Chap 1. Introduction
数据摩尔定律:人类每 18 个月产生的信息量,是人类之前全部总和!
2017 年已达 21.6ZB21.6ZB,2025 年将达到 163ZB
(1ZB = 1 百万 PB = 10 亿TB = 10^21 字节)
CCITT对媒体的定义
感知媒介 表达媒介 演示媒体 存储介质 传输介质
感知媒介
直接作用于人的感官,产生一种感觉
视觉、听觉、触觉、味觉、嗅觉
表达媒介
一种用于处理和传输感知媒体的构建媒体
各种编码方法
表达媒介
根据时间维度进行分类
离散媒体。图形、图像、文本
连续的媒体。声音、视频、动画
根据空间维度进行分类 1D:单通道音乐信号
二维:立体、文本、图形 3D:视频,3D图形
根据生成的属性进行分类 自然介质与合成介质
演示媒体
一种在感知媒体和用于通信的电信号之间进行转换的媒体类型。
输入。键盘、相机、麦克风
输出。显示器、扬声器、打印机
存储介质
用于存储数据以方便计算处理,主要指与计算机有关的外部存储设备。
硬盘,磁盘,CD
传输介质
用来将媒体从一个地方转移到另一个地方的物理载体
双绞线,同轴电缆,光纤
什么是多媒体?
一种新的信息载体,将各种(但相关的)媒体整合在一起,以满足存储、处理和传输的要求。
文本、声音、图形、图像、动画、视频
什么是多媒体技术?
多媒体技术是由计算机平台、通信网络、人机界面和相应的媒体数据系统技术组成。
改进信息表述、技术整合和实时互动
Relationship between mediums

文本检索
通过将文本记录(文档)与用户查询相匹配来查找符合给定标准的信息,而专家系统则是通过推断逻辑知识数据库来回答问题。
文件数据库
分类算法
访问数据库的用户接口
一个文本检索系统有两个主要任务
查找与用户查询相关的文件
使用PageRank等算法评估匹配结果,并根据相关性对其进行排序
图像检索
从大型数字图像数据库中浏览、搜索和检索图像
传统方法利用关键词或描述
对图像
费时、费力、费钱
基于内容的图像检索
旨在避免使用文本描述,而是根据图像内容(纹理、颜色、形状等)与用户提供的查询图像或用户指定的图像特征的相似性进行检索。
视频 检索
浏览视频内容的互动过程,以满足一些信息需求,或互动地检查视频内容是否相关。
通常建立在低级别的视频内容分析上,如镜头转换检测、关键帧提取、语义概念检测,并创建视频文件或视频档案图像或用户指定的图像特征的结构化内容概述
语音检索
一个基于内容的语音记录检索系统接受模糊的查询,它执行了通过最佳匹配搜索,找到可能与查询相关的语音记录。
这些领域包括语音识别、说话人识别和事件检测。
事件检测:根据音频类型(沉默、男性讲话、女性讲话、噪音等),将音频流分为若干段。
压力和情绪分类:试图辨别给定语音信号的压力水平或情绪标签
发言人日记:根据不同的发言人将语音音频分为不同的片段;回答 "谁在什么时候说话 "的问题。
发言人识别:在音频信号中识别特定的发言者;回答 "什么是 "的问题。
'‘说话的人的身份?
语音识别:识别正在进行的内容沟通了;回答了’‘对方在说什么’‘的问题。
多语言音频分析:包括多语言语音识别和自动语言识别。识别;回答’‘说的是什么语言’'的问题。
其应用非常广泛,涵盖了不同的领域,如人机交互、自动转录和生物识别认证。
与其他多媒体分析系统串联使用,实现对一个共同问题的多模式分析方法。
未来的研究
多模态检索技术 有效结合各种功能 视频功能+音频功能
从低级别的介绍到高级别的概念
高维索引技术
人机交互技术
业绩评估
多媒体信息安全
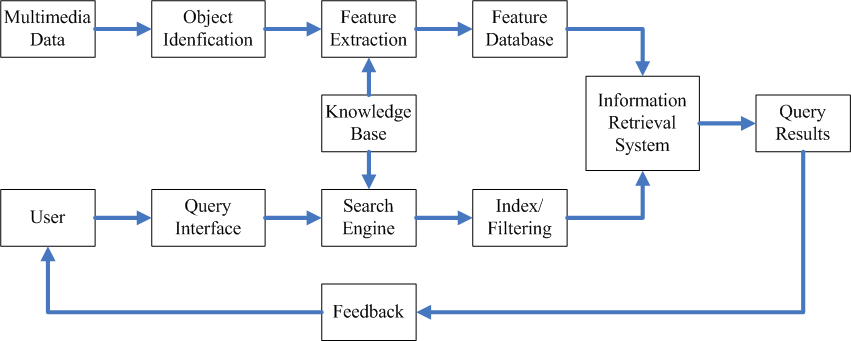
Framework of Multimedia Information Retrieval


![从零开始构建一个电影知识图谱,实现KBQA智能问答[上篇]:本体建模、RDF、D2RQ、SPARQL endpoint与两种交互方式详细教学](https://ucc.alicdn.com/fnj5anauszhew_20230711_4c048a4874924ceb8b4f3e08a1d54eb9.jpeg?x-oss-process=image/resize,h_160,m_lfit)
