深入浅出 HBase 实战 | 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第6天
参考链接:
juejin.cn/post/712681…
juejin.cn/post/684490…
分布式理论基础:
- CAP 理论:en.wikipedia.org/wiki/CAP_th…
特性
Hbase是一种NoSQL数据库,这意味着它不像传统的RDBMS数据库那样支持SQL作为查询语言。Hbase是一种分布式存储的数据库,技术上来讲,它更像是分布式存储而不是分布式数据库,它缺少很多RDBMS系统的特性,比如列类型,辅助索引,触发器,和高级查询语言等待。那Hbase有什么特性呢?如下:
- 强读写一致,但是不是“最终一致性”的数据存储,这使得它非常适合高速的计算聚合
- 自动分片,通过Region分散在集群中,当行数增长的时候,Region也会自动的切分和再分配
- 自动的故障转移
- Hadoop/HDFS集成,和HDFS开箱即用,不用太麻烦的衔接
- 丰富的“简洁,高效”API,Thrift/REST API,Java API
- 块缓存,布隆过滤器,可以高效的列查询优化
- 操作管理,Hbase提供了内置的web界面来操作,还可以监控JMX指标
适用场景
Hbase不适合解决所有的问题:
- 首先数据库量要足够多,如果有十亿及百亿行数据,那么Hbase是一个很好的选项,如果只有几百万行甚至不到的数据量,RDBMS是一个很好的选择。因为数据量小的话,真正能工作的机器量少,剩余的机器都处于空闲的状态
- 其次,如果你不需要辅助索引,静态类型的列,事务等特性,一个已经用RDBMS的系统想要切换到Hbase,则需要重新设计系统。
- 最后,保证硬件资源足够,每个HDFS集群在少于5个节点的时候,都不能表现的很好。因为HDFS默认的复制数量是3,再加上一个NameNode。
Hbase在单机环境也能运行,但是请在开发环境的时候使用。
\
HBase适用场景:
- “近在线”的海量分布式KV/宽表存储,数据量级达到百TB级以上
- 写密集型应用,高吞吐,可接受一定的时延抖动
- 需要按行顺序扫描的能力
- 接入Hadoop大数据生态
- 结构化、半结构化数据,可以经常新增/更新列属性
- 平滑的水平扩展
业务落地场景包括:
- 电商订单数据 抖音电商每日交易订单数据基于 HBase 存储,支持海量数据存储的同时满足稳定低延时的查询需求,并且只需相对很低的存储成本。通过多个列存储订单信息和处理进度,快速查询近期新增/待处理订单列表。同时也可将历史订单数据用于统计、用户行为分析等离线任务。
- 搜索推荐引擎 存储网络爬虫持续不断抓取并处理后的原始网页信息,通过 MapReduce、Flink、Spark 等大数据计算框架分析处理原始数据后产出粗选、精选、排序后的网页索引集,再存储到 HBase 以提供近实时的随机查询能力,为上层的多个字节跳动应用提供通用的搜索和推荐能力。
- 大数据生态 天生融入 Hadoop 大数据生态。对多种大数据组件、框架拥有良好的兼容性,工具链完善,快速打通大数据链路,提高系统构建落地效率,并借助 HDFS 提供可观的成本优势。敏捷平滑的水平扩展能力可以自如地应对数据体量和流量的快速增长。
- 广告数据流 存储广告触达、点击、转化等事件流,为广告分析系统提供快速的随机查询及批量读取能力,助力提升广告效果分析和统计效率。
- 用户交互数据 Facebook 曾使用 HBase 存储用户交互产生的数据,例如聊天、评论、帖子、点赞等数据,并利用 HBase 构建用户内容搜索功能。
- 时序数据引擎 基于 HBase 构建适用于时序数据的存储引擎,例如日志、监控数据存储。例如 OpenTSDB(Open Time Series Database)是一个基于 HBase 的时序存储系统,适用于日志、监控打点数据的存储查询。
- 图存储引擎 基于 HBase 设计图结构的数据模型,如节点、边、属性等概念,作为图存储系统的存储引擎。例如 JanusGraph 可以基于 HBase 存储图数据。
生态
通过在 HBase之上引入各种组件可以使HBase应用场景得到极大扩展,例如监控、车联网、风控、实时推荐、人工智能等场景的需求。
- Phoenix
主要提供SQL的方式来查询HBase里面的数据。一般能够在毫秒级别返回,比较适合OLTP以及操作性分析等场景,支持构建二级索引。
- Spark
很多企业使用HBase存储海量数据,一种常见的需求就是对这些数据进行离线分析,我们可以使用Spark(Spark SQL) 来实现海量数据的离线分析需求。同时,Spark还支持实时流计算,我们可以使用 HBase+Spark Streaming 解决实时广告推荐等需求。
- HGraphDB
分布式图数据库,可以使用其进行图 OLTP查询,同时结合 Spark GraphFrames 可实现图分析需求,帮助金融机构有效识别隐藏在网络中的黑色信息,在团伙欺诈、黑中介识别等。
- GeoMesa
目前基于NoSQL数据库的时空数据引擎中功能最丰富、社区贡献人数最多的开源系统。提供高效时空索引,支持点、线、面等空间要素存储,百亿级数据实现毫秒(ms)级响应;提供轨迹查询、区域分布统计、区域查询、密度分析、聚合、OD 分析等常用的时空分析功能;提供基于Spark SQL、REST、GeoJSON、OGC服务等多种操作方式,方便地理信息互操作。
- OpenTSDB
基于HBase的分布式的,可伸缩的时间序列数据库,适合做监控系统;比如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
- Solr
原生的HBase只提供了Rowkey单主键,仅支持对Rowkey进行索引查找。可以使用 Solr来建立二级索引/全文索引来扩展更多查询场景的支持。
HBase 核心数据模型
HBase 是存储计算分离架构,以 HDFS 作为分布式存储底座。数据实际存储在 HDFS。
HBase 依赖 Zookeeper 实现元数据管理和服务发现。Client 通过 Zookeeper 配置连接到 HBase集群
术语解释
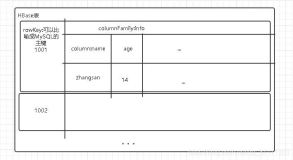
- Table:Hbase的table由多个行组成
- Row:一个行在Hbase中由一个或多个有值的列组成。Row按照字母进行排序,因此行健的设计非常重要。这种设计方式可以让有关系的行非常的近,通常行健的设计是网站的域名反转,比如(org.apache.www, org.apache.mail, org.apache.jira),这样的话所有的Apache的域名就很接近。
- Column:列由列簇加上列的标识组成,一般是“列簇:列标识”,创建表的时候不用指定列标识
- Column Family:列簇在物理上包含了许多的列与列的值,每个列簇都有一些存储的属性可配置。例如是否使用缓存,压缩类型,存储版本数等。在表中,每一行都有相同的列簇,尽管有些列簇什么东西也没有存。
- Column Qualifier:列簇的限定词,理解为列的唯一标识。但是列标识是可以改变的,因此每一行可能有不同的列标识
- Cell:Cell是由row,column family,column qualifier包含时间戳与值组成的,一般表达某个值的版本
- Timestamp:时间戳一般写在value的旁边,代表某个值的版本号,默认的时间戳是你写入数据的那一刻,但是你也可以在写入数据的时候指定不同的时间戳
HBase 是一个稀疏的、分布式、持久、多维、排序的映射,它以行键(row key),列键(column key)和时间戳(timestamp)为索引。
Hbase在存储数据的时候,有两个SortedMap,首先按照rowkey进行字典排序,然后再对Column进行字典排序。
SortedMap<RowKey,List<SortedMap<Column,List<Value,Timestamp>>>>
HBase数据格式

- HBase是半结构化存储。数据以行(row)组织,每行包括一到多个列簇(column family)。使用列簇前需要通过创建表或更新表操作预先声明column family。
- column family是稀疏存储,如果某行数据未使用部分column family则不占用这部分存储空间。
- 每个column family由一到多个列(column qualifier)组成。column qualifier不需要预先声明,可以使用任意值。
- 最小数据单元为cell,支持存储多个版本的数据。由rowkey + column family + column qualifier + version指定一个cell。
- 同一行同一列族的数据物理上连续存储;
- 同列族内的Keyvalue按照rowkey字典序升序,column qualifier字典序升序,version(或者timestamp)降序排列。
- 不同列族的数据存储在相互独立的物理文件,列族间不保证数据全局有序;同列族下不同物理文件间不保证数据全局有序;仅单个物理文件内有序。


简单起见可以将HBase数据格式理解为如下结构:
// table名格式:"${namespace}:${table}" // 例如:table = "default:test_table" [{ "rowKey1": { // rowkey定位一行数据 "column family1": { // column family需要预先定义到表结构 "column qualifier a": { // column qualifier无需定义,使用任意值 "version1": "name1", }, "column qualifier b": { // 定位一个cell具体的版本: row=rowKey1, column="column family1:column qualifier b", version=version2 "version3": "email3", "version2": "email2", "version1": "email1" } }, "column family 2": { "column qualifier c": { "version1": "address1", }, }, }, "rowKey2": { // 缺省column family不占用存储空间 "column family 2": { "column qualifier c": { "version1": "address2", }, "column qualifier d": { "version1": "id2", } }, } }]
HBase的结构:

\
HBase数据模型的优缺点:

Hbase架构

主要组件:
- HMaster:元数据管理,集群调度,保活
- RegionServer,提供数据读写服务,理解为数据节点,存储数据的。
- ThriftServer:提供Thrift API读写的代理层
依赖组件:
- Zookeeper,作为分布式的协调。RegionServer也会把自己的信息写到ZooKeeper中。
- HDFS是Hbase运行的底层文件系统
\
架构细化

HMaster
HMaster是Master Server的实现,主要职责有:
- 管理RegionServer实例生命周期,保证服务可用性
- 协调RegionServer数据故障恢复,保证数据正确性
- 集中管理集群元数据,执行负载均衡等维护集群稳定性
- 定期巡检元数据,调整数据分布,清理废弃数据等
- 处理用户主动发起的元数据操作如建表、删表等
负责监控集群中的RegionServer实例,同时是所有metadata改变的接口,在集群中,通常运行在NameNode上面,这里有一篇更细的HMaster介绍
\
主要组件:

- ActiveMasterManager:管理HMaster的active/backup状态
- ServerManager:管理集群内RegionServer 的状态
- AssignmentManager:管理数据分片(region) 的状态
- SplitWalManager:负 责故障数据恢复的WAL拆分工作
- LoadBalancer: 定期巡检、调整集群负载状态
- RegionNormalizer:定期巡检并拆分热点、整合碎片
- CatalogJanitor:定期巡检、清理元数据
- Cleaners:定期清理废弃的HFile / WAL等文件
- MasterFileSystem:封装访问HDFS的客户端SDK
HMasterInterface暴露的接口,Table(createTable, modifyTable, removeTable, enable, disable),ColumnFamily (addColumn, modifyColumn, removeColumn),Region (move, assign, unassign)
Master运行的后台线程:LoadBalancer线程,控制region来平衡集群的负载。CatalogJanitor线程,周期性的检查hbase:meta表。
RegionServer
HRegionServer是RegionServer的实现,服务和管理Regions,集群中RegionServer运行在DataNode。
\
主要职责:
- 提供部分rowkey区间数据的读写服务
- 如果负责meta表,向客户端SDK提供rowkey位置信息
- 认领HMaster发布的故障恢复任务,帮助加速数据恢复过程
- 处理HMaster下达的元数据操作,如region打开/关闭1分裂1合并操作等
HRegionRegionInterface暴露接口:Data (get, put, delete, next, etc.),Region (splitRegion, compactRegion, etc.)
RegionServer后台线程:CompactSplitThread,MajorCompactionChecker,MemStoreFlusher,LogRoller
主要组件:

- MemStore:基于SkipList 数据结构实现的内存态存储,定期批量写入硬盘
- Write -Ahead-Log:顺序记录写请求到持久化存储,用于故障恢复内存中丢失的数据
- Store:对应一个Column Family在一个region下的数据集合,通常包含多个文件
- StoreFile:即HFile, 表示HBase在HDFS存储数据的文件格式,其内数据按rowkey字典序有序排列
- BlockCache:HBase以数据块为单位读取数据并缓存在内存中以加速重复数据的读取
\
ZooKeeper
主要职责:
- HMaster登记信息,对active/backup分工达成共识
- RegionServer登记信息,失联时HMaster保活处理
- 登记meta表位置信息,供SDK查询读写位置信息
- 供HMaster和RegionServer协作处理分布式任务

ThriftServer
主要职责:
- 实现HBase定义的Thrift API,作为代理层向用户提供RPC读写服务
- 用户可根据IDL自行生成客户端实现
- 独立于RegionServer水平扩展,用户可访问任意ThritServer实例 (scan操作较特殊,需要同实例维护scan状态)
\

\
存储设计
在Hbase中,表被分割成多个更小的块然后分散的存储在不同的服务器上,这些小块叫做Regions,存放Regions的地方叫做RegionServer。Master进程负责处理不同的RegionServer之间的Region的分发。在Hbase实现中HRegionServer和HRegion类代表RegionServer和Region。HRegionServer除了包含一些HRegions之外,还处理两种类型的文件用于数据存储
- HLog, 预写日志文件,也叫做WAL(write-ahead log)
- HFile 真实的数据存储文件
HLog
- MasterProcWAL:HMaster记录管理操作,比如解决冲突的服务器,表创建和其它DDLs等操作到它的WAL文件中,这个WALs存储在MasterProcWALs目录下,它不像RegionServer的WALs,HMaster的WAL也支持弹性操作,就是如果Master服务器挂了,其它的Master接管的时候继续操作这个文件。
- WAL记录所有的Hbase数据改变,如果一个RegionServer在MemStore进行FLush的时候挂掉了,WAL可以保证数据的改变被应用到。如果写WAL失败了,那么修改数据的完整操作就是失败的。
- 通常情况,每个RegionServer只有一个WAL实例。在2.0之前,WAL的实现叫做HLog
- WAL位于*/hbase/WALs/*目录下
- MultiWAL: 如果每个RegionServer只有一个WAL,由于HDFS必须是连续的,导致必须写WAL连续的,然后出现性能问题。MultiWAL可以让RegionServer同时写多个WAL并行的,通过HDFS底层的多管道,最终提升总的吞吐量,但是不会提升单个Region的吞吐量。
- WAL的配置:// 启用multiwal hbase.wal.provider multiwal 复制代码
Wiki百科关于WAL
HFile
HFile是Hbase在HDFS中存储数据的格式,它包含多层的索引,这样在Hbase检索数据的时候就不用完全的加载整个文件。索引的大小(keys的大小,数据量的大小)影响block的大小,在大数据集的情况下,block的大小设置为每个RegionServer 1GB也是常见的。
探讨数据库的数据存储方式,其实就是探讨数据如何在磁盘上进行有效的组织。因为我们通常以如何高效读取和消费数据为目的,而不是数据存储本身。
Hfile生成方式
起初,HFile中并没有任何Block,数据还存在于MemStore中。
Flush发生时,创建HFile Writer,第一个空的Data Block出现,初始化后的Data Block中为Header部分预留了空间,Header部分用来存放一个Data Block的元数据信息。
而后,位于MemStore中的KeyValues被一个个append到位于内存中的第一个Data Block中:
注:如果配置了Data Block Encoding,则会在Append KeyValue的时候进行同步编码,编码后的数据不再是单纯的KeyValue模式。Data Block Encoding是HBase为了降低KeyValue结构性膨胀而提供的内部编码机制。

主要数据结构
HDFS目录结构
hdfs://base_dir/hbase_cluster_name/data/default/table_name/region_name/column_family_name/hfile_name region_name:(e.g.fffe6d7a8e19490f8770fbe8637a686c) /hfile_name:(e.g.7a8b82e197274fd7ade1a7f6b20b9417)
MemStore
MemStore数据结构详细介绍可参考 hbasefly.com/2019/10/18/…
MemStore使用SkipList组织KeyValue数据,提供O(logN)的查询/插入/删除操作,支持双向遍历。
具体实现采用JDK标准库的ConcurrentSkipListMap,结构如下图:

图片选自 hbasefly.com/2019/10/18/…
写一个KeyValue到MemStore的顺序如下:
- 在JVM堆中为KeyValue对象申请一块内存区域。
- 调用ConcurrentSkipListMap的put(K key, V value)方法将这个KeyValue对象作为参数传入。

图片选自 hbasefly.com/2019/10/18/…
HFile
HFile结构介绍详见hbasefly.com/2016/03/25/…
HFile是HBase存储数据的文件组织形式.
参考BigTable的SSTable和Hadoop的TFile实现。
HFile共经历了三个版本,其中V2在0.92引入,V3在0.98引入。
HFileV1版本的在实际使用过程中发现它占用内存多,HFileV2版本针对此进行了优化,HFileV3版本基本和V2版本相同,只是在cell层面添加了Tag数组的支持。
这里主要针对V2版本进行分析。
官方文档的HFile逻辑结构图如下:

图片选自 hbase.apache.org/book.html#_…
\
由上图知HFlie主要分为4个section
- Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block。
- Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
- Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index。
- Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
物理结构
HFlie物理结构如下图所示:

图片选自 hbasefly.com/2016/03/25/…
\
如上图所示,一个HFile内的数据会被切分成等大小的block,每个block的大小可以在创建表列簇的时候通过参数
blocksize =>‘65535’进行指定。
默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询,需要根据使用场景来权衡block大小。
HBase将block块抽象为一个统一的HFileBlock。HFileBlock支持两种类型,一种类型不支持checksum,一种不支持。为方便讲解,下图选用不支持checksum的HFileBlock内部结构:

上图所示HFileBlock主要包括两部分:BlockHeader和BlockData。其中BlockHeader主要存储block元数据,BlockData用来存储具体数据。block元数据中最核心的字段是BlockType字段,用来标示该block块的类型,HBase中定义了8种BlockType,每种BlockType对应的block都存储不同的数据内容,有的存储用户数据,有的存储索引数据,有的存储meta元数据。对于任意一种类型的HFileBlock,都拥有相同结构的BlockHeader,但是BlockData结构却不相同。
Block
下面对HFile中的Block进行解析:
Data Block
HBase中数据存储的最小文件单元。主要存储用户的KeyValue数据。KeyValue是HBase数据表示的最基础单位,每个数据都是以KeyValue结构在HBase中进行存储。KeyValue结构的内存/磁盘表示如下:每个KeyValue都由4个部分构成,分别为key length,value length,key和value。其中key value和value length是两个固定长度的数值,而key是一个复杂的结构,首先是rowkey的长度,接着是rowkey,然后是ColumnFamily的长度,再是ColumnFamily,之后是ColumnQualifier,最后是时间戳和KeyType(keytype有四种类型,分别是Put、Delete、 DeleteColumn和DeleteFamily),value就没有那么复杂,就是一串纯粹的二进制数。
更详情的Block参考链接:BloomFilter Meta Block & Bloom Block 链接
\
Block Index
索引分为单层和多层两种。单层即root data index,在打开HFile时就全量加载进内存。结构表示如下:

图片选自 hbasefly.com/2016/04/03/…
图中:
- Block Offset 表示索引指向数据块的偏移量,
- BlockDataSize 表示索引指向数据块在磁盘上的大小,
- BlockKey 表示索引指向数据块中的第一个key
- 其他三个字段记录HFile所有Data Block中最中间的一个Data Block,用于在对HFile进行split操作时,快速定位HFile的中间位置
Root Index Entry不是定长的,因此需要在Trail Block中的dataIndexCount记录entry数量才能保证正常加载。
NonRoot Index一般有intermediate和leaf两层,具有相同结构。Index Entry指向leaf索引块或者数据块。NonRoot index通过entry Offset实现索引块内的二分查找来优化查询效率。

图片选自 hbasefly.com/2016/04/03/…
完整的索引流程如下图,rowkey通过多级索引以类似B+树的方式定位到所属的数据块。

图片选自 hbasefly.com/2016/04/03/…
HBase文件操作
HBase 写数据
HBase写入数据的步骤如下:
- 数据先写入 WAL 持久化,用于宕机时恢复内存里丢失的数据;
- 再写入内存态 MemStore,以一种跳表(SkipList) 数据结构提供有序的数据和高效的随机读写;
- 当满足特定条件时(比如内存中数据过多,或间隔时间过长),MemStore 数据以 HFile 格式写入 HDFS
HBase 读数据
HBase读数据的步骤如下:
- 首次读某个 rowkey 时,client 需要从 Zookeeper 获取 hbase:meta 表位于哪个 RegionServer上;
- 然后访问该 RegionServer 查询 hbase:meta 表该 rowkey 对应 region 所在的 RegionServer B;
- Client 缓存该位置信息,去 RegionServer B 读取 rowkey;
- 基于该region内可能存在该 rowkey 的 HFile 和 MemStore 构建一个最小堆,用以全局有序地 scan 数据(具体实现可搜索参考 LSM tree 设计原理)
Compaction(文件合并)
HBase 基于策略和定期整理 HFile 文件集合,将多个有序小文件合并成若干个有序的大文件。
Compaction 类型:
- Minor compaction: 指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次 Minor Compaction 的结果是更少并且更大的StoreFile。
- Major compaction: 指将所有的StoreFile合并成一个StoreFile。这个过程会清理三类没有意义的数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据。另外,一般情况下,major compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响。因此线上业务都会将关闭自动触发major compaction功能,改为手动在业务低峰期触发。
Compaction 触发条件
- memstore flush:可以说compaction的根源就在于flush,memstore 达到一定阈值或其他条件时就会触发flush刷 写到磁盘生成HFile文件,正是因为HFile文件越来越多才需要compact。HBase每次flush之后,都会判断是否要进行compaction,一旦满足minor compaction或major compaction的条件便会触发执行。
- 后台线程周期性检查:
后台线程 CompactionChecker 会定期检查是否需要执行compaction,检查周期为
hbase.server.thread.wakefrequency*hbase.server.compactchecker.interval.multiplier,
这里主要考虑的是一段时间内没有写入请求仍然需要做compact检查。
其中参数 hbase.server.thread.wakefrequency 默认值 10000 即 10s,是HBase服务端线程唤醒时间间隔,用于log roller、memstore flusher等操作周期性检查;
参数 hbase.server.compactchecker.interval.multiplier 默认值1000,是compaction操作周期性检查乘数因子。10 * 1000 s 时间上约等于2hrs, 46mins, 40sec。
- 手动触发:是指通过HBase Shell、Master UI界面或者HBase API等任一种方式 执行 compact、major_compact等命令。
\
HMaster
主要组件
CatalogJanitor
定期扫描元数据hbase:meta的变化,回收无用的region(仅当没有region-in-transition时)。
scan方法执行扫描、回收操作:
- 扫描一遍hbase:meta找出可回收的region,检查元数据一致性并生成报告实例
- 已完成merge或split的region都可被回收,即子目录/父目录没有reference文件后
- 创建GCMultipleMergedRegionsProcedure/GCRegionProcedure异步回收regions
- GCMultipleMergedRegionsProcedure步骤:
- merge的两个源region分别创建GCRegionProcedure删除region数据
- 删除merge生成region元信息的merge qualifiers(info:mergeN)
- GCRegionProcedure步骤:
- archive要回收region的HFiles
- 删除region对应的WAL
- assignmentManager删除region state
- meta表删除该region记录
- masterService、FavoredNodesManager删除该region
AssignmentManager
管理region分配,processAssignQueue方法每当pendingAssignQueue放满RegionStateNode时批量处理。单独启动daemon线程循环处理。
processAssignmentPlans方法雇用LoadBalancer
- 首先尝试尽量保持现有分配
- 将分配plan的目标server region location更新到对应RegionStateNode中
- 将regionNNode的ProcedureEvent放入队列,统一唤醒所有regionNodes的events上等待的procedures
- 不保持原有分配的通过loadbalancer的round-robin策略分配(原则是不能降低availability)
- 分配失败的塞回pendingAssignQueue下次重新处理
setupRIT方法处理RIT,仅仅是设置RegionStateNode的this.procedure和ritMap
启动流程
- 先将自己加到backup master的ZK目录下,这样抢主失败了active master能感知到backup;
- 除非关闭master,无限循环尝试写入active master的ZK目录来抢主,成功的话从backup目录删除自己的znode;失败的话监听ZK上activeMaster的znode,主挂了就再次抢主
- 初始化文件系统相关组件
- MasterFileSystem - 封装对底层HDFS文件系统的交互
- MasterWalManager - 封装master分裂WAL操作,管理WAL文件、目录
- TableDescriptor - 管理table信息,预加载所有table的信息
- 发布clusterID到ZK,位于/hbase/hbaseid
- 加文件锁防止hbck1在hbase2集群执行造成数据损坏
- 初始化以下master状态管理组件
- ServerManager - 管理regionserver状态(online/dead),处理rs启动、关闭、恢复
- SplitWALManager - 代替ZK管理split WAL的procedures,
- ProcedureExecutor - 负责调度、执行、恢复procedures,包含以下组件
- WALProcedureStore - 持久化记录procedure状态,用于故障恢复未完成的procedure。
- MasterProcedureScheduler - 针对procedure类型选择合适的并发控制,例如region是server/namespace/table/region等粒度,大致原理是提供不同等级的queue来跑任务。

- 只init procedureExecutor来加载procedures但不开始让workers执行,因为要等DeadServers的ServerCrashProcedures调度执行完成,避免重复执行SCP。
- AssignmentManager - 负责调度region,包含以下组件
- RegionStates - 管理内存态的region状态,包括online/offline/RIT的region信息 RegionStateNode表示一个region的内存态状态,和meta表保持一致,会关联TransitRegionStateProcedure以保证最多一个RIT在并发
- RegionStateStore - 负责更新region state到meta表 AssignmentManager::start()方法从ZK路径meta-region-server加载meta region state,对第一个meta region(hbase:meta,,1.1588230740)上锁后设置region location、state、唤醒等待着meta region online的event
- 从procedure列表里找出RIT,即未完成的TransitRegionStateProcedure,由AssignmentManager::setupRIT方法将RIT的procedures绑定到regionStates里对应的region
- RegionServerTracker - 监听ZK的rs目录管理online servers,对比ServerCrashProcedure列表、HDFS的WAL目录里的alive/splitting rs记录,delta就是dead servers,并分别调用ServerManager::expireServer安排
- ServerCrashProcedures;将online rs添加到ServerManager管理。ServerCrashProcedure流程如下:
- SERVER_CRASH_START:如果挂了的rs负责meta表,先进入SERVER_CRASH_SPLIT_META_LOGS状态split meta WAL,将rs状态设为SPLITTING_META, MasterWalManager::splitMetaLog在HDFS找到该rs的WAL目录,移动到-splitting结尾的新路径避免更多WAL写入。 这里支持用ZK或不用ZK两种模式,先介绍用ZK的模式:
- SplitLogManager::splitLogDistributed方法过滤出该路径下.meta结尾的WAL文件,为每个文件提交一个Task并记录到ZK目录splitWAL下,由ZkSplitLogWorkerCoordination协调online的regionserver认领并通过SplitLogWorker::splitLog方法处理,核心逻辑在WALSplitter::splitLogFile里,依次读取WAL文件每条entry,格式如下:

 对每个WAL entry的region检查lastFlushedSeqID,如果大于WAL entry的seqID就跳过,否则放入buffer,LogRecoveredEditsOutputSink异步批量写到临时目录里对应region的recovered.edits目录下,具体实现在OutputSink::duRun里,调用LogRecoveredEditsOutputSink::append,最终在ProtobufLogWriter::append方法将rowkey和cells追加写到HDFS里tmp目录下对应region的recovered.edits目录;
对每个WAL entry的region检查lastFlushedSeqID,如果大于WAL entry的seqID就跳过,否则放入buffer,LogRecoveredEditsOutputSink异步批量写到临时目录里对应region的recovered.edits目录下,具体实现在OutputSink::duRun里,调用LogRecoveredEditsOutputSink::append,最终在ProtobufLogWriter::append方法将rowkey和cells追加写到HDFS里tmp目录下对应region的recovered.edits目录;

- 等所有log split都结束后设置serverState为SPLITTING_META_DONE。 不用ZK的模式将上述步骤封装成SplitWALProcedure,由HMaster协调全过程。
- \
- SERVER_CRASH_ASSIGN_META:ZK模式进入此状态assign meta region上线,然后进入SERVER_CRASH_GET_REGIONS状态获取该宕机rs上的region列表,进入SERVER_CRASH_SPLIT_LOGS状态处理用户数据的WAL split,过程类似上述meta WAL split,全部完成后标记rs的ServerState状态OFFLINE。(非ZK模式通过SplitWALProcedure处理)
- SERVER_CRASH_ASSIGN状态assign该rs上所有挂掉的region后进入SERVER_CRASH_FINISH状态删除该rs,标记这个dead server处理完成
- TableStateManager - meta表确认已online才能启动,负责更新table state到meta表
- 初始化一系列ZK相关的trackers
- LoadBalancer
- RegionNormalizer
- LoadBalancerTracker
- RegionNormalizerTracker
- SplitOrMergeTracker
- ReplicationPeerManager
- DrainingServerTracker
- MetaLocationSyncer + MasterAddressSyncer (client ZK不是observer mode时需要)
- SnapshotManager
- MasterProcedureManagerHost
- InitializationMonitor - zombie master检测 HBASE-21535
- 如果是新建集群,安排InitMetaProcedure来初始化元数据,即创建AssignProcedure把meta表region拉起
- 初始化以下后台服务
- Balancer
- CatalogJanitor
- ExecutorServices
- LogCleaner
- HFileCleaner
- ReplicationBarrierCleaner
- 等待元数据构建完成
- 等待足够多RegionServer加入集群,默认至少1个,可配置数量: hbase.master.wait.on.regionservers.maxtostarthbase.master.wait.on.regionservers.mintostart
- AssignmentManager::joinCluster扫描meta表每行数据,构建regionStates,wake等待meta加载后执行的任务。
- 启动其他Chore服务,如:
- RITChore - 定期巡检RIT数量是否过多并打warn日志和打metrics
- DeadServerMetricRegionChore - 定期打deadServer相关metrics
- TableStateManager::start扫描meta表的table:state column和HDFS上每个table目录下.tabledesc目录下最新的$seqNum.tableinfo文件(即seqNum最大的.tableinfo文件),将meta表里的tableState添加到内存中的tableState,HDFS里不存在则设置为ENABLED
- assignmentManager::processOfflineRegions对每个offline region创建AssignProcedure,按round-robin策略分配
- 如果开启了favoredNode功能,扫meta创建一个索引多种查询模式(rs->region, region->rs等)的元数据快照来初始化favoredNodesManager
- 启动Chore服务
- ClusterStatusChore
- BalancerChore
- RegionNormalizerChore
- CatalogJanitor
- HbckChore
- assignmentManager检查regionserver实例是否存在不同版本,是则移动所有system table到版本最新的rs上以保证兼容性。
- 初始化quota
- serverManager.clearDeadServersWithSameHostNameAndPortOfOnlineServer清楚deadServer里相同host和port的已经online的rs,因master初始化期间加入的rs未更新状态,见HBASE-5916
- 检查ZK上ACL配置
- 初始化MobCleaner
- 最后刷新下balancer的RegionLocationFinder
- 创建master addr tracker,注册到zk,阻塞等待master上线
- 等待master实例在zk设置集群状态为已上线
- 从zk读取clusterID,等待active master上线
- 初始化RegionServerProcedureManagerHost并加载procedures,包括:
RegionServerSnapshotManager
RegionServerFlushTableProcedureManager
- 创建cluster connection和联系master用的rpc client
- 创建RegionServerCoprocessorHost
- 反复尝试向master rpc通知本region server上线,直到成功
- 通过masterAddressTracker.getMasterAddress获取master地址
- 创建rpc通道并调用rpc regionServerStartup。 master实现如下:
- MasterRpcServices.regionServerStartup确认master启动完成
- 调用ServerManager.regionServerStartup检查clock ske,以及发起请求的region server是否被记录为dead,是则返回异常让rs自杀。(每次rs启动会携带递增的start code以唯一标识每次重启)通过检查后将该rs加入ServerManager实例内部的onlineServers中(基于ConcurrentSkipListMap)同时移出rsAdmins(HashMap),这里存着未纳入集群的rs。
- response返回master看到的该rs的hostname信息,rs发现不一致的话抛异常
- 在zk创建该region server的临时节点并存储infoPort、versionInfo信息
- response还可能返回hbase.rootdir让rs以此目录初始化filesystem。把conf里的rootDir更新成匹配hbase.rootdir配置对应的fs类型,以免用错fs。
- 初始化WAL和replication。在filesystem创建该region server的wal目录。通过反射创建新replication实例
- 启动RegionServerPrecedureManagerHost,启动snapshot handler和其他procesure handlers
- 启动quotaManager
- 定期向master上报负载信息,调用regionServerReport RPC
Master故障恢复
故障恢复流程即从master实例从ZK监听到主master节点掉了,抢主成功后执行上述启动流程。
HMaster自身恢复流程:
监听到/hbase/active-master临时结点被删除事件,触发选主逻辑;选主成功后执行HMaster启动流程,从持久化存储读取未完成的procedures从之前的状态继续执行;故障HMaster实例恢复后发现主节点已存在,继续监听/hbase/active-master
二、调度RegionServer的故障恢复流程:
- AssignmentManager从procedure列表中找出Region-In-Transition 状态的region继续调度过程;
- RegionServerTracker 从Zookeeper梳理online状态的RegionServer列表,结合ServerCrashProcedure列表、HDFS中WAL目录里alive / splitting状态的RegionServer记录,获取掉线RegionServer的列表,分别创建ServerCrashProcedure执行恢复流程。
\
RegionServer
启动流程
先初始化所有组件但不启动,直到reportForDuty成功注册到Hmaster后才启动所有服务。
- 在ctor里初始化(不启动)
- 初始化Netty server event loop用于RPC server/client和WAL
- 检查Memory limit,HFile version,codecs,初始化UserProvider,配置短路读等
- 初始化RSRpcServices,其中是所有RPC接口的实现
- 初始化HFileSystem和FSTableDescriptors
- 初始化ZK,创建:
- ZkCoordinatedStateManager来协调WAL split
- MasterAddressTracker管理ZK上当前active master信息,监听主master变化
- ClusterStatusTracker管理ZK上的cluster配置信息
- 创建ChoreService和ExecutorService
- 拉起rs的webUI
- reportForDuty成功上报HMaster(启动服务)
- 上报前初始化ZK,创建RegionServerProcedureManagerHost并从配置项hbase.procedure.regionserver.classes加载system procedures、RegionServerSnapshotManager和RegionServerFlushTableProcedureManager
- 初始化可以短路优化本地请求的ClusterConnection和用于HMaster通信的client
- 从ZK获取当前active master地址,发送RegionServerStartupRequest向master注册本rs
- 成功收到resp后在handleReportForDutyResponse方法把master返回的KV对加入自身conf,在ZK创建ephemeral znode(默认目录rs/hostname,hostname,hostname,port,$startcode),把rsInfo写入value,PB格式如下:

- 如果resp里有hbase.rootdir这个key,需要重新初始化FS更新rootDir
- ZNodeClearer::writeMyEphemeralNodeOnDisk把rs的ZK ephemeral节点路径写入FS里HBASE_ZNODE_FILE环境变量设置的路径。server正常退出时会删除该文件,用来识别server是否正常退出,加速恢复
- 创建WAL相关目录,并初始化replication的source和sink实例并启动
- 唤醒等待rs online的线程
- 启动snapshotManager和其他procedureHandlers,quotaManager
- 定期调用HMaster的regionServerReport RPC上报server load,报错则尝试重建连接
故障恢复
regionserver每次启动的startcode不同,都视为一个新的rs实例,因此走一遍启动流程。
启动流程如下:
1.启动时去Zookeeper登记自身信息,告知主HMaster实例有新RS实例接入集群
2.接收和执行来自HMaster 的region调度命令
3.打开region前先从HDFS读取该region的recovered.edits目录下的WAL记录,回放恢复数据
4.恢复完成,认领Zookeeper.上发布的分布式任务(如WAL切分)帮助其他数据恢复
Region
Region状态转换统一抽象成TransitRegionStateProcedure。RIT即一个region有未完成的TRSP。常见的状态转换包括以下几种:
- assign region: GET_ASSIGN_CANDIDATE ------> OPEN -----> CONFIRM_OPENED
- 设置region的candidate rs,AssignmentManager异步用balancer选择rs打开region。assign是封装成一个AssignmentProcedureEvent创建在RegionStateNode里,AssignmentManager::processAssignQueue批量获取待assign region的regionStateNodes,acceptPlan方法里依次调用每个AssignmentProcedureEvent的wakeInternal方法,将阻塞等待在event上的procedures保序加入procedureScheduler调度队列恢复执行。
- AssignmentManager::regionOpening更新regionNode状态为OPENING,regionStates添加region和对应的rs记录,创建子过程OpenRegionProcedure,这个RemoteProcedure会向目标rs发送executeProcedures RPC,在RSRpcServices::executeOpenRegionProcedures方法里提交AssignRegionHandler异步地通过HRegion.openHRegion做以下操作:
- 写RegionInfo到HDFS上region的目录/ns/table/encodedRegionName下的.regioninfo文件用于恢复meta表数据。如果相同文件内容已存在就跳过,否则覆盖写(先写到region目录下.tmp目录,再move)
- initializeStores并发初始化每个cf的HStore,创建cf的hdfs目录,配置blocksize、hdfs storagePolicy、dataBlockEncoding、cell comparator、TTL、低峰期等,创建memstore,创建StoreEngine(集成storeFlusher,compactionPolicy,Compactor,storeFileManager的工厂实例),遍历HDFS上该region该cf的HFiles创建StoreFileInfo集合,并发打开reader,从HFIie读取元信息compectedFiles并移动到archive目录下WIP here
- unassign region: CLOSE -----> CONFIRM_CLOSED
- reopen/move region: CLOSE -----> CONFIRM_CLOSED -----> GET_ASSIGN_CANDIDATE ------> OPEN -----> CONFIRM_OPENED
同一时刻一个region只能最多有一个TRSP。
HRegion
Region name格式:
,,_.. 复制代码
regionId: Usually timestamp from when region was created
encodedName: MD5 hash of the ",,_" part (included only for the new format)
例如:
ycsb_test,user6399,1600830539266_0.3be086687f0a59f0f3fd74d5041be1bd. 复制代码
MD5哈希值(上例中的3be086687f0a59f0f3fd74d5041be1bd)作为hbase:meta表的rowkey用于查对应region信息。建表时的region pre-split过程就是预先在hbase:meta表写入记录切分好region,比如用"0000"到"9999"之间的多个数值分别作为region start_key。
代码见private void locateInMeta(TableName tableName, LocateRequest req)
Region Split 热点切分
hbasefly.com/2017/08/27/…
HBase支持的几种常见region split触发策略如下:
- ConstantSizeRegionSplitPolicy:0.94版本前默认切分策略。一个region中最大store的大小大于设置阈值之后触发切分。阈值(hbase.hregion.max.filesize)设置较大对大表比较友好,但是小表就有可能不会触发分裂,极端情况下可能就1;设置较小则对小表友好,但一个大表就会在整个集群产生大量的region。
- IncreasingToUpperBoundRegionSplitPolicy: 0.94版本~2.0版本默认切分策略。总体来看和ConstantSizeRegionSplitPolicy思路相同,一个region中最大store大小大于设置阈值就会触发切分。阈值计算公式 :(#regions) * (#regions) * (#regions) * flush size * 2,最大不超过用户设置的MaxRegionFileSize。这种切分策略很好的弥补了ConstantSizeRegionSplitPolicy的短板,能够自适应大表和小表。
- SteppingSplitPolicy: 2.0版本默认切分策略。如果region个数等于1,切分阈值为flush size * 2,否则为MaxRegionFileSize。这种切分策略对于大集群中的大表、小表会比IncreasingToUpperBoundRegionSplitPolicy更加友好,小表不会再产生大量的小region,而是适可而止。

Region split 步骤如下:
目标:优先把最大的数据文件均匀切分
找到切分点splitpoint,一般是整个region中最大store中的最大HFile文件中最中心的一个block的首个rowkey。
切分点选择:
- 1.找到该表中的最大region

2.找到该region中最大的column family

3.找到column family中最大的HFile

4.找到HFile里处于最中间位置的Data Block,用这个Data Block的第一条Keyvalue的Rowkey作为切分点

\
切分过程:
➢所有ColumnFamily都按照统一的切分点来切分数据。
➢目的是优先均分 最大的文件,不保证所有Column Family的所有文件都被均分。
➢HFile1作为最大的文件被均分,其他文件也必须以相同的rowkey切分以保证对齐新region的rowkey区间。

切分出的新region分别负责rowkey区间[2000,2500)和[2500,4000)。
每个新region分别负责原region的上/下半部分rowkey区间的数据。
在compaction执行前不实际切分文件,新region下的文件通过referencefile指向原文件读取实际数据。


\
流程设计:
AssignmentManager检查cluster、 table、 region 的状态后,创建SplitTableRegionProcedure通过状态机实现执行切分过程。
\

\
Region Merge 碎片整合
region merge可以通过HBaseAdmin手动触发,或由normalization触发。merge流程如下:
- 调用MasterRpcServices::mergeTableRegions方法,从AssignmentManager查找对应regionInfo并调用HMaster::mergeRegions()方法,检查master已完成初始化且merge功能启用后提交NonceProcedureRunnable(关于Nonce的介绍见zhuanlan.zhihu.com/p/75734938)…
- MergeTableRegionsProcedure检查待合并的parent regions是否有重复,是否同table,是否相邻,是否重叠,是否主副本,是否online,集群和table状态是否可以merge。检查通过后排序regions并生成合并后region的RegionInfo(计算合并后的startKey,endKey,regionID取待合并regions最大值+1)
- 调用executeFromState,从MERGE_TABLE_REGIONS_PREPARE状态开始,检查table不能正在打snapshot,merge功能必须开启,如果region上有已merge标记需要成功清除并archive对应HDFS文件。具体逻辑是检查region的目录下是否有referenceFile,没有则提交GCMultipleMergedRegionsProcedure清理已merge的regions文件,并清理HMaster内存里对应的region信息。

GCMultipleMergedRegionsProcedure调用MetaTableAccessor.getMergeRegions检查hbase:meta表里该region的cells,过滤出column为"info:merge.*" regex格式的cell,从value解析RegionInfo,这些就是该region merge前的parent regions。
对父母region分别创建一个GCRegionProcedure,具体在GC_REGION_ARCHIVE状态下调用HFileArchiver.archiveRegion移动region文件到archive目录,如果archive目录下已存在同名文件,尝试加时间戳后缀重命名该文件,失败就删除之。move成功后删除region目录。
然后删除该region对应的WAL文件目录(存着seqid等文件),格式:rootDir/rootDir/rootDir/cluster/WALs/data/$namespace/table/regionName
然后删除AssignmentManager里该region的状态,再删除meta表里该region的info cf下所有信息。ServerManager::removeRegion清楚该region的两个seqID信息:
- The last flushed sequence id for a store in a region
- The last flushed sequence id for a region

再清理该region的FavoredNodes。
- 从meta表删除子region上对应"info:merge.*" regex格式的cq。至此完成清理父母regions里上次merge留下的元数据。
- 设置AssignmentManager里父母region的状态为MERGING
- 检查quota是否够,跳过正在执行的normalizer
- MERGE_TABLE_REGIONS_CLOSE_REGIONS 关闭父母regions
- MERGE_TABLE_REGIONS_CHECK_CLOSED_REGIONS 检查关闭都完成后
- MERGE_TABLE_REGIONS_CREATE_MERGED_REGION移除只读副本,创建merge出的新region。具体步骤:
- 在第一个父region目录下创建.merges临时目录
- 对父母regions的每个cf分别遍历所有storeFiles,每个storeFile分别创建referenceFile,文件名称格式:parentHFilenamebeforemerge.{parent_HFile_name_before_merge}.parentHFilenamebeforemerge.{parent_region_name} 文件内容统一指向原文件的startKey,等效于split里指向上半部分的referenceFile内容。
- commitMergedRegion将.merged临时目录下的内容move到合并后的子region目录下
- AssignmentManager创建新region的状态为MERGING_NEW
- MERGE_TABLE_REGIONS_WRITE_MAX_SEQUENCE_ID_FILE:从父母region的seqid里找到最大值,写入子region的seqid文件
- MERGE_TABLE_REGIONS_UPDATE_META:AssignmentManager将子region的状态设为MERGED, 将父母region删除,regionStateStore.mergeRegions方法原子地操作meta表,删除父母region,添加子region。子region的info cf下会写入父母regions的RegionInfo,cq分别是merge0000和merge0001 。子region状态为CLOSED防止过早被master调度拉起。 子region需要添加父母regions作为replication barrier,保证父母regions都完成同步再开始同步子region。
- 创建AssignProcedure打开子region

Merge过程也只是创建reference等compaction才移动数据,移动前读数据方式如下图:

当某些region数据量过小、碎片化,合并相邻region整合优化数据分布;
AssignmentManager创建MergeTableRegionsProcedure执行整合操作;
不搬迁实际数据,通过reference file 定位原region的文件,直到下次compaction时实际处理数据。
合并region时,只允许合并相邻的,否则会破坏rowkey空间连续且不重合的约定。
负载均衡
定期巡检各RegionServer.上的region数量,region的数量均匀分布在各个RegionServer上。
调度策略:
SimpleLoadBalancer具体步骤:
1.根据总region数量和RegionServer数量计算平均region数,设定弹性.上下界避免不必要的操作。
例如默认slop为0.2,平均region数为5,负载均衡的RS(regionserver)上region数量应该在[4,6]区间内。
2.将RegionServer按照region数量降序排序,对region数量超出上限的选取要迁出的region并按创建时间从新到老排序;
3.选取出region 数量低于下限的RegionServer列表,round-robin分配步骤2选取的regions,尽量使每个RS的region数量都不低于下限;
4.处理边界情况,无法满足所有RS的region数量都在合理范围内时,尽量保持region数量相近。


\
其它策略:
StochasticL oadBalancer
- 随机尝试不同的region放置策略,根据提供的costfunction计算不同策略的分值排名(0为最优策略,1为最差策略);
- cost计算将下列指标纳入统计 : region负载、表负载、数据本地性( 本地访问HDFS)、Memstore 大小、HFile 大小。
- 根据配置加权计算最终cost,选择最优方案进行负载均衡;D根据配置加权计算最终cost,选择最优方案进行负载均衡;
FavoredNodel oadBalancer
- 用于充分利用本地读写HDFS文件来优化读写性能。
- 每个region会指定优选的3个RegionServer地址,同时会告知HDFS在这些优选节点上放置该region的数据;
- 即使第一节点出现故障,HBase也可以将第二节点提升为第一节点,保证稳定的读时延;
客户端定位数据
直连HBase的客户端需要配置对应的Zookeeper信息来定位数据所在的RegionServer,具体包括zookeeper集群实例的地址列表和该hbase集群在zookeeper中对应的根路径。
直连客户端具体定位步骤如下:
- 客户端访问Zookeeper获取元信息表hbase:meta所在的regionserver地址;
- 客户端访问该regionserver查询要读/写的table的rowkey在哪个regionserver;
- 客户端访问存数据的regionserver进行读写。
通过Thrift协议访问HBase的客户端需要ThriftServer的地址,通过ThriftServer转发请求。可以通过Consul实现thriftserver的服务发现。

LSM tree
HBase将每个column family的数据独立管理,称为HStore。一个HStore包含一到多个物理文件块(称为HFile)存储到HDFS。实际存储时每个column family独立存储,一个column family对应多个HFile文件块。

每个HFile内的数据按rowkey有序存储,但HFile间没有顺序保证。这一特点是由于LSM的写入方式决定的。
LSM树的读写流程:
- 写入:写入操作先记录到Write-Ahead Log持久化(可选)保存,然后写入内存中的MemStore。WAL可以保证实例挂掉或重启后丢失的内存数据可以恢复。
- 读取:从写入逻辑可以看出HFile包含的rowkey范围会有交集,以全局rowkey顺序读取就需要以一种归并排序的形式组织所有HFile。HBase会打开该cf下所有HFile,分别构建一个迭代器用以rowkey从小到大扫对应HFile的数据。所有这些迭代器又以当前指向rowkey的大小组织成一个最小堆,这样堆顶的迭代器指向的rowkey就是下一个全局最小的rowkey。迭代该rowkey后重新调整最小堆即可。

\
Distributed Log Split原理
\
背景:
1.写入HBase的数据首先顺序持久化到Write Ahead-Log,然后写入内存态的MemStore即完成,不立即写盘,障会导致内存中的数据丢失,需要回放WAL来恢复;
2.同RegionServer的所有region复用WAL,因此不同region的数据交错穿插,RegionServer 故障后重新分配region前需要先按region维度拆分WAL。

\
实现原理:


1.RegionServer 故障,Zookeeper 检测到心跳超时或连接断开,删除对应的临时节点并通知监听该节点的客户端
2.active HMaster监听到RS临时节点删除事件,从HDFS梳理出该RS负责的WAL文件列表
3.HMaster为每个WAL文件发布一个log split task到ZK
4.其他在线的RS监听到新任务,分别认领
5.将WAL entries按region 拆分,分别写入HDFS . 上该region的recovered.edits目录
6.HMaster监听到logsplit任务完成,调度region到其他RS
7.RS打开region 前在HDFS找到先回放recovered.edits目录下的WAL文件将数据恢复到Memstore里,再打开region恢复读写服务。
完整流程:

\
进一步优化:
- HMaster 先将故障RegionServer . 上的所有region以Recovering状态调度分配到其他正常RS上;
- 再进行类似DistributedLogSplit的WAL日志按region维度切分;
- 切分后不写入HDFS,而是直接回放,通过SDK写流程将WAL记录写到对应的新RS;
- Recovering状态的region接受写请求但不提供读服务,直到WAL回放数据恢复完成。
课后
- 梳理回顾 HBase 的适用场景,并从架构设计、数据模型等方面解释为什么适用,以及对应场景的 rowkey 应该如何设计?
- 能否完整复述一遍 region split 和 region merge 的过程?
- Distributed log replay 解决了什么问题?是通过什么方式解决的?
- 以时间戳作为 rowkey 前缀会有什么问题?如何解决?
参考资料
- static.googleusercontent.com/media/resea… 介绍 Bigtable,经典的分布式宽表设计,HBase 很多设计借鉴了 Bigtable,可以看作其开源实现版本
- hbase.apache.org/book.html HBase 官方指南,权威全面地介绍 HBase。
- help.aliyun.com/document_de… 阿里云对 HBase 应用场景的整体介绍。
- cloud.tencent.com/developer/a… compaction 机制的简述 Blog。
- opentsdb.net/docs/build/… 介绍 OpenTSDB 在 HBase 上的数据模型设计
- hbasefly.com/category/hb… 详细易懂的 HBase 介绍系列文章,推荐阅读整个系列
- hbasefly.com/2017/08/27/… 介绍较早版本 HBase 依赖ZK的 region 切分的实现细节,来自上述系列文章
- hbasefly.com/2016/03/25/… HFile 具体格式介绍,同样出自上述系列文章
- cloud.tencent.com/developer/a… 详细介绍 HBase competition 和 split 实现
- www.jianshu.com/p/569106a30… 对 HBase 各个功能的快速介绍,可作为索引快速查询相关组件介绍
- www.jianshu.com/p/086c86fb8… 介绍 WAL split 实现的演进过程,以及解决了什么问题