命令完成模型下载。
modelname="speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"python modelscope_utils/download_model.py --model_name $modelname
- 模型训练
完成数据处理及模型下载后,可对conf/train_asr_paraformer_sanm_50e_16d_2048_512_lfr6.yaml配置进行修改,如学习率(lr)、最大训练epoch数(max_epoch)等,完成后我们就可以使用以下命令对模型进行微调:
python asr_train_paraformer.py \ --train_data_path_and_name_and_type ${feat_train_dir}/feats.scp,speech,kaldi_ark \ --train_data_path_and_name_and_type ${feat_train_dir}/text,text,text \ --valid_data_path_and_name_and_type ${feat_dev_dir}/feats.sc,speech,kaldi_ark \ --valid_data_path_and_name_and_type ${feat_dev_dir}/text,text,text \ --output_dir exp/model_dir \ --init_param base_model.pth \ --config finetune_config.yaml
- 模型效果体验
在模型微调完毕后,我们可以使用产出的模型来识别语音了,执行如下命令,对音频进行解码推理:
cp finetuned_model.pth exp_dir/finetune_model_name.modelscopecp -r ${HOME}/.cache/modelscope/hub/damo/pretrained_model_name/* exp_dir/ python -m funasr.bin.modelscope_infer \ --local_model_path exp_dir \ --wav_list example_data/dev/wav.scp \ --output_file logdir/text
一站式体验(推荐使用)
您也可以选择配置modelscope_common_finetune.sh脚本中的数据路径及参数配置,完成后一键执行进行模型的微调及推理,具体如下:
# 配置modelscope_common_finetune.sh中参数# dataset: 数据路径,结构如example_data所示,dev/test可不配置,若无dev数据处理过程中可自动抽取训练集中1000句音频作为dev集# tag: 结果保存路径后缀 # 配置修改完成后,执行命令启动模型微调训练及推理: sh modelscope_common_finetune.sh
除此之外,我们提供了AISHELL-1、AISHELL-2、WenetSpeech、SpeechIO的微调及推理脚本,如上配置好数据路径后即可执行启动训练,欢迎试用。
结合NNLM模型效果体验
Paraformer-large模型可结合NNLM语言模型进行推理,在inference的sh脚本中配置use_lm=true即可使用NNLM解码。接下来我们以SpeechIO测试集为例,展示如何结合语言模型解码:
cd egs_modelscope/speechio/paraformer # 配置paraformer_large_infer.sh中参数# ori_data: # 测试数据路径# data_dir: # 数据处理路径# exp_dir: # 结果保存路径# test_sets: # 测试集名称# use_lm=true # 是否使用LM# beam_size=10 # 设置beam_size# lm_weight=0.15 # 设置lm_weight # 测试集目录结构树,必须有trans.txt和wav.scptree SPEECHIO_ASR_ZH00001SPEECHIO_ASR_ZH00001├── metadata.tsv├── trans.txt├── wav│ ├── e5oipIfM49I__20190201_CCTV_10.wav│ └── e5oipIfM49I__20190201_CCTV_1.wav│ └── ...└── wav.scp # 配置修改完成后,执行命令启动模型推理: sh paraformer_large_infer.sh
2.如何从随机初始化训练自有模型
如果用户想要随机初始化模型,只需要将上述模型训练阶段中的“--init_param base_model.pth”移除掉,其他步骤同上。
当前ModelScope上语音识别主要是端到端的声学模型。完整的语音识别服务还包含类似于语音端点检测、文本后处理等模块,达摩院语音实验室进一步上线这些功能模型,持续将最新的研究以及落地转化成果上线到ModelScope,敬请期待。
References:
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Gao Z, Zhang S, McLoughlin I, et al. Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition[J]. arXiv preprint arXiv:2206.08317, 2022.
[3] Prabhavalkar R, Sainath T N, Wu Y, et al. Minimum word error rate training for attention-based sequence-to-sequence models[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 4839-4843.
[4] Watanabe S, Hori T, Karita S, et al. Espnet: End-to-end speech processing toolkit[J]. arXiv preprint arXiv:1804.00015, 2018.
[5] Yao Z, Wu D, Wang X, et al. Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit[J]. arXiv preprint arXiv:2102.01547, 2021.
[6] k2: Fsa/fst algorithms, differentiable, with pytorch compatibility., 2021. https://github.com/k2-fsa/k2.
[7] Ren X, Zhu H, Wei L, et al. Improving Mandarin Speech Recogntion with Block-augmented Transformer[J]. arXiv preprint arXiv:2207.11697, 2022.