ActiveMQ系列:基于LevelDB和 Zookeeper 的数据复制集群
前面有介绍与基础、应用实践部分,有兴趣的可以移步:
初步认识了ActiveMQ:https://blog.csdn.net/qq_26975307/article/details/98875098
结合JavaSE进行初尝试:https://blog.csdn.net/qq_26975307/article/details/98968854
详细讲讲JMS:https://blog.csdn.net/qq_26975307/article/details/99408962
JMS的可靠性:https://phubing.blog.csdn.net/article/details/99412285
结合 Spring,基于配置文件的使用 ActiveMQ:https://phubing.blog.csdn.net/article/details/99413883
结合 SpringBoot,基于 application.xml 使用ActiveMQ:https://blog.csdn.net/qq_26975307/article/details/99415899
ActiveMQ传输协议:https://blog.csdn.net/qq_26975307/article/details/100147542
ActiveMQ 的持久化机制:https://blog.csdn.net/qq_26975307/article/details/100161024
此篇开始 基于LevelDB和 Zookeeper 的数据复制集群,有兴趣可以留言共同探讨
1、如何保证 ActiveMQ 的高可用?
不重复写了:https://blog.csdn.net/liuxiao723846/article/details/78949900
2、本文中 ActiveMQ 的集群
1.基于 ZooKeeper 和 LevelDB 搭建ActiveMQ集群。
2.集群仅提供主备方式的高可用集群功能,避免单点故障。
有兴趣可以移步官网拜读:http://activemq.apache.org/persistence
3、ActiveMQ 的集群实现方式以及对比
有兴趣可以移步官网拜读:http://activemq.apache.org/masterslave.html
1、基于 sharedFileSystem 共享文件系统
2、基于JDBC
3、基于可复制的 LevelDB

最后一段话翻译下吧:
LeveDB 5.6版本之后推出了 LevelDB 的持久化引擎,它使用了自定义的索引代替常用的 BTree 索引,其持久化性能高于KahaDB,虽然默认的持久化方式还是 KahaDB,但是 LevelDB 可能会是趋势。
在5.9版本还提供了基于 LevelDB 和 Zookeeper 的数据复制方式,作为 Master-Slave 方式的首选数据复制方案。
4、ZK+Replicated LevelDB Store
1、sharedFileSystem
2、是什么
3、官网集群原理图
4、部署规划和步骤
5、集群可用性测试
4.1、sharedFileSystem
The following example shows how to configure a broker for Shared File System Master Slave where /sharedFileSystem is some directory on a shared file system.It is just a case of configuring a file based store to use a shared directory.
<persistenceAdapter> <kahaDB directory="/sharedFileSystem/sharedBrokerData"/> </persistenceAdapter>
OR
<persistenceAdapter> <1evelDB directory="/sharedFileSystem/sharedBrokerData"/> </persistenceAdapter>
4.2、ZK+Replicated LevelDB Store 是什么
从 ActiveMQ5.9 开始,ActiveMQ 的集群实现方式取消了传统的 Master-Slave 方式,增加了基于 ZooKeeper+LevelDB 的 Master-Slave 实现方式,从5.9版本后也是官网的推荐。
基于 ZooKeeper 和 LevelDB 搭建 ActiveMQ 集群。集群仅提供主备方式的高可用集群功能,避免单点故障。
4.3、集群原理 - 官网介绍
有兴趣可以移步官网拜读:http://activemq.apache.org/replicated-leveldb-store.html
以下摘自官网文档:
It uses Apache ZooKeeper to coordinate which node in the cluster becomes the master. The elected master broker node starts and accepts client connections. The other nodes go into slave mode and connect the the master and synchronize their persistent state /w it. The slave nodes do not accept client connections. All persistent operations are replicated to the connected slaves. If the master dies, the slaves with the latest update gets promoted to become the master. The failed node can then be brought back online and it will go into slave mode.
All messaging operations which require a sync to disk will wait for the update to be replicated to a quorum of the nodes before completing. So if you configure the store with replicas="3" then the quorum size is (3/2+1)=2. The master will store the update locally and wait for 1 other slave to store the update before reporting success. Another way to think about it is that store will do synchronous replication to a quorum of the replication nodes and asynchronous replication replication to any additional nodes.
When a new master is elected, you also need at least a quorum of nodes online to be able to find a node with the lastest updates. The node with the lastest updates will become the new master. Therefore, it’s recommend that you run with at least 3 replica nodes so that you can take one down without suffering a service outage.
我的理解:
1、使用 ZooKeeper 集群注册所有的 ActiveMQ Broker 但只有其中的一个 Broker 可以提供服务它将被视为 Master,其他的Broker 处于待机状态被视为 Slave。
2、如果Master 因故障而不能提供服务ZooKeeper会从Slave中选举出一个Broker充当Master。
3、Slave 连接 Master 并同步他们的存储状态,Slave 不接受客户端连接。所有的存储操作都将被复制到连接至 Master 的Slaves。
4、如果 Master 宕机得到了最新更新的 Slave 会成为 Master。故障节点在恢复后会重新加入到集群中并连接 Master 进入Slave模式。
5、所有需要同步的消息操作都将等待存储状态被复制到其他法定节点的操作完成才能完成。
6、所以,如果你配置了 replicas = 3,那么法定大小是(3/2)+ 1 = 2。Master 将会存储并更新然后等待(2-1)= 1个 Slave 存储和更新完成,才汇报 success,至于为什么是 2 - 1 ?
7、有一个 node 要作为观擦者存在。当一个新的 Master 被选中,你需要至少保障一个法定 node 在线以能够找到拥有最新状态的 node。这个 node 才可以成为新的 Master。
8、因此,推荐运行至少 3 个 replica nodes 以防止一个 node 失败后服务中断。
为什么是 2 - 1
结合 watch 机制和集群算法还有原子广播 ZAB 协议就可以知道,有一个 node 要作为观察者存在,当一个新的 master 被选中至少要保证一个法定的 node 在线,以能够找到拥有最新状态的 node,这个 node 才可以成为新的 Master。
选举步骤
一主二从;
选举观察者;
所有的client只认master,内部一主二从数据复制之后可以共享
master挂了,观察者发心跳之后没回应,按照选举机制,将会在剩下的丛机中选出master
5、部署规划和步骤
1.环境和版本
1.1、CentOS 7.4 x64
1.2、JDK 1.8.0_201
1.3、zookeeper-3.4.9
1.4、apache-activemq-5.15.9
2.关闭防火墙并保证 win 可以 ping 通过 ActimveMQ 服务器
3.要求具备zK集群并可以成功启动
4.集群部署规划列表
5.创建3台集群目录
6.修改管理控制台端口
7.hostname 名字映射
8.AcitveMQ 集群配置
9.修改各节点的消息端口
10.按顺序启动3个ActiveMQ节点-到这步前提是zk集群已经成功启动运行
11.zk集群的节点状态说明
(系列文章不是写zookeeper的,可自行参考其他文章进行搭建ZK,以下步骤请在ZK可用情况下进行)
5.1、集群部署规划列表

5.2、创建3台集群目录
mkdir /mq_cluster/ cd /mq_cluster/ cp -r /opt/apache-activemq-5.15.9 mq_node01 cp -r mq_node01 mq_node02 cp -r mq_node02 mq_node03
最终结果:

5.3、修改管理控制台端口
1、mq_node01 保持默认
2、
cd mq_cluster/mq_node02/conf vim jetty.xml
第 110 行左右
<bean id="jettyPort" class="org.apache.activemq.web.WebConsolePort" init-method="start"> <!-- the default port number for the web console --> <property name="host" value="0.0.0.0"/> <property name="port" value="8162"/> </bean>
3、mq_node03 同 mq_node02 修改
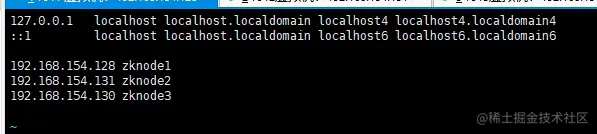
5.4、修改hosts
vim /etc/hosts
(按机器实际环境配置,不是一定要叫这个名字!!!)
192.168.111.136 zzyymq-server
5.5、3个节点的持久化配置
注:三个节点均在 conf文件夹下配置文件进行修改(3个节点的BrokerName要求全部一致)
<broker xmlns="http://activemg.apache.org/schema/core" brokerName="localhost" dataDirectory="${activemq.data}">
官网推荐配置:
http://activemq.apache.org/replicated-leveldb-store
You should run at least 3 ZooKeeper server nodes so that the ZooKeeper service is highly available. Don’t overcommit your ZooKeeper servers. An overworked ZooKeeper might start thinking live replication nodes have gone offline due to delays in processing their ‘keep-alive’ messages.
For best results, make sure you explicitly configure the hostname attribute with a hostname or ip address for the node that other cluster members to access the machine with. The automatically determined hostname is not always accessible by the other cluster members and results in slaves not being able to establish a replication session with the master.
配置之前,记得把之前的持久化配置注释啊,有空多拜读官网,才是王道。
节点1:
<persistenceAdapter> <replicatedLevelDB directory="${activemq.data}/leveldb" replicas="3" bind="tcp://0.0.0.0:63631" zkAddress="localhost:2191,localhost:2192,localhost:2193" hostname="zzyymq-server" sync="local_disk" zkPath="/activemq/leveldb-stores"/> /persistenceAdapter>
节点2:
<persistenceAdapter> <replicatedLevelDB directory="${activemq.data}/leveldb" replicas="3" bind="tcp://0.0.0.0:63632" zkAddress="localhost:2191,localhost:2192,localhost:2193" hostname="zzyymq-server" sync="local_disk" zkPath="/activemq/leveldb-stores"/> /persistenceAdapter>
节点3:
<persistenceAdapter> <replicatedLevelDB directory="${activemq.data}/leveldb" replicas="3" bind="tcp://0.0.0.0:63633" zkAddress="localhost:2191,localhost:2192,localhost:2193" hostname="zzyymq-server" sync="local_disk" zkPath="/activemq/leveldb-stores"/> /persistenceAdapter>
5.6、修改各个节点的消息端口
<transportConnectors> <transportConnector name="openwire" uri="tcp://0.0.0.0:61617?maximumConnections=1000&wireFormat.maxFramesize=104857600"> ... </transportConnectors>
其他两个端口同理
5.7、按顺序启动3个 ActiveMQ节点(到这步前提是zk集群已经成功启动运行)
阿西吧,一个一个启动太烦了,写个批处理脚本吧
vim amp_batch.sh
#! /bin/sh cd /myzookeeper/zk01/bin ./zkServer.sh start cd /myzookeeper/zk02/bin ./zkServer.sh start cd /myzookeeper/zk03/bin ./zkServer.sh start
启动完了,看看状态:
ps -ef | grep zokeeper | grep -v greplwc -l
5.8、任意连接一台ZK看看
./zkCli.sh -server 127.0.0.1: 2191

集群启动后对ZooKeeper数据的抓图,可以看到ActiveMQ的有3个节点,分别是00000000000,00000000001,00000000002,
再继续分别 GET 一下看看
get/activemg/leveldb-stores/00000000000
可以看到 elected 的值是不为空,说明这个节点是 Master,其他两个节点是 Slave。
6、LevelDB 集群可用性测试
ActiveMQ 的客户端只能访问 Master 的 Broker,其他处于 Slave 的 Broker 不能访问,所以客户端连接的 Broker 应该使用 failover 协议(失败转移)
当一个 ActiveMQ 节点挂掉或者一个 Zookeeper 节点挂掉,ActiveMQ 服务依然正常运转,如果仅剩一个 ActiveMQ 节点,由于不能选举 Master,所以 ActiveMQ 不能正常运行;
同样的,如果 Zookeeper 仅剩一个节点活动,不管 ActiveMQ 各节点存活,ActiveMQ 也不能正常提供服务。( ActiveMQ 集群的高可用,依赖于 Zookeeper 集群的高可用)
6.1、使用 losf -i:8161 ,losf -i:8162,losf -i:8161 查看监听程序
结果显示,能访问监听的只有主机,也即 Master 。
lsof -i:8161
6.2、ActiveMQ 主面板查看 Broker

6.3、代码测试
生产者与消费者均修改 ActiveMQ 连接方式即可
public static final String ACTIVEMO_ URL= "failover:(tcp://192.168.111.136:61616,tcp://192.168.111.136:61617,tcp://192.168.111.136:61618)?randomize=false"); public static final String QUEUE_NAME="queue-cluster";
测试:
3台机器中的 ActiveMQ 只会有一个 MQ 可以被客户端连接使用,在测试时可以把 Master 关掉,然后在重试客户端消息发送和消费还可以正常使用,则说明集群搭建正常。
假如现在:http://192.168.111.136:8163/ 可以正常访问,说明这台是 master
如果你把Master 关了,无法正常发送接收消息,请检查是否配置正确
OK,就这样。
(未完待续......下篇开始 高级特性之异步投递、延时投递与定时投递 )