关于Presto对lzo压缩的表查询使用记录

0.写在前面
- 实验背景:离线数仓项目
- Presto版本:0.196
- Hive版本:3.1.2
- Hadoop版本:3.1.3
1.正文
0.提前说明
- 纯lzo压缩:ods层
- parquet列式存储加lzo压缩:dwd,dws,dwt层
- 普通文本文件:ads层
1.查询ads层表
select*from ads_visit_stats;
ads层的查询没有任何问题。
2.查询dwd|dws|dwt层表
「Presto不支持parquet列式存储加lzo压缩的表的查询」
Presto-Client查询语句:
select*from dwd_start_log;
Presto-Client查询出错:
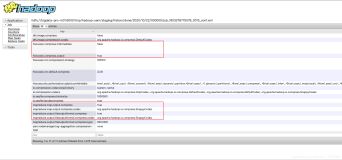
Query 20220914_021316_00014_sthct, FAILED, 2 nodes Splits: 22 total, 0 done (0.00%) 0:01 [0 rows, 0B] [0 rows/s, 0B/s]
查看Presto-Client查询出错的日志文件:
[root@node01 presto]$ tail-500 data/var/log/server.log
信息如下:
Query 20220914_021316_00014_sthct failed: Can not read value at 0 in block -1 in file hdfs://node01:8020/warehouse/gmall/dwd/dwd_start_log/dt=2020-06-15/000001_0 vim /opt/module/presto-0.196/data/var/log/server.log Caused by: parquet.hadoop.BadConfigurationException: Class com.hadoop.compression.lzo.LzoCodec was not found at parquet.hadoop.CodecFactory.getCodec(CodecFactory.java:161) at parquet.hadoop.CodecFactory.getDecompressor(CodecFactory.java:178) at parquet.hadoop.ParquetFileReader$Chunk.readAllPages(ParquetFileReader.java:610) at parquet.hadoop.ParquetFileReader.readNextRowGroup(ParquetFileReader.java:496) at parquet.hadoop.InternalParquetRecordReader.checkRead(InternalParquetRecordReader.java:127) at parquet.hadoop.InternalParquetRecordReader.nextKeyValue(InternalParquetRecordReader.java:208) ... 16 more
很明显,error显示为`com.hadoop.compression.lzo.LzoCodec`没有找到
对接lzo压缩包的要放置在presto安装目录下的 `plugin/hive-hadoop2`目录下
[root@node01 hive-hadoop2]$ cp /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-lzo-0.4.20.jar ./
- 分发lzo的jar包
[root@node01 hive-hadoop2]$ my_rsync ./hadoop-lzo-0.4.20.jar
- 重启Presto-server
[root@node01 presto]$ xcall.sh /opt/module/presto-0.196/bin/launcher stop[root@node01 presto]$ xcall.sh /opt/module/presto-0.196/bin/launcher start
- 超时|集群仍在初始化,没有足够的活跃的worker节点去执行查询语句
需要等待一会。

- 执行查询语句,不再报错
presto:gmall>select*from dwd_start_log

3.查询ods层表
- ods_log表是纯lzo压缩
presto:gmall>select*from ods_log;

[美团技术团队]提到: Presto不支持查询lzo压缩的数据 ,需要修改hadoop-lzo的代码
https://tech.meituan.com/2014/06/16/presto.html
解释说明
Presto是 即席查询 工具, ods层 的数据含有 敏感数据 和 脏数据 , 通常情况下,数据查询不需要对ods层查询 ,对于本项目而言,即便Presto读取不了ods层数据,也影响不大。
解决方案
对于这个问题,需要修改hadoop-lzo的代码,美团的解决方案开源在[Github]上:
顺利结束